@balnazzar I am working on the whale competition where I have only ~75,000 images. I got the error:
RuntimeError: DataLoader worker (pid 5421) is killed by signal: Segmentation fault.
It is a local machine and it did not fill more than 15% of the 64GB RAM
Ubuntu 16
64GB
Cuda 10
Pytorch 1 stable
Error happened right after fit_one_cycle for a resnet50 model (image size 448), num_workers= 4
It seems if I let the data augmentation transforms as fastai defaults, I will not get the error like:
.transform(get_transforms(do_flip=False), size=SZ, resize_method=ResizeMethod.SQUISH)
instead of
.transform(get_transforms(do_flip=False, max_zoom=1.5, max_lighting=0.5, max_warp=0.7), size=SZ, resize_method=ResizeMethod.SQUISH)
Did you try to stick with the transforms default and still you get the error?
And I think the error that you and me are getting is different than the memory leak in the case of @marcmuc @devforfu where the RAM is filled before reaching the end of the epoch.
I noticed such error also in the Quick draw comp, where I could not change anything in the default transforms parameters. It does not seem even related to the number of images in the dataset. This whale competition has only few tens of thousands of images.
Edit: seems there are certain limits for the transforms arguments that cannot be increased over. For example, max_warp=0.6 will fail immediatly after learn.fit_one_cycle(8) in the pets notebook. However if I set it to 0.5 (default is 0.2) it will fail ~ 2nd epoch. Keeping in mind that the maximum value is just randomly (rarely applied on images), and if by chance it is appliead somewhere in the 1st epoch or subsequent epochs then it will fail.
I will make tests on what limits are acceptable on the lesson1 pets notebook after resnet50 fit_one_cycle.
Reproduced the error both on GCP and local machine.

Trace of the error:
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<timed exec> in <module>
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/train.py in fit_one_cycle(learn, cyc_len, max_lr, moms, div_factor, pct_start, wd, callbacks, **kwargs)
19 callbacks.append(OneCycleScheduler(learn, max_lr, moms=moms, div_factor=div_factor,
20 pct_start=pct_start, **kwargs))
---> 21 learn.fit(cyc_len, max_lr, wd=wd, callbacks=callbacks)
22
23 def lr_find(learn:Learner, start_lr:Floats=1e-7, end_lr:Floats=10, num_it:int=100, stop_div:bool=True, **kwargs:Any):
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/basic_train.py in fit(self, epochs, lr, wd, callbacks)
164 callbacks = [cb(self) for cb in self.callback_fns] + listify(callbacks)
165 fit(epochs, self.model, self.loss_func, opt=self.opt, data=self.data, metrics=self.metrics,
--> 166 callbacks=self.callbacks+callbacks)
167
168 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
92 except Exception as e:
93 exception = e
---> 94 raise e
95 finally: cb_handler.on_train_end(exception)
96
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
82 for xb,yb in progress_bar(data.train_dl, parent=pbar):
83 xb, yb = cb_handler.on_batch_begin(xb, yb)
---> 84 loss = loss_batch(model, xb, yb, loss_func, opt, cb_handler)
85 if cb_handler.on_batch_end(loss): break
86
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/basic_train.py in loss_batch(model, xb, yb, loss_func, opt, cb_handler)
25 loss = cb_handler.on_backward_begin(loss)
26 loss.backward()
---> 27 cb_handler.on_backward_end()
28 opt.step()
29 cb_handler.on_step_end()
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/callback.py in on_backward_end(self)
229 def on_backward_end(self)->None:
230 "Handle end of gradient calculation."
--> 231 self('backward_end', False)
232 def on_step_end(self)->None:
233 "Handle end of optimization step."
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/callback.py in __call__(self, cb_name, call_mets, **kwargs)
186 "Call through to all of the `CallbakHandler` functions."
187 if call_mets: [getattr(met, f'on_{cb_name}')(**self.state_dict, **kwargs) for met in self.metrics]
--> 188 return [getattr(cb, f'on_{cb_name}')(**self.state_dict, **kwargs) for cb in self.callbacks]
189
190 def on_train_begin(self, epochs:int, pbar:PBar, metrics:MetricFuncList)->None:
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/callback.py in <listcomp>(.0)
186 "Call through to all of the `CallbakHandler` functions."
187 if call_mets: [getattr(met, f'on_{cb_name}')(**self.state_dict, **kwargs) for met in self.metrics]
--> 188 return [getattr(cb, f'on_{cb_name}')(**self.state_dict, **kwargs) for cb in self.callbacks]
189
190 def on_train_begin(self, epochs:int, pbar:PBar, metrics:MetricFuncList)->None:
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/train.py in on_backward_end(self, **kwargs)
75 def on_backward_end(self, **kwargs):
76 "Clip the gradient before the optimizer step."
---> 77 if self.clip: nn.utils.clip_grad_norm_(self.learn.model.parameters(), self.clip)
78
79 def clip_grad(learn:Learner, clip:float=0.1)->Learner:
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/torch/nn/utils/clip_grad.py in clip_grad_norm_(parameters, max_norm, norm_type)
30 total_norm = 0
31 for p in parameters:
---> 32 param_norm = p.grad.data.norm(norm_type)
33 total_norm += param_norm.item() ** norm_type
34 total_norm = total_norm ** (1. / norm_type)
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/torch/tensor.py in norm(self, p, dim, keepdim)
250 def norm(self, p="fro", dim=None, keepdim=False):
251 r"""See :func: `torch.norm`"""
--> 252 return torch.norm(self, p, dim, keepdim)
253
254 def btrifact(self, info=None, pivot=True):
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/torch/functional.py in norm(input, p, dim, keepdim, out)
716 return torch._C._VariableFunctions.frobenius_norm(input)
717 elif p != "nuc":
--> 718 return torch._C._VariableFunctions.norm(input, p)
719
720 if p == "fro":
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/torch/utils/data/dataloader.py in handler(signum, frame)
272 # This following call uses `waitid` with WNOHANG from C side. Therefore,
273 # Python can still get and update the process status successfully.
--> 274 _error_if_any_worker_fails()
275 if previous_handler is not None:
276 previous_handler(signum, frame)
RuntimeError: DataLoader worker (pid 5421) is killed by signal: Segmentation fault.
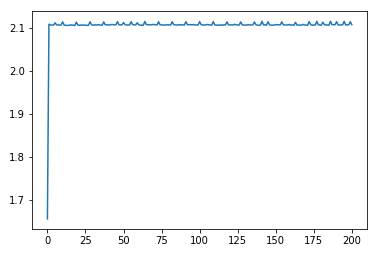
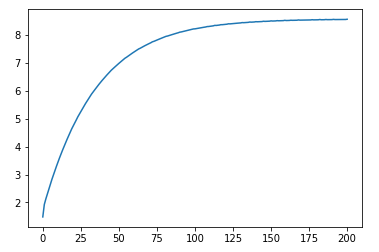
 . But this is from bookmarks I saved then:
. But this is from bookmarks I saved then: