It’s deleted, maybe because you didn’t put the appropriate tag? (see sidebar of the subreddit)
1 Like
Oops, thanks! Will fix later today.
Sure! The dataset is composed of roughly 30 contrast enhanced CT scans where each chamber has been human annotated, stored in this case in h5 files. The scans themselves vary a lot, first the pixel intensities are different for each scanner, and need to be converted to Houndsfield units using metainformation stored in the DICOM. The number of pixel is another problem. They will typically have different numbers of pixels and each will be at a different spacing. Medical imaging is like taking microtome slices down a person from head to toe. When you set the parameters for the scanner, you can set the resolution of each slice (in all three directions) and how many slices to take. More slices usually means more scan time. So people usually space their slices more, so if you were to look at the scan stake into the coronal plane, the scan would be less well resolved, or even squished if you plotted it in matplotlib. This might not normally be a problem if it i were consistent, but it isn’t consistent between scans. And if I ignore this problem, it makes my models take longer to converge, and reduce their quality, and it gets tripped up on new data that is sized differently. So prior to training I go through resizing everything the 3D tensor to be a consistent, say 1x1x1mm voxel sizing.
Another thing is Houndsfield clipping. Hounds field units range from like -1000 to tens of thousands if you have metal around. Eventually this needs to be converted to your standard 0-255 intensities before image normalization, so if you keep that it will put all your useful information in a very narrow tissue range. So best thing to do is just clip it between some set units of interest. That way a pacing lead can’t show up and throw off your scale by a bunch.
This is gray scale, but I just save everything as pngs so it winds up being RGB anyway so I have three channel to work with when I send them back to the network. Otherwise it’s just normal transformations (without horizontal flip) and a normal training schedule, although it’s a lot of data so each epoch takes a while, so I’ve been doing less epochs, max 5 so I can keep prototyping.
Model is just a resnet34 unet! It trains on a regular 2080 GPU over the span of a few hours. So the results you see are just about the fastest, worst results you can get. All the work is in the data in the data preprocessing, as is tradition.
4 Likes
In this case yes! 2D slices being combed from looking through all planes. I’ve tried working with 3D convolutional networks without much success, my batch size is always too small and it doesn’t converge well. This is a while ago though so maybe Jeremey’s new batch norm would fix this problem. Some people have luck with 3D convolutions, but I’ve only heard of that working for bone segmentation, and bone segmentation you don’t even need a network it’s just a thresholding, so that’s probably why it works.
My logic on the 2D approach is that it is kind of how I segment anatomy myself. Most interfaces give you all 3 planes to look at and you can combine your confidence on each to get a good idea on what each pixel should be. (Although it can be really difficult with complex anatomy…) Adding more interslice information would probably work better. One thing I’d like to try in the future is changing the RGB channels to be 3 adjacent slices. To have just a bit more depth context for each voxel.
1 Like
Hi Poonam, I enjoyed reading your post. It was helpful for me how you dove into the math and step-by-step explained the derivation of the variance/expected value properties behind Kaiming He’s derivation of their weight init formula. I also particularly found helpful your point on ReLUs enabling networks to have sparse representations ー for some reason I’d never explicitly thought of it in this way before.
I noticed that when describing Glorot’s vanishing gradients graph, you mentioned that “…till layer 5 all the gradients have vanished…,” while the graph seems to indicate that at layer 5 (final layer) the gradients have a wider distribution, and at layer 1 (first layer in the network) the backpropagated gradients are mostly vanished (they are tightly distributed near zero):
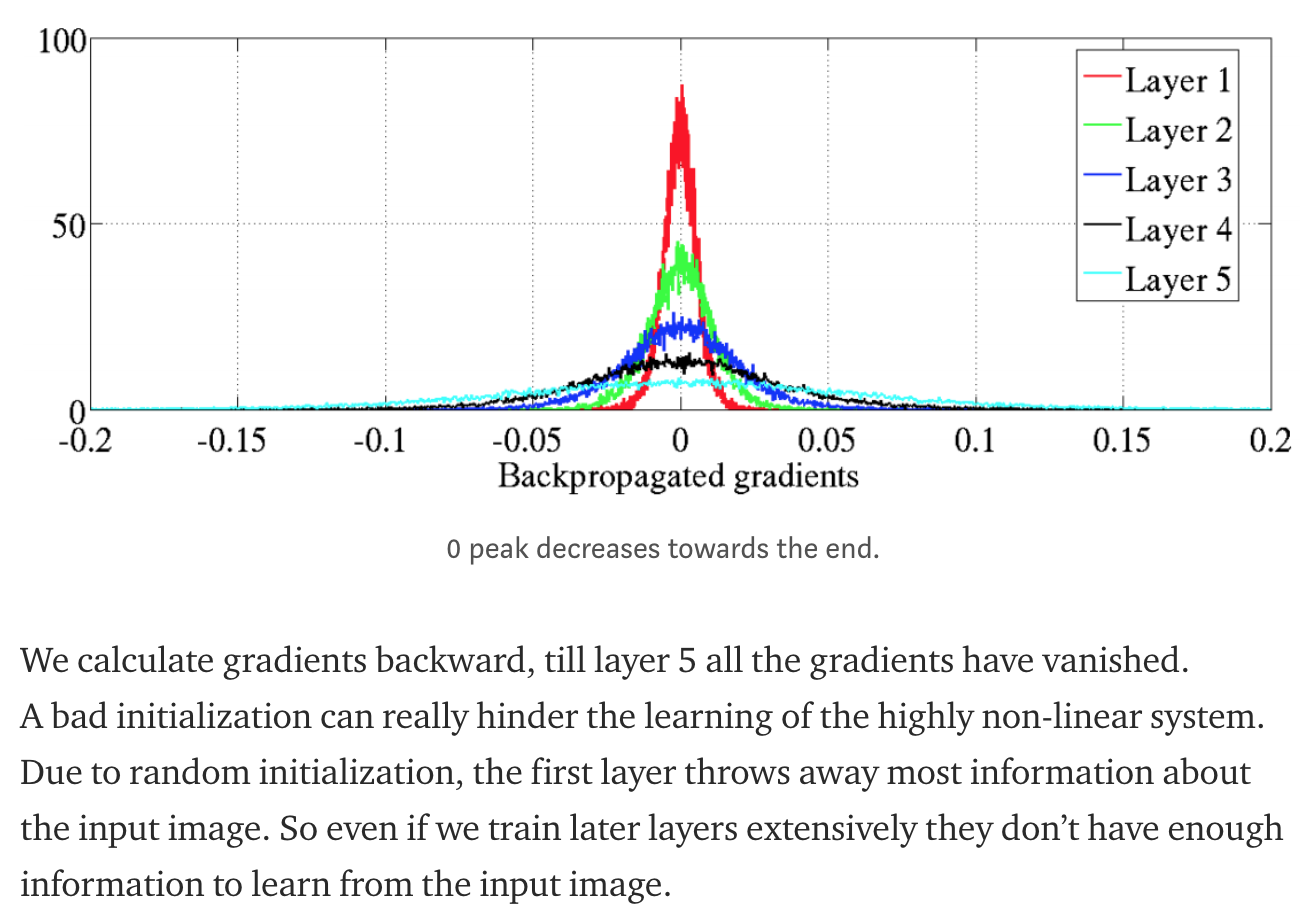
The reason I ask is cause the hardest part of the Glorot paper for me was trying to keep track of whether Glorot and Bengio count layers starting from the network’s beginning (where the input layer is “layer 1”), or do they start counting from the final output layer (in which case the input layer would be “layer 5”)? I think the first approach was what they did.
At any rate, the main feedback I have is something I am also trying to encourage myself to keep doing: please boldly continue to write blog posts and compose tweets 
3 Likes
very cool! congrats
1 Like
Thanks James for noticing. Yes, input layer is layer 1 and I should have said till layer 1(backward calculation from layer 5 to input layer 1) the gradients have almost vanished. The legend in the graph says it all. I have updated my blog.
1 Like
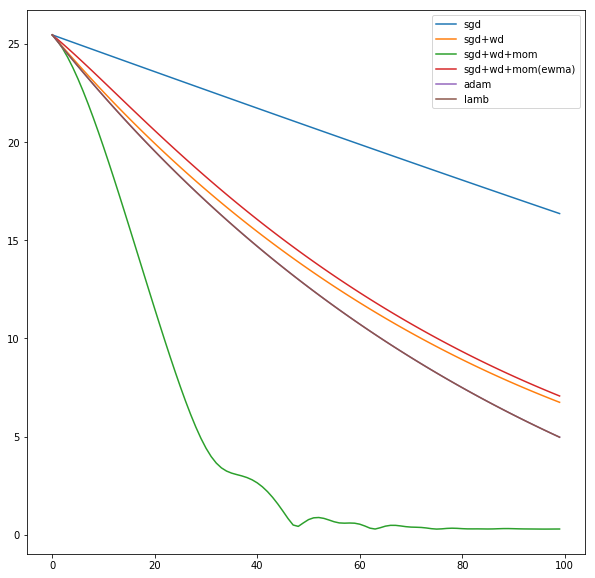
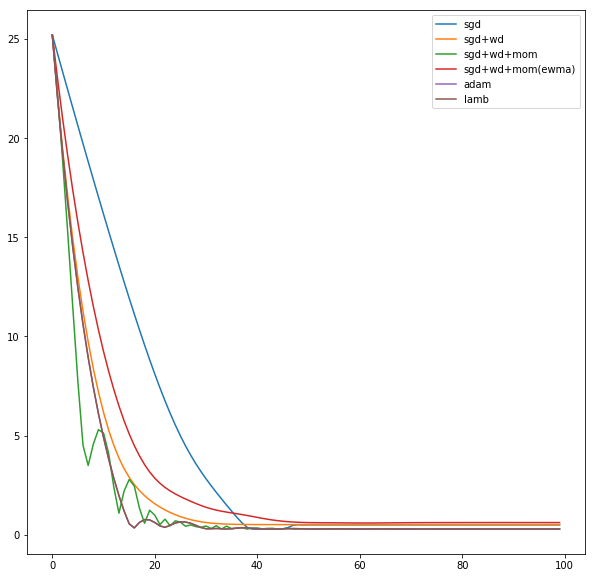
I finally managed to work on something, it is been tough keeping up with this part 2 course. Anyway, I tried to reuse as much of the optimizers notebook to try visualizing them on a sample linear regression problem and comparing the different variations.
