@t-v @stas BTW the algorithm I had in mind is a little different to what you implemented - I think it can be faster and skip basically all the compute. I’ve created a new thread to discuss this:
To make this compare more precise for those reading along: what happens is that PyTorch has freed the graph of the previous batch in that batch’s backward and now finds that it has a node (from the previous batch) without the graph connections it would need to propagate the gradient.
It’ll all become more clear once Jeremy decides to do “even more impractical deep learning for coders” where he also re-implements autograd. 
Just to clarify - all it can tweak are the model parameters. So we’re not changing what’s learnable when we detach something that’s not a parameter, only what grad history is available to our parameters.
My understanding (which might be wrong) is that detach removes the grad history. So whilst we are indeed immediately bringing these vars back in to the grad calculation, we’re doing so with a truncated history. This is necessary (AFAIK) to avoid the grad history getting too long to be workable (as we have to do in ULMFiT RNNs, for instance).
Figuring out those details is a key question in this mini-project!  The goal is: bn using running statistics that runs fast. The question is - how to do that in practice? I’m pretty sure it’s mathematically a totally reasonable thing to do, but I think that getting the details right to make it work in practice is an interesting exercise.
The goal is: bn using running statistics that runs fast. The question is - how to do that in practice? I’m pretty sure it’s mathematically a totally reasonable thing to do, but I think that getting the details right to make it work in practice is an interesting exercise.
class RunningBatchNorm(nn.Module):
def __init__(self, nf, mom=0.1, eps=1e-5):
super().__init__()
self.mom, self.eps = mom, eps
self.mults = nn.Parameter(torch.ones (nf,1,1))
self.adds = nn.Parameter(torch.zeros(nf,1,1))
self.register_buffer('sums', torch.zeros(1,nf,1,1))
self.register_buffer('sqrs', torch.zeros(1,nf,1,1))
self.register_buffer('count', tensor(0.))
self.batch = 0
self.iter = 0
def update_stats(self, x):
bs,nc,*_ = x.shape
self.batch += bs
self.iter += 1
if self.batch > 1000 and self.iter%2:
# we want to re-use use means and stds, but
# if they're old, they don't depend on things that are
# still around to propagate gradients to
self.means.detach_()
self.stds.detach_()
return
self.sums.detach_()
self.sqrs.detach_()
dims = (0,2,3)
s = x .sum(dims, keepdim=True)
ss = (x*x).sum(dims, keepdim=True)
c = s.new_tensor(x.numel()/nc)
mom1 = s.new_tensor(1 - (1-self.mom)**(bs/32)) # edited.
self.sums .lerp_(s , mom1)
self.sqrs .lerp_(ss, mom1)
self.count.lerp_(c , mom1)
self.means = self.sums/self.count
self.stds = ((self.sqrs/self.count).sub_(self.means.pow(2)) + self.eps).sqrt()
if self.batch < 20: self.stds = self.stds.clamp_min(0.1)
def forward(self, x):
if self.training: self.update_stats(x)
factor = self.mults / self.stds
offset = self.adds - self.means*factor
return x*factor + offset
(The change from self.varns to self.stds is of course unrelated and just me reducing the number of ops in the shorcut path. )
@t-v, it doesn’t train. With yours getting:
learn,run = get_learn_run(nfs, data, 0.4, conv_rbn, cbs=cbfs)
%time run.fit(1, learn)
train: [nan, tensor(0.1166, device='cuda:0')]
valid: [nan, tensor(0.0991, device='cuda:0')]
CPU times: user 6.3 s, sys: 54 ms, total: 6.35 s
Wall time: 6.39 s
I meant to say it was easy to “fix” the error, now that I have the debug tool to tell me what’s on graph and what not.
So the challenge here isn’t really a coding one, but a conceptual DL one - how do we do a batch norm that uses running statistics during training, and doesn’t calculate them more than mathematically necessary.
