Thanks, that is very helpful! So that means that depending on the method used for loading the data into the ItemList, it is stored in different format/data types? That’s not something I would have thought of…
3 Likes
Ok, I’ve written a custom training loop that looks like this:
def train(model, opt, phases, callbacks, epochs, device, loss_fn):
model.to(device)
cb = callbacks
cb.training_started(phases=phases, optimizer=opt)
for epoch in range(1, epochs + 1):
cb.epoch_started(epoch=epoch)
for phase in phases:
n = len(phase.loader)
cb.phase_started(phase=phase, total_batches=n)
is_training = phase.grad
model.train(is_training)
for batch in phase.loader:
phase.batch_index += 1
cb.batch_started(phase=phase, total_batches=n)
x, y = place_and_unwrap(batch, device)
with torch.set_grad_enabled(is_training):
cb.before_forward_pass()
out = model(x)
cb.after_forward_pass()
loss = loss_fn(out, y)
if is_training:
opt.zero_grad()
cb.before_backward_pass()
loss.backward()
cb.after_backward_pass()
opt.step()
phase.batch_loss = loss.item()
cb.batch_ended(phase=phase, output=out, target=y)
cb.phase_ended(phase=phase)
cb.epoch_ended(phases=phases, epoch=epoch)
cb.training_ended(phases=phases)
A couple of points about the implementation:
- Quick Draw Dataset
- No
fastaidependencies - No
Pathobjects stored in memory (reading data directly frompd.DataFrameand rendering images on the fly) - Direct usage of
torch.DataLoaderclasses, the transformations are taken from thetorchvision num_workers=12
Here are a memory usage plots:

The process is killed in the middle of the training epoch. So we can suppose that the problem is somewhere inside the torch package. (Except if my training loop contains the exact same bug as one in the fastai library which sounds like a very unusual coincidence  )
)
I am going to roll-back to 0.4.1 and see if the problem was introduced in the recent master or exists in the stable version as well.
Can’t claim for sure but it seems that, at least, pytorch-nightly has a problem with data loaders leaking memory when num_workers > 0.
I am going to share the implementation of the training loop I have. It is a bit involved because tries to mirror at least a couple of features that fastai includes. (Callbacks and cyclic schedule mostly). However, it shows a memory issue and probably could be helpful demonstration/starting point if we decide post to PyTorch’s forums.
4 Likes
For what it’s worth I believe I’m running into the same issue.
Personal machine, Ubuntu 18.04, 32 gig main RAM. Whale data set. Num_workers = 0 seems to fix it but is 3-4 times (maybe more) slower than trying to use … = 8. I’ve got 6 physical (12 logical) cores and 8gig VRAM.
I7-8750H, 1070 max-q.
I’ll post lib versions tomorrow.
1 Like
This is really interesting, thanks for taking the time to check this. Just one thought: like fastai you also use callbacks in many places, those get triggered also by every batch.
In order to pinpoint the problem really we should try to use the most simple version of a loop, so without any extra callbacks (or functionality copied into the batch loop), don’t you think?!
(and also without running e.g. tqdm or fast_process in order to avoid those as the unlikely but possible source of the problem)
The memory tracking could be done time based from a separate process.
Yes, sure, it is possible. My intention was to replicate the accuracy of the training as well so I’ve added various callbacks to make training loops more similar to each other. Actually, I’ve decided to combine testing and learning so now I have a custom training loop 
And I agree, now when the loop seems to work I can create a “plain” version without callbacks and progress bars to make the tracking process more transparent.
oops… I’m sorry if I misunderstood.
Here I asked you about lesson 1:
@jeremy In your notebook output, resnet34 learn.fit_one_cycle(4) took around 2 minutes in the main video notebook (using sagemaker)
While I can see, it took for you around 1 minute in the github lesson 1 notebook.
Can you please mention what was the specs for the video lesson nb training and what was for the github nb?
And you replied:
For github repo I’m using a 1080ti. In the lesson it’s a V100
So I thought that the 1 min. github repo (1080ti) is faster than the ~2min V100.