Astonishingly SGD+WD+MOM had better convergence
This is an animation of the convergence for SGD+WD+MOM
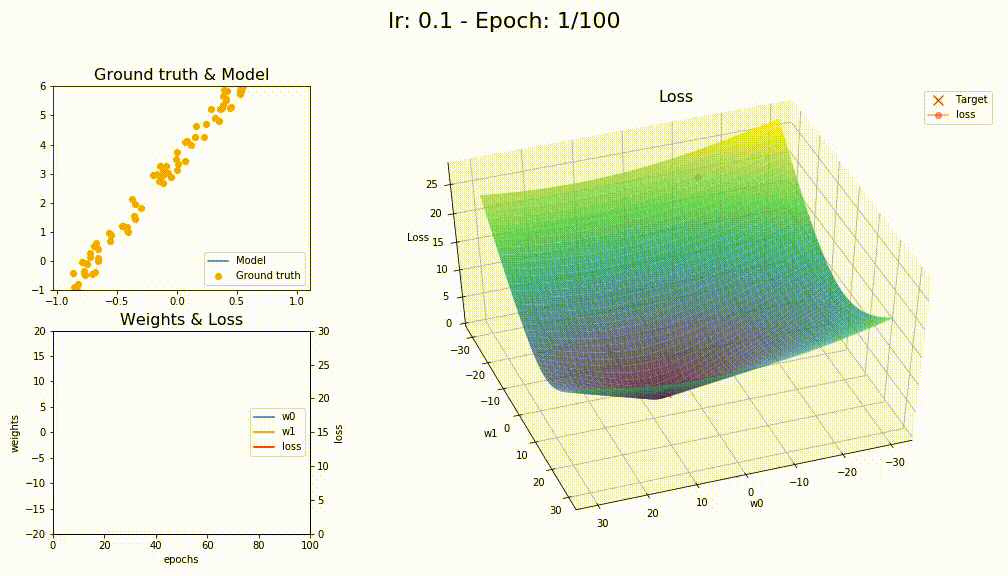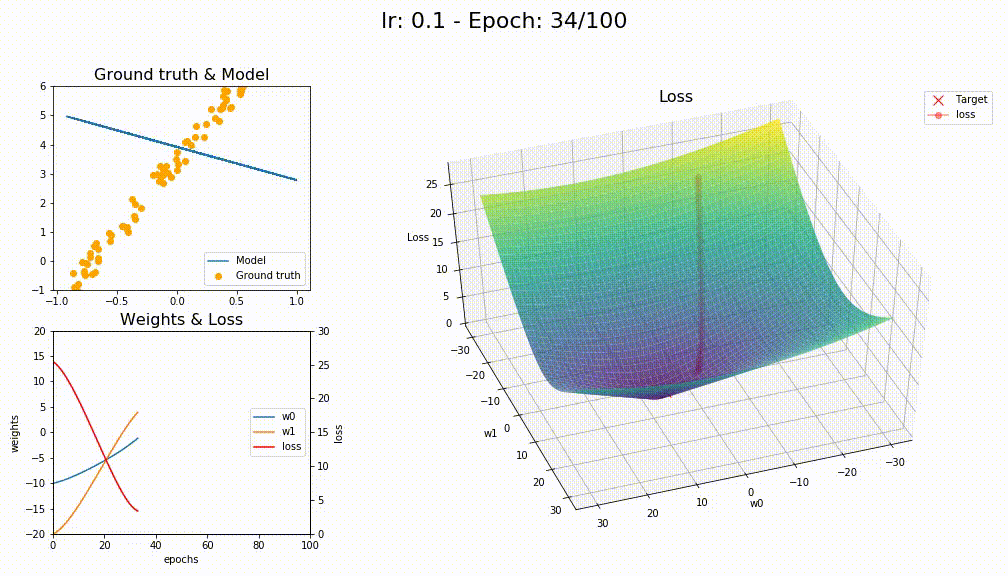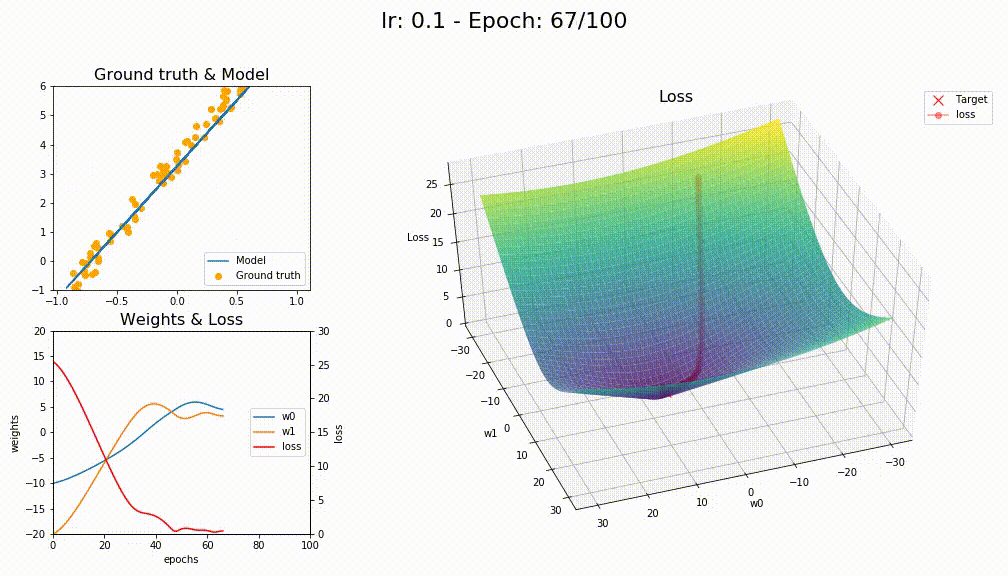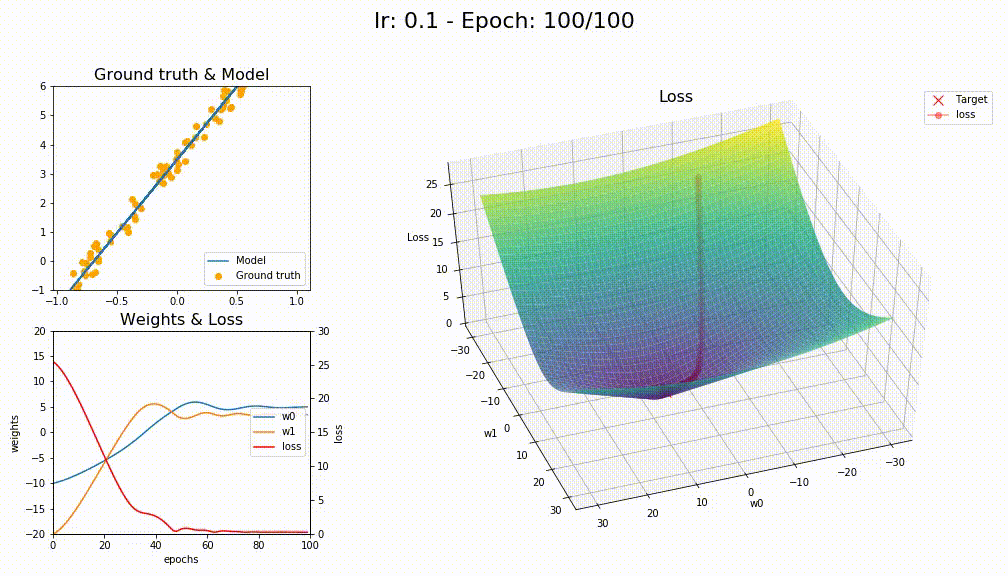
This is for LAMB
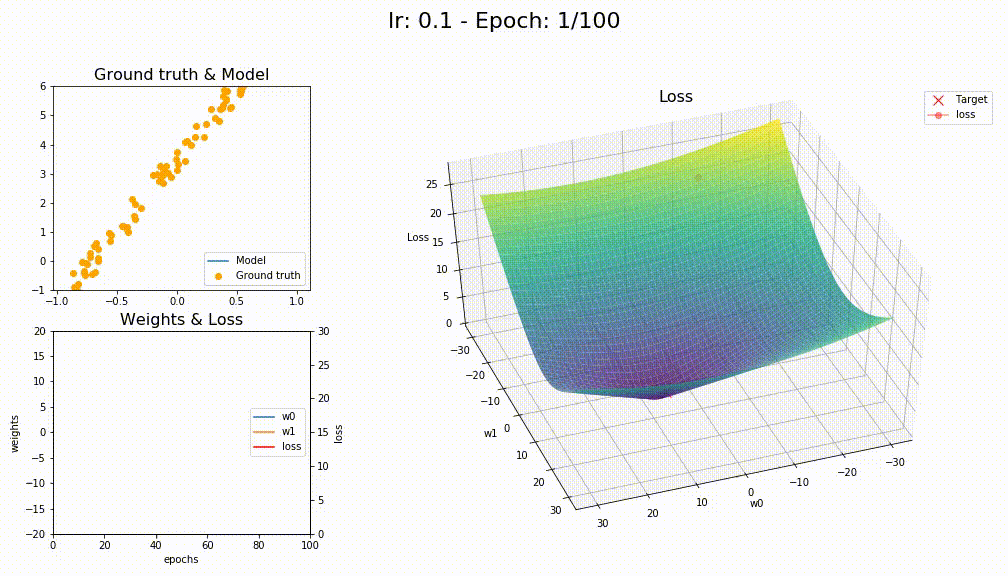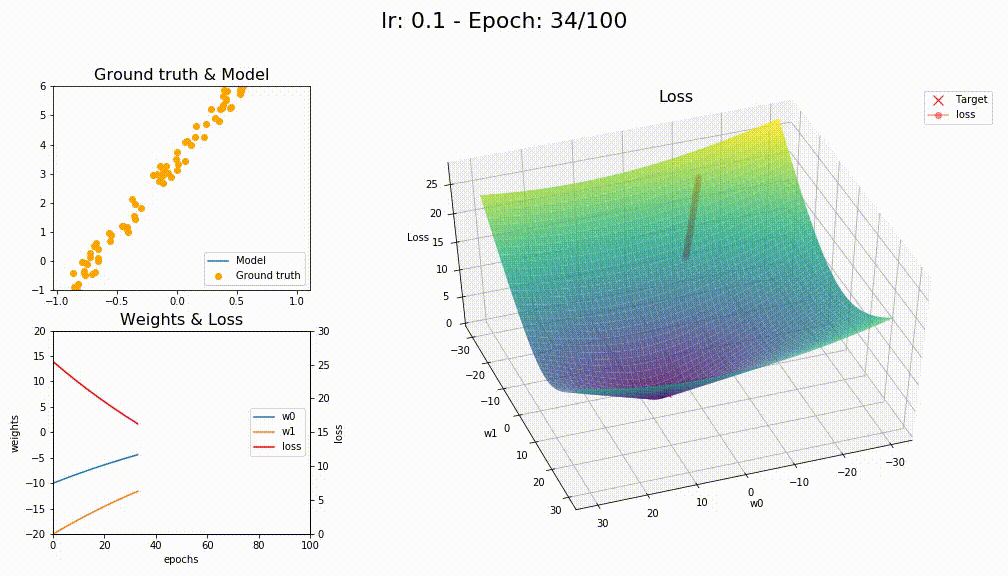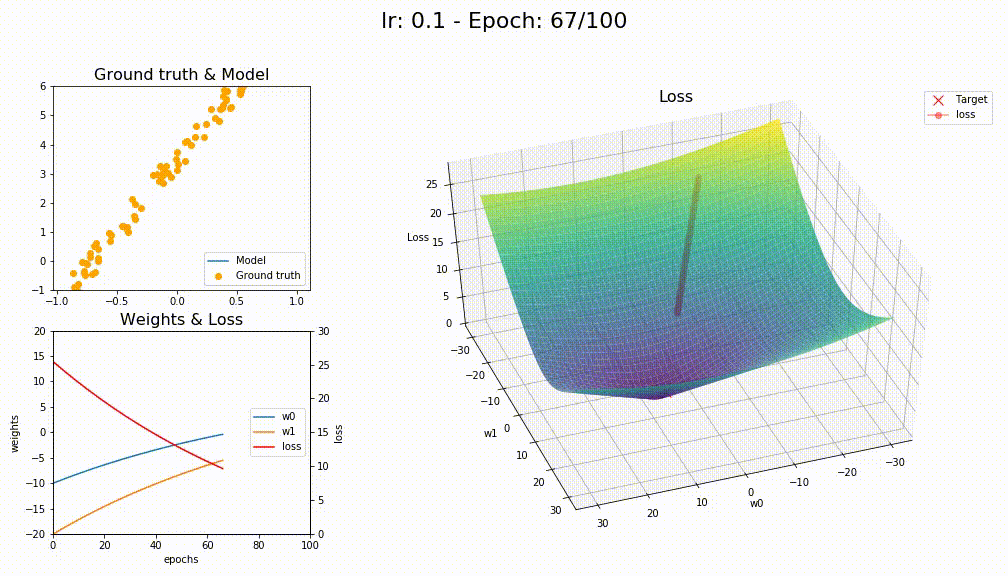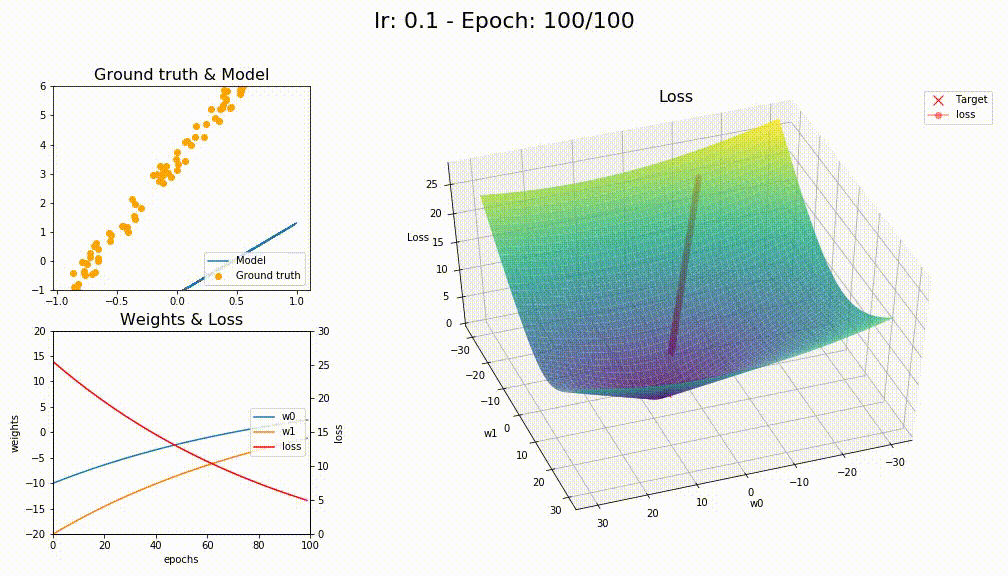
I bet I did something wrong with those optimizers, reading the notebooks is not trivial 
7 Likes
Did you use the same learning rate for each optimizer? It’s likely that different optimizers have a different optimum learning rate.
Oh interesting! but what tells you that @KarlH? I used same lr=0.1 and same code as 09_optimizers.ipynb notebook where I don’t see any special handling for any of the different optimizers!
Hey, I wrote this short Medium post talking about Optional Types and Unwrapped Optional types in the Swift Language. The concept is easy to grasp, especially if you have worked with JS promises, etc., but once you master it is a pretty useful (if not essential) tool to have.
1 Like
Well why would we expect different optimization functions to respond equivalently to the same learning rate?
Every update step has the form of learning_rate * gradient_term. The difference between optimizers is in how they structure the gradient term. If for example two different optimization functions have the same gradient direction but the magnitudes of their gradient terms differ by say 10x, the distance of the update step will similarly differ by 10x.
You can see this in the two plots in your post. Both the SGD plot and the LAMB plot move towards the minima, but the space between points on the SGD plot is greater than on the LAMB plot. Is this because LAMB is a worse optimizer, or because the LAMB optimization function requires a higher learning rate than SGD?