In addition to sorting out the conceptual part we need to get a real understanding of pytorch computational graph mechanics. To me the graph is still a black-box. I want to be able to see exactly what happens in each iteration, so that I could see the graph and the history. Then we understand how the moving parts work. Then we will know how to bolt the conceptual part on to the pytorch machinery.
@t-v, what debug tools can we use?
These were helpful so far: requires_grad, is_leaf
Any other more advanced tools? e.g. show me the graph?
What I have been trying to ask for quite a few messages by now - why do you want those accumulating variables sums and sqrs to have grads in first place? Don’t set the grads in first place and then you won’t need to worry about the history.
Because without it I don’t get good accuracy. Without that information in the gradients, the model doesn’t have as much information to know how to update its weights correctly.
If you can find a way to get as good accuracy without those grads, that would be great!
So what happens is that the parameters blow up at small batch sizes. But my current guess is that that’s more the interplay between learning rate, batch size, how many stats to gather etc. that’s not yet working out here.
I’m trying this graph visualizer https://github.com/waleedka/hiddenlayer - but it fails to build a graph for this BN, failing with
ValueError: only one element tensors can be converted to Python scalars
torch.onnx land.
I was able to build part of it:
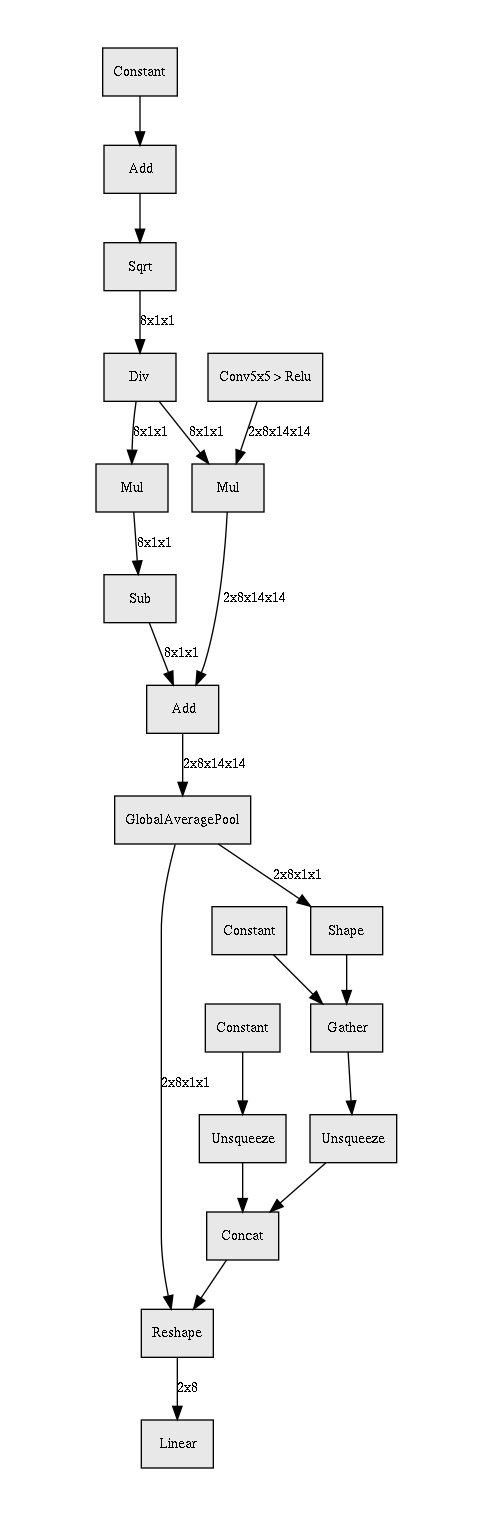
This is before I got a chance to calculate vars and means - fails to build if I enable that part. Also I had to unroll a few in place functions to be non-inplace:
class RunningBatchNorm(nn.Module):
def __init__(self, nf, mom=0.1, eps=1e-5):
super().__init__()
self.mom, self.eps = mom, eps
self.mults = nn.Parameter(torch.ones (nf,1,1))
self.adds = nn.Parameter(torch.zeros(nf,1,1))
self.register_buffer('sums', torch.zeros(1,nf,1,1))
self.register_buffer('sqrs', torch.zeros(1,nf,1,1))
self.register_buffer('count', tensor(0.))
