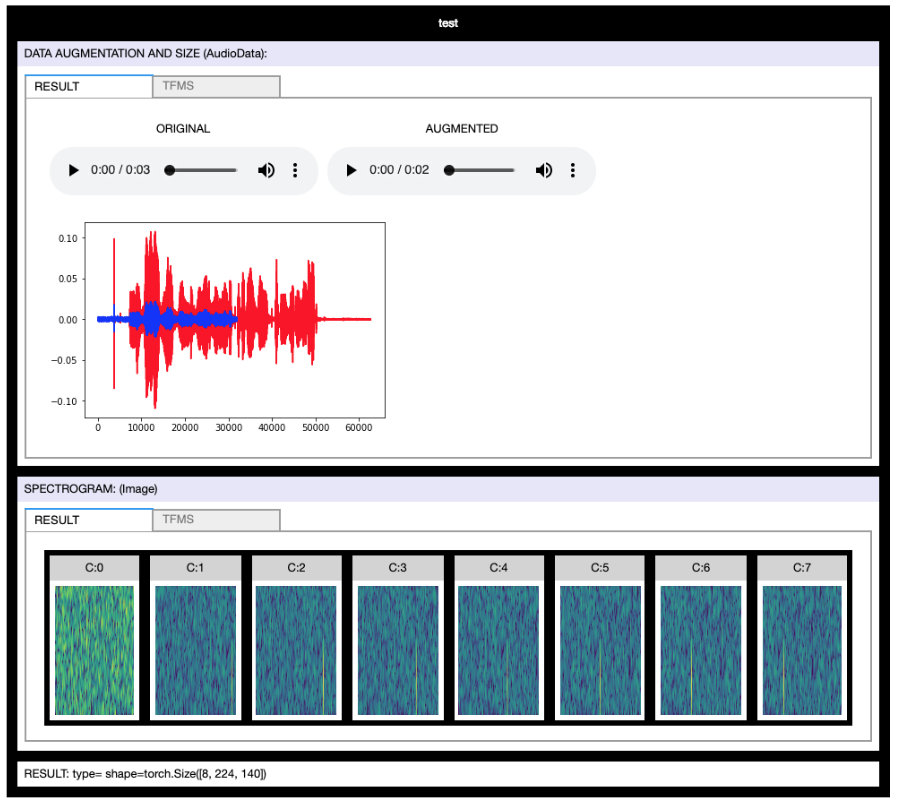
I’ve published a tool to quick visualize and tune a complex chain of data transforms (Audio & Image).