1 Like
I think you’re right @KarlH, I tried with lr=1 and this is the losses
This is how SGD+WD+MOM converge (like a crazy)
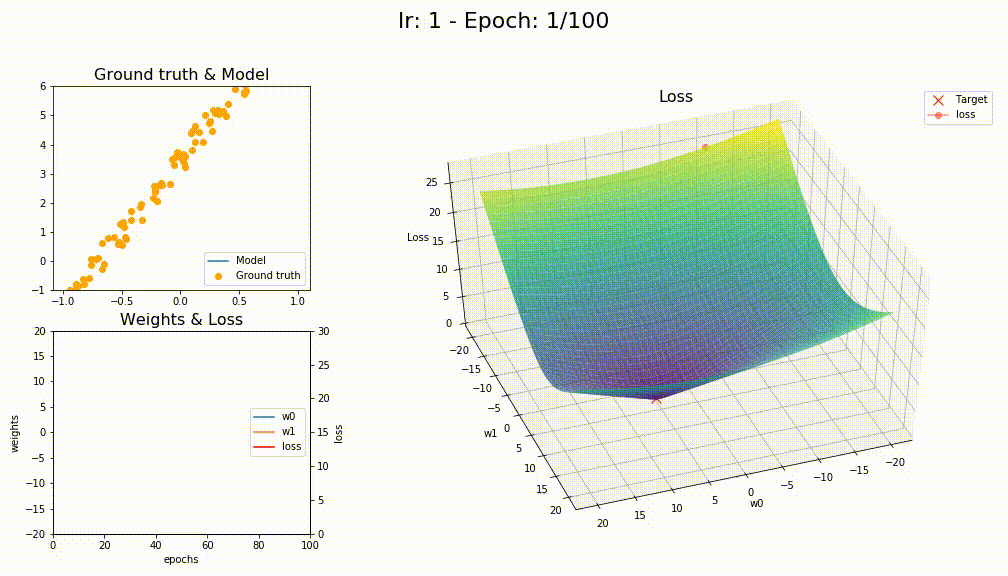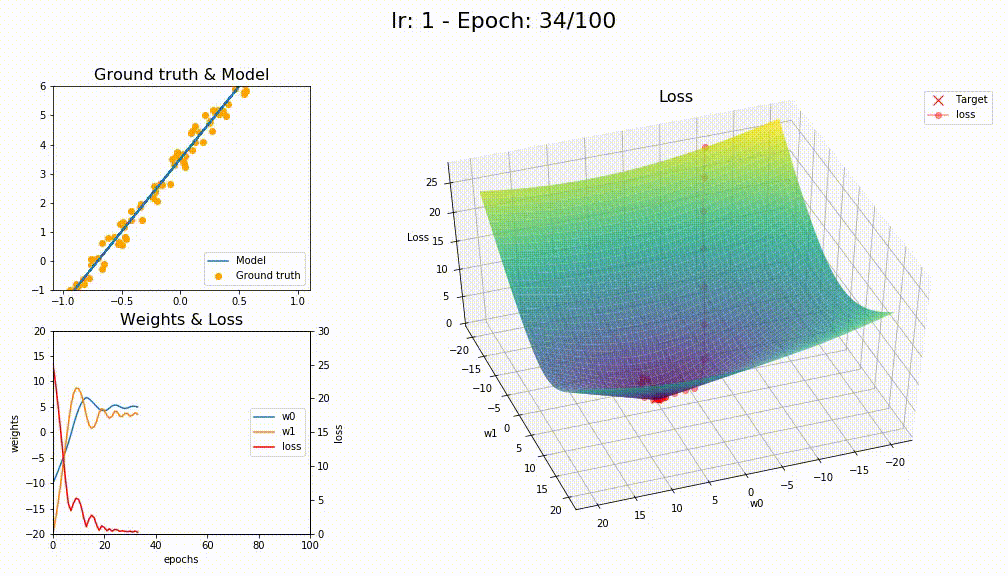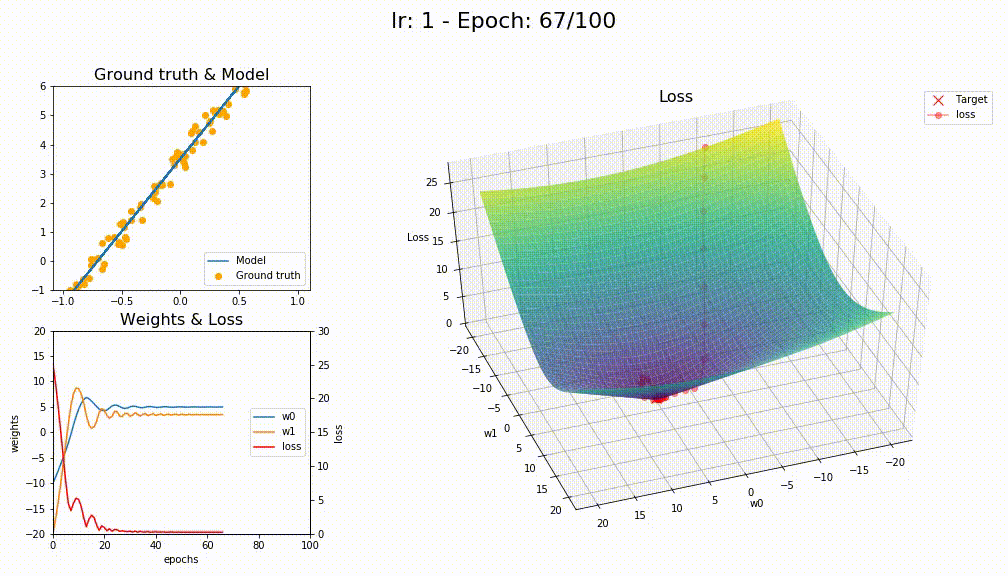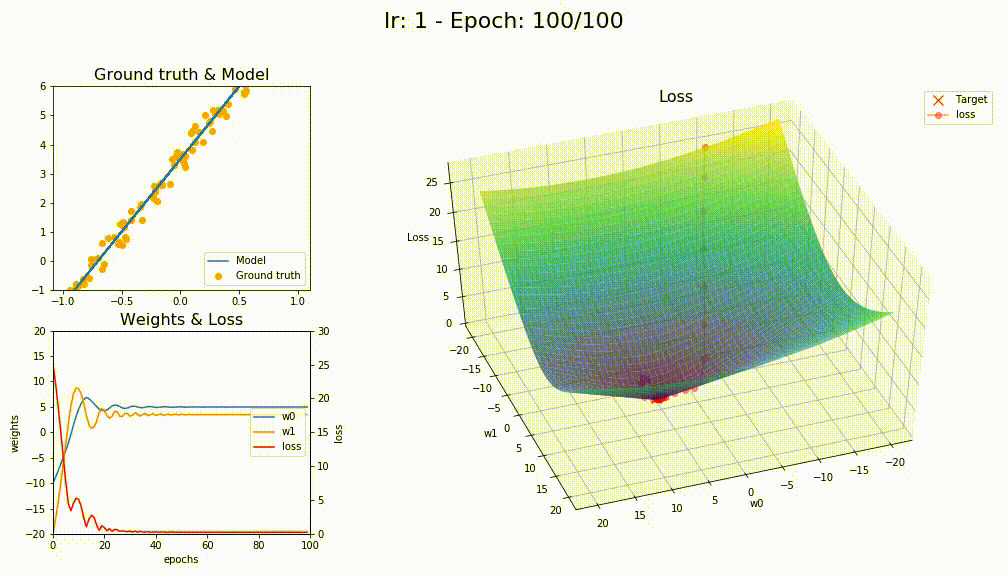
This is how LAMB converge (way smoother)
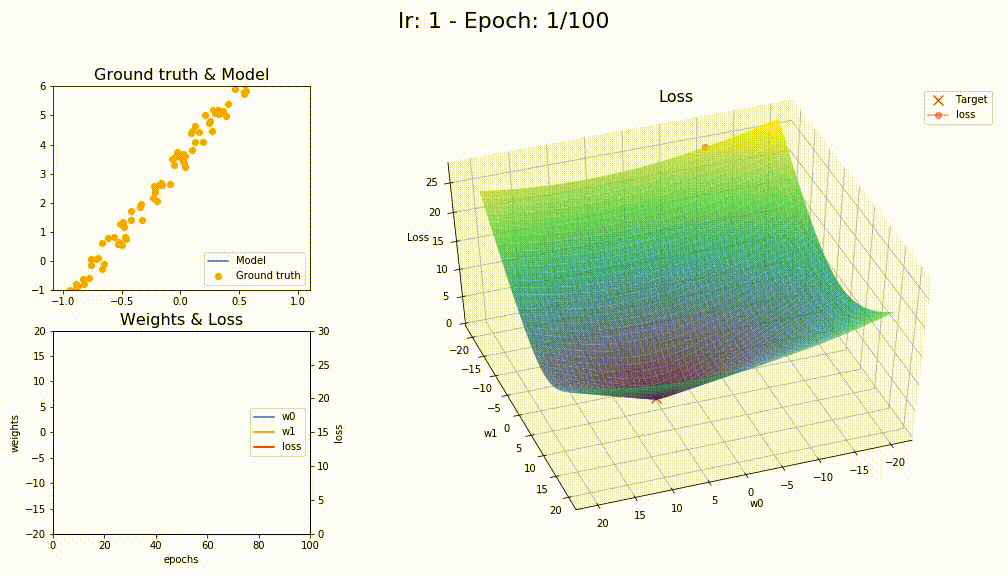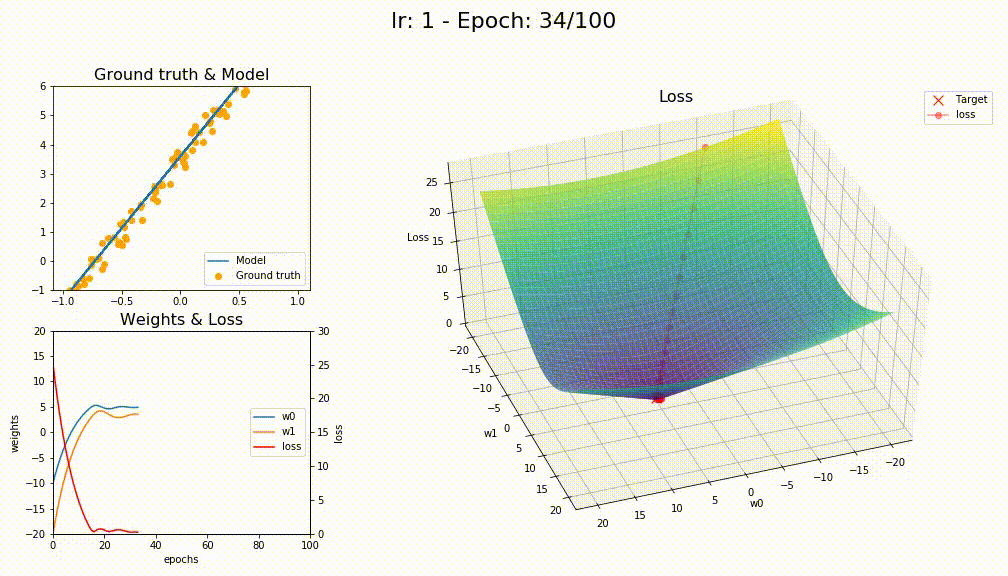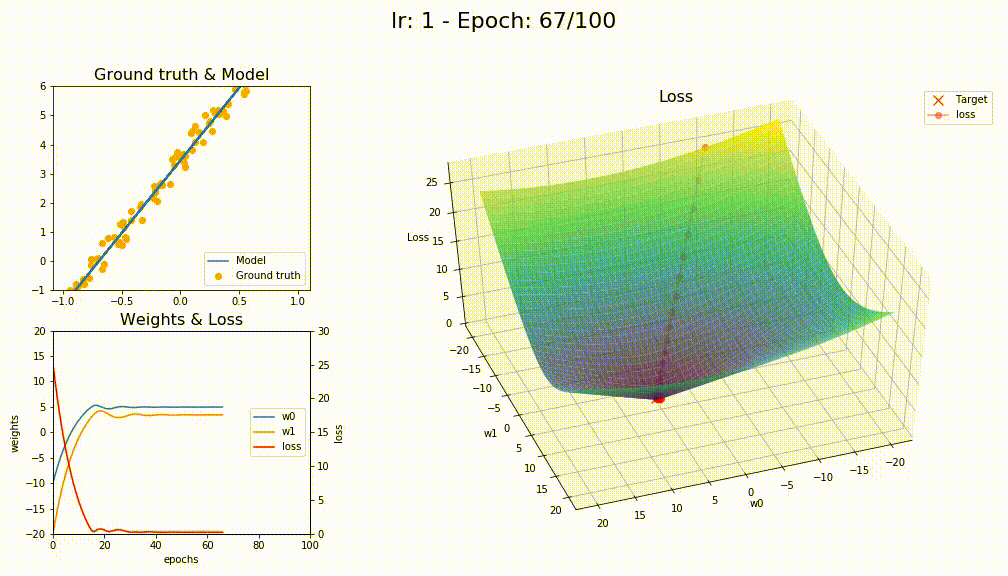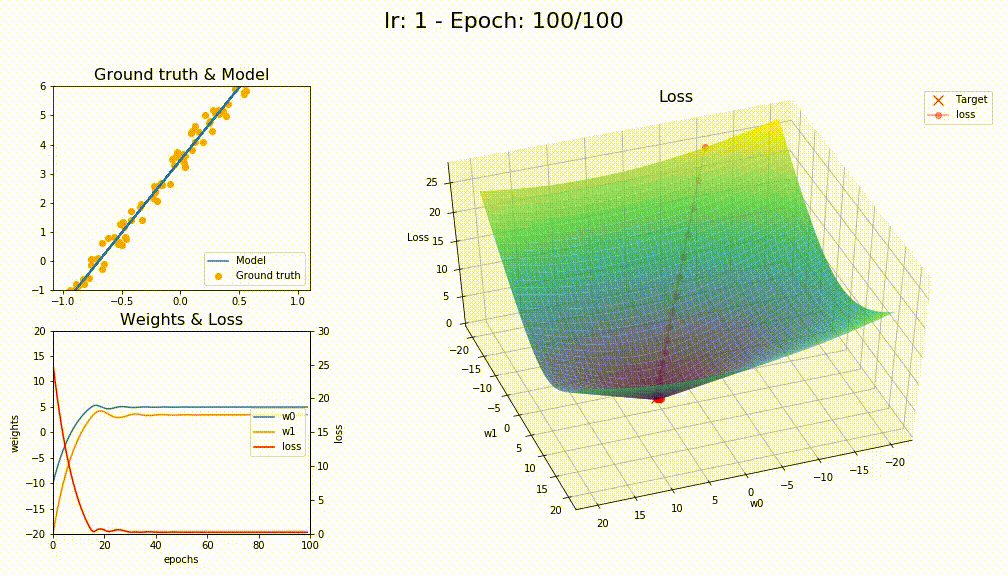
5 Likes
The AI Ethics landscape is large, complex and emerging. I am unpacking all its dimensions over 3 posts. Sharing part 1 (Also on Twitter):
The Hitchhiker’s guide to AI Ethics
I look forward to feedback from the Fast.ai community!
2 Likes
I made a new blog post on using the bigger (345M) gpt-2 model for generating conversations (trained mainly on my facebook messenger).
With code and working Colab.
6 Likes
Hey, I wrote this short Medium post talking about the mixup paper. It is intended to be an explanation of the section 2 of the paper.
2 Likes
Hey, wanted to share this Medium post that is step by step tutorial on how to create a simple classifier for MNIST in S4TF.
2 Likes
Sorry for not posting for many a days, was busy with college work. It feels great to announce that I got selected in Google Summer of Code 2019, where I will be using methods like GradCAM (using fastai of course  ) to extract features from Artworks and Sculpture (not as cool as @PierreO 's 3D Mask RCNN though). 6-8 months ago, I wouldn’t even have the confidence to pull this off.A huge thanks to Jeremy, Rachel, Sylvain and the community.
) to extract features from Artworks and Sculpture (not as cool as @PierreO 's 3D Mask RCNN though). 6-8 months ago, I wouldn’t even have the confidence to pull this off.A huge thanks to Jeremy, Rachel, Sylvain and the community.
https://summerofcode.withgoogle.com/projects/#5067547718713344
15 Likes
Congrats!
1 Like
Hey Swagato, congrats! Very cool project also!
I guess I can explain why you tagged me: I was also selected in Google Summer of Code 2019 to work on implementing a 3D version of Mask RCNN for Object Detection. The application is in high-energy physics for the CERN laboratory.
Same as Swagato, I wouldn’t have dreamed about this before fastai. This is an amazing course.
4 Likes