In lesson-6-pets-more notebook Jeremy used garbage collector.
gc.collect()
Does it make any difference for your memory leak?
Any insight why did he use that?
I worked on the doodle comp. for few days, and trained varieties of resnet models (resnet34 , 50 ,101) on ~8 million images, and had no memory issues. My GCP had gigantic memory for this comp (256GB) and 4 GPUs running 2 models each on 2 GPUs in parallell. The total max. RAM usage was never more than 50GB for the total 2 models + ~50GB cache.
My instance is new, so pytorch-nightly is a recent version.
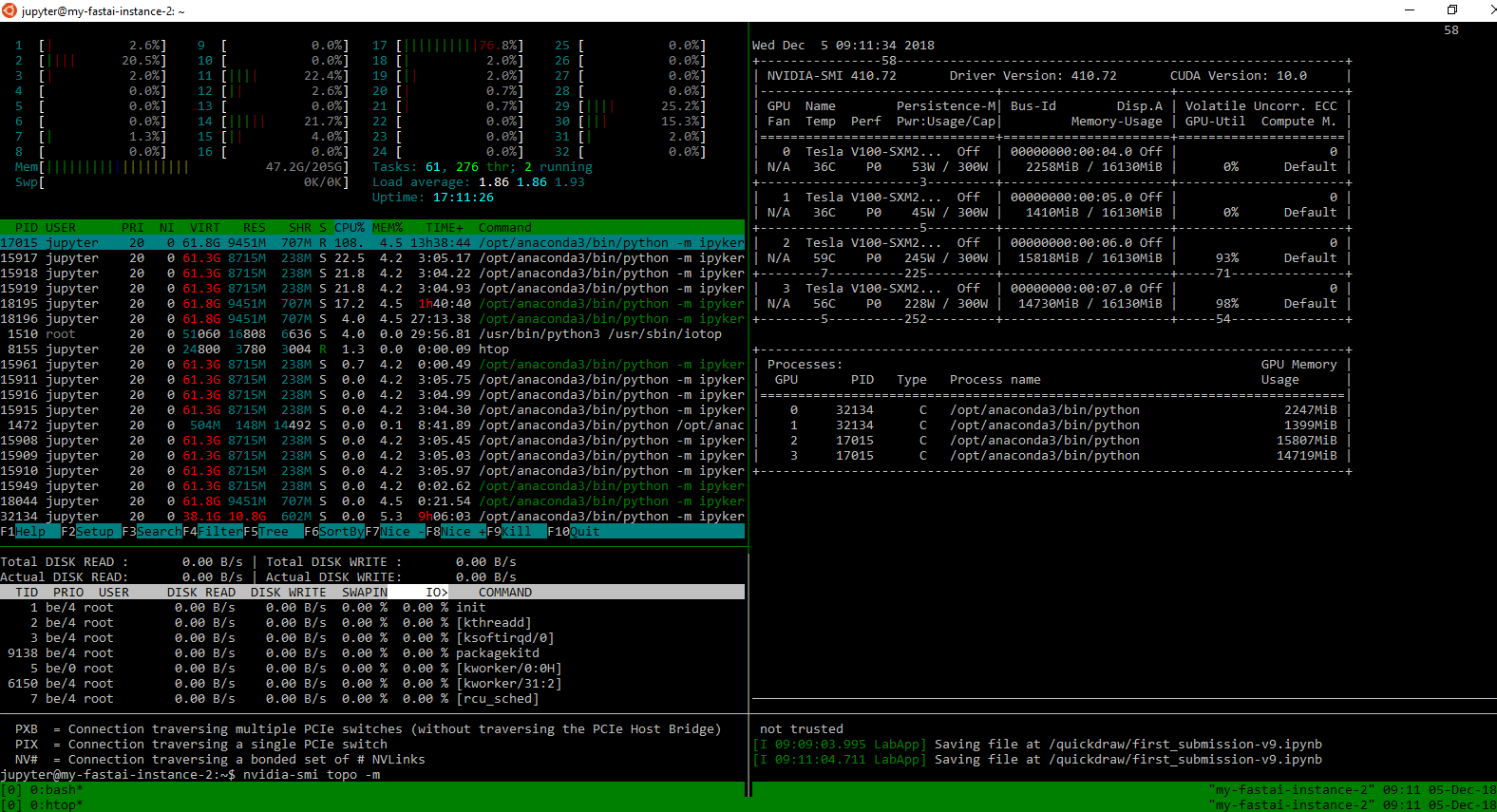
One model has already finished, so you see only 2 GPUs are working
1 Like
Hm, worth to make a try! I guess that the reason was that the Jupyter notebook keeps everything in the memory until you delete variable or restart kernel. So sometimes it is worth to call GC to free some memory.
