What is that
TfmsManager is an easy to use tool that helps you tune and debug complex groups and chains of transformations.
It comes with a two use cases for Image and Audio transformation.
IMPORTANT: you can preview your transformation before creating a “data bunch”, having only some samples (Image or Audio data).
Features
- Preview: see the extent of modifications made by your transform.
- Diff: visually compare your original data with transformed one.
- tfms: the “TFMS” tab shows you the exact list of transformation applied on each step.
- Shape: see the shape of resulting tensor.
Integration with fast.ai
Integrating the TfmsManager into fast.ai DataBlock is very easy: you need only to call tm.get_tfms() and pass the resulting tfms array to your transform step (where tm is a TfmsManager).
.transform(tm.get_tfms())
# Simple integration with DataBlock api
data = (AudioList.from_df(src, path, cols=['SampleAndSr'])
.split_from_df('is_valid')
.label_from_df('WRD', classes=classes)
.transform(tm.get_tfms())
.databunch(bs=64)) # NOTE:
Image
The following code shows you how to preview all the tansformations you’ve choosen, having instant feedback from the new parateters without
#Show all results
tfms = get_transforms(
do_flip = False,
flip_vert = False,
max_rotate = 1,
max_zoom = 1.0
)
tm=ImageTfmsManager.get_from_default_tfms(tfms)
tm.try_train_tfms(image,'Sample with single RGB',repeats=4);

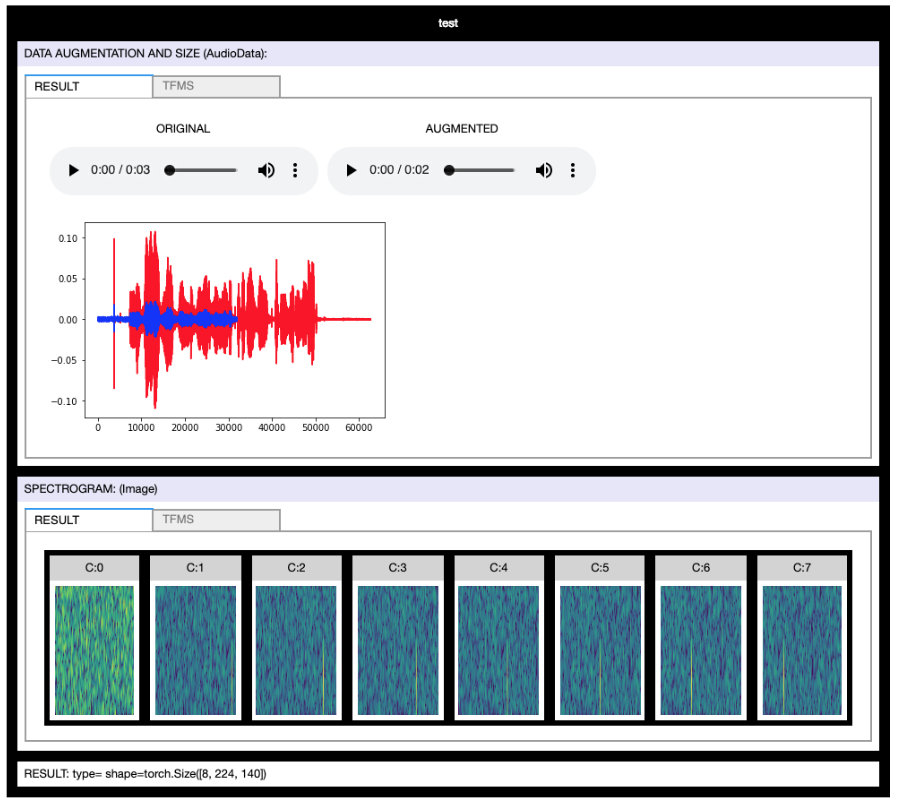
Audio
The following (advanced) example shows you how to preview a custom multi-spectrogram transform.
tm=AudioTfmsManager.get_audio_tfms_manager(
spectro=True, n_mels=256, ws=300, n_fft=3200, to_db_scale=True,
white_noise=True, noise_scl=.0052,
modulate_volume=True,
random_cutout=True,
pad_with_silence=False,
pitch_warp=False,
down_and_up=False,
mx_to_pad=32000)
#Replace the spectrogram transform with tfm_spectro_stft
filan_spec_tfm = partial(tfm_multiSpectrumSlide, max_duration=1000, n_windows=8)
tm.train_tfmsg[-1]=[filan_spec_tfm]
tm.valid_tfmsg[-1]=[filan_spec_tfm]
#Try!
yOut = tm.try_train_tfms(sampleSound,'test')
yOut.shape
Source code and complete examples
AUDIO: fastai-audio/AudioTransformsManager.ipynb at master · zcaceres/fastai-audio · GitHub
IMAGE: fastai-audio/ImageTransformsManager.ipynb at master · zcaceres/fastai-audio · GitHub
MULTI SPEC.: fastai-audio/example_multi_spectrogram_classificaiton_phoneme-sliding.ipynb at master · zcaceres/fastai-audio · GitHub