self.register_buffer('means', torch.zeros(nf,1,1))
self.register_buffer('varns', torch.ones(nf,1,1))
self.batch = 0
self.iter = 0
def update_stats(self, x):
bs,nc,*_ = x.shape
self.batch += bs
self.iter += 1
dims = (0,2,3)
s = x .sum(dims, keepdim=True)
ss = (x*x).sum(dims, keepdim=True)
c = s.new_tensor(x.numel()/nc)
div = self.batch-1 if self.batch>1 else 1
mom1 = s.new_tensor(1 - (1-self.mom)/math.sqrt(div))
self.sums = self.sums .lerp(s , mom1)
self.sqrs = self.sqrs .lerp(ss, mom1)
self.count = self.count.lerp(c , mom1)
return
self.means = self.sums.div(self.count)
self.varns = (self.sqrs/self.count).sub(self.means.pow(2))
if self.batch < 20: self.varns.clamp_min_(0.01)
def forward(self, x):
if self.training: self.update_stats(x)
factor = self.mults / (self.varns+self.eps).sqrt()
offset = self.adds - self.means*factor
return x*factor + offset
learn,run = get_learn_run(nfs, data, 0.4, conv_rbn, cbs=cbfs)
learn.model = learn.model.cuda()
import hiddenlayer as hl
g = hl.build_graph(learn.model, torch.randn([2, 1, 28, 28]).cuda())
g
#g.save("bn.png", format="png")
I can’t figure out why it stumbles upon means update. Well, it looks like an early alpha tool.
2 Likes
It doesn’t seem to be. Even v low LR and very frequently stats updates have the same issue.
I’ve been using this in the 07_batchnorm notebook with batch size 8 and a learning rate of 0.1 and it seems to converge - I get 97.8%, not great, but not NaN/10%. It’s awfully slow at 2 min 42 s.
To be sure, here is my current code:
class RunningBatchNorm(nn.Module):
def __init__(self, nf, mom=0.1, eps=1e-5):
super().__init__()
self.mom, self.eps = mom, eps
self.mults = nn.Parameter(torch.ones (nf,1,1))
self.adds = nn.Parameter(torch.zeros(nf,1,1))
self.register_buffer('sums', torch.zeros(1,nf,1,1))
self.register_buffer('sqrs', torch.zeros(1,nf,1,1))
self.register_buffer('count', tensor(0.))
self.batch = 0
self.iter = 0
def update_stats(self, x):
bs,nc,*_ = x.shape
self.batch += bs
self.iter += 1
if self.batch > 1000 and self.iter%2==0:
# we want to re-use use means and stds, but
# if they're old, they don't depend on things that has
# gradients
self.means.detach_()
self.stds.detach_()
return
self.sums.detach_()
self.sqrs.detach_()
dims = (0,2,3)
s = x .sum(dims, keepdim=True)
ss = (x*x).sum(dims, keepdim=True)
c = s.new_tensor(x.numel()/nc)
mom1 = s.new_tensor(1 - (1-self.mom)**(bs/32))
if self.batch == bs:
print ("mom1", mom1, "c", c)
self.sums .lerp_(s , mom1)
self.sqrs .lerp_(ss, mom1)
self.count.lerp_(c , mom1)
self.means = self.sums/self.count
self.stds = ((self.sqrs/self.count).sub_(self.means * self.means).clamp_min_(0) + self.eps).sqrt()
if (torch.isnan(self.stds).any() or torch.isnan(self.means).any()):
raise Exception("found NaN")
if self.batch < 20: self.stds = self.stds.clamp_min(0.1)
def forward(self, x):
if self.training: self.update_stats(x)
factor = self.mults / self.stds
offset = self.adds - self.means*factor
y = x*factor + offset
if (torch.isnan(y).any()):
raise Exception("found NaN")
return y
Do your parameters explode, too, before you get NaNs?