However, I am not sure if it can help in a case when the data is captured in a more tricky way. For example, I had a similar issue here:
The problem was, I had incorrectly implemented a python generator using closures (lambda-functions). So it was keeping data in the memory after each batch iteration. And, as I can recall, GC wasn’t a big help in my case.
Yeah, that’s a problem if you have 32 GB only ![]() And as @balnazzar noted above, all his DGX 256GB were exhausted on a huge dataset. Also, 8M records are approx. 24K records per category while I was trying 50K per category, i.e, 17M.
And as @balnazzar noted above, all his DGX 256GB were exhausted on a huge dataset. Also, 8M records are approx. 24K records per category while I was trying 50K per category, i.e, 17M.
I would say that the main problem here is that the framework requires you to feet all this stuff into memory at once instead of iteratively load things on demand. So you need an enormous amount of memory even in the cases when it is not really required.
1 Like
The following discussion makes me feel sad ![]()
Could somebody comment this thing? Or better, do you know any practical advice on how to take part in Kaggle competitions with big datasets if we have such a limitation?
Probably I just don’t understand something but I was thinking it is possible to train the models on relatively huge datasets having limited hardware capabilities. However, if you can’t use multiprocessing to read the data, it sounds like an incredible I/O bottleneck which effectively means that Python itself is a problem in our case. I knew about things like GIL and multiprocessing limitations but didn’t think it could affect that much.
Would really appreciate if some experienced Kaggle practitioners could give an advice about participating in modern data competitions. Do you think that local a local machine should be used only to make experiments on relatively small datasets and everything else should be performed on hosts with a lot of RAM to cache the data in memory?
Sorry if my statements sound a bit like a panic ![]() I just trying to figure out what is going on here and which best practices could be used to alleviate the issue. (Except switching into single-threaded mode).
I just trying to figure out what is going on here and which best practices could be used to alleviate the issue. (Except switching into single-threaded mode).
Update: As a recommendation from the competition’s winner, here is a link to the library that I guess could help with multiprocessing. Haven’t tested yet but sounds interesting.
2 Likes
Dunno if this applies, but I’ve been running the last two days or so with num_workers = 2 and it’s been working. Defaults and I was getting the mentioned errors… Picked most of the speed back up with 2 vs. 0.
Interesting. I’ll try it tomorrow and report back!
1 Like
Did you try pytorch v0.4? Does it have the same issue?
Now that the comp ended, can you share a notebook that I can run to reproduce the issue in my same GCP instance that I reported that I had no memory issues with?
I will decrease the specs of the vm to the same level of your specs…
Although that I had no issues till now like that, but I am too worried that the bug is fundamental to the level of pytorch itself or worse if it is in python itself… No matter how much RAM you have, if this is a memory leak then in a real life big dataset, it will bring any system to its knees like a DGX-1.
So this should worry everybody.
Yeah, sure! I’ll share everything as soon as have time to make some small cleanup and upload into the repository. The code actually is very similar to standard notebooks shared here and there.
No, I didn’t try v0.4 but guys from Kaggle mentioned that they have used v0.4 and memory leaks happen no matter which multiprocessing program you’re running due to issues with Python’s implementation. However, I’ve trained some models with Keras and can’t remember if I had such a trouble. Though the datasets were not that big. So I am going to try this Pyro thing also that I’ve linked above.
Another interesting point also for someone who uses Pandas in their datasets classes:
Relevant to the @marcmuc’s notice about copy-on-write behavior.
1 Like
I have been reading up on this a little more after the insights from the 1st place winners. Here is the best stuff I could find, and I think we have the explanation now. So we have compounding problems in python itself (copy-on-access), pytorch (way multiprocessing is used) and fastai (too large objects, not wrapped “correctly”).
The core is this: There is no way of storing arbitrary python objects (such as pandas dfs, dicts of Pathbojects, or even simple lists) in shared memory in Python without triggering copy-on-write behaviour due to the addition of refcounts, everytime something reads from these objects. The refcounts are added memory-page by memory-page, which is why the consumption grows slowly, whereas by spawning the processes (and/or copying the entire objects in the beginning) it would jump up immediately. Either way, the processes will end up having all/most of the memory copied over bit by bit, which is why we get the memory overflow problem. Best description of this behaviour is here.
→ Hacky Workaround Solution 1: Check the memory consumption of your main process → Devide total free mem by this and set the number of workers to the resulting number (absolute maximum). This the background for @larcat’s num_workers=2 solution working for him I assume. It is also why you don’t ever get these problems with huge mem (like @hwasiti showed on gcp), because as long as num_workers x total_mem_of_main_process < total_mem_available, everything is fine!
→ Hacky Workaround Solution 2: Make sure the main process occupies as little memory as possible, by a) not storing lists of Path-Objects (i.e. using .from_csv methods and not .from_folders as suggested by Jeremy) and b) removing any unneccessary intermediate objects/lists/stuff from your main process (i.e. using del) and c) running gc.collect() before starting the fit process, so before the workers get forked (not sure if b) and c) really helps much, but it can’t hurt)
Real Solutions (not tested yet)
→ A) Using Multiprocessing like now: in order for python multiprocessing to work without these refcount effects, the objects have to be made “compatible with” and wrapped in multiprocessing.Array before the process pool is created and workers are forked. This supposedly ensures, that the memory will really be shared and no copy-on-write happens. This explains how to do it for numpy arrays and this explains the reasoning behind it again. Don’t get confused by some false statements even by the authors of these good answers stating that copy-on-write makes all of this unneccessary, which is not true. One comment also points to this:
“Just to note, on Python fork() actually means copy on access (because just accessing the object will change its ref-count).”
→ B) Using external tools/managers for storing the shared access objects, instead of storing them in the main process and the forked processes. Solutions could be the Pyro library as mentioned by the winners, but also something like Redis might be interesting. @vitaliy has experimented with this in the context of this competition almost 2 months ago, unfortunately without any replies, we should take a closer look at that I think!
Disclaimer: I am not an expert in any of this, just followed a lot of stack overflow link trails ![]()
If you think it is useful maybe I should split this long post out into a separate topic, after working in some of you guys’ comments/corrections.
6 Likes
A great summary! I am going to use the on-the-fly Dataset implementation without Pandas to see if it can help solve the problem. Will post the update as soon as ready.
1 Like
Also try to make your processing faster, so you need less workers. If you’re using jpegs, you should do this to install an accelerated jpeg library, since that’s a major overhead otherwise:
conda uninstall --force jpeg libtiff -y
conda install -c conda-forge libjpeg-turbo
CC="cc -mavx2" pip install --no-cache-dir -U --force-reinstall pillow-simd
7 Likes
@devforfu
This is slightly off topic, but there’s an example you posted in this thread where you are displaying map3 during training – Could you maybe provide a code snip of how you did this? I’m pretty new to the Pydata stack, and the numpy array manipulation syntax is pretty unintuitive to me still.
Thanks!
Pytorch 1.0 stable is released. Please note the release notes and particularly the big fixes (serious bugs). There are a few related to memory leaks and data loaders. It would be interesting to know whether this fixes your issues.
1 Like
Following a few links from the release notes fixes section leads to the (high priority) bug below, still open. I have posted links to this thread in the comments there and a short summary of my post above. (I have recategorized this thread so that it is linkable from the outside, because this issue is not really course v3 related.)
2 Likes