1 Like
Please note a new reply that ended up before your replies, because of the ridiculous rule of discourse setting that one can’t post more than 3 consecutive replies so I had to wait till one of you replied and only then it allowed me to post. And of course, being a “smart” software, it inserted my post in the wrong place 
Anyways, please have a look:
1 Like
OK, I found another visualizer that works (it seems to be that the first one I mentioned earlier has problems with JIT):
# pip install torchviz
from torchviz import make_dot
model = learn.model.cuda()
x = torch.randn([1, 1, 28, 28]).cuda()
g = make_dot(model(x), params=dict(model.named_parameters()))
g.format = 'png'
g.render('bn')
g
And if I run it on RunningBatchNorm with any detach, the first time we get:

So now we should be able to see what’s on the tree, and if you re-run the code, seeing where graph leaks, etc. e.g. if I pass the input 2nd time the tree doubles in size! that’s expected since I run it on the version with no detach or without torch.no_grad()
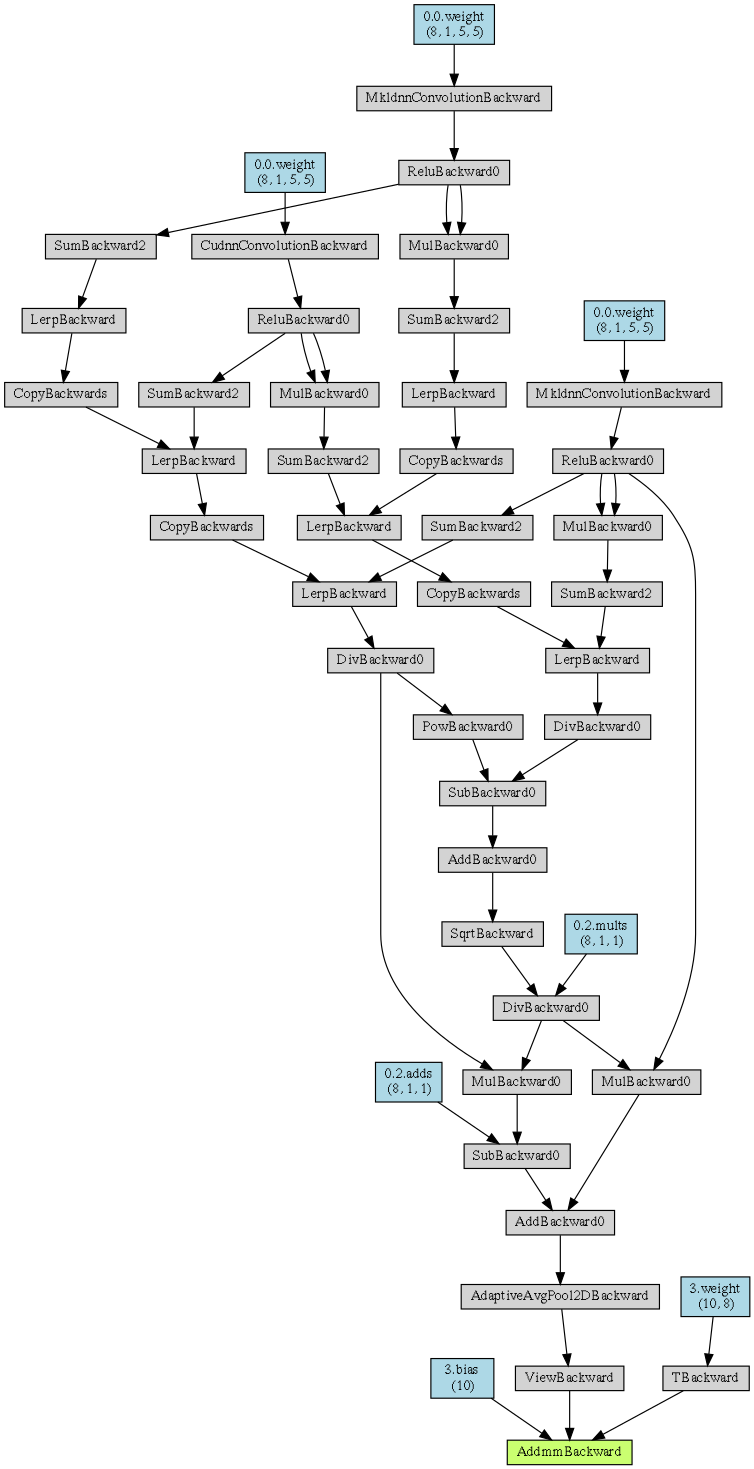
3 Likes
Me thinking - perhaps let’s not worry about optimizations first, since those optimizations complicate things. Figure out the stat computation skipping w/o affecting the training quality - and once there optimizing should be easy.
As of now, even if I go back to your class’s version minus dbias, it won’t train well with even a tiny amount of skipping re-calculations.
Here is pretty much that version with a few minor tweaks (making batch non-var + adding iter), also added bs-1 or 1 to avoid div by zero with bs=1.
class RunningBatchNorm(nn.Module):
def __init__(self, nf, mom=0.1, eps=1e-5):
super().__init__()
self.mom,self.eps = mom,eps
self.mults = nn.Parameter(torch.ones (nf,1,1))
self.adds = nn.Parameter(torch.zeros(nf,1,1))
self.register_buffer('sums', torch.zeros(1,nf,1,1))
self.register_buffer('sqrs', torch.zeros(1,nf,1,1))
self.register_buffer('count', tensor(0.))
self.batch = 0
self.iter = 0
def update_stats(self, x):
bs,nc,*_ = x.shape
self.batch += bs
self.iter += 1
self.sums.detach_()
self.sqrs.detach_()
if self.batch > 10000 and not self.iter%10: return
dims = (0,2,3)
s = x .sum(dims, keepdim=True)
ss = (x*x).sum(dims, keepdim=True)
c = self.count.new_tensor(x.numel()/nc)
mom1 = 1 - (1-self.mom)/math.sqrt(bs-1 or 1)
self.mom1 = s.new_tensor(mom1)
self.sums.lerp_ (s, self.mom1)
self.sqrs.lerp_ (ss, self.mom1)
self.count.lerp_(c, self.mom1)
def forward(self, x):
if self.training: self.update_stats(x)
means = self.sums/self.count
vars = (self.sqrs/self.count).sub_(means.pow(2))
if self.batch < 20: vars.clamp_min_(0.01)
x = (x-means).div_((vars.add_(self.eps)).sqrt())
return x.mul_(self.mults).add_(self.adds)
Feel free to tweak if self.batch > 10000 and not self.iter%10: return - the code doesn’t do well even at skipping 1 out of 10 calcs, after 10000 samples. This class’s version simply skips accumulating sums and sqrs.
And earlier we made attempts to always accumulate sums and sqrs and it didn’t fair any better.
So in addition to the above adjustments to the code (in particular mom1), learning rate, and batch size, I’m running on a nightly version of PyTorch (well, sort of).
What led me to believe it’s the usual suspects (i.e. hyperparameters) is after I checked for NaNs either in the RBN module or just the loss. It turned out that the number of batchs it goes varied with the hyperparameters. Also, printing the weight magnitudes (just print([(n,p.abs().max().item()) for n,p in learn.model.named_parameters]) after each minibatch had suspicious results.)
That’s exciting! I think this is the first successful training of rbn with skipping!
1 Like
This should replace nn.BatchNorm2d after it is done.
How would we adapt this to work in place of BatchNorm1d/3d?
If you change the shapes to be 3d or 5d, and adjust taking mean and var over dimensions 0, 2 or 0, 2, 3, 4, it’ll do the right thing. Fun fact: BatchNorm in PyTorch reduces to the “BatchNorm1d” case internally.
2 Likes
HI,I run the code from beginning of lesson 11…However , the error is raised,The only thing that I change is :
tensor(0.) to torch.tensor(0.)
The code :
class RunningBatchNorm(nn.Module):
def __init__(self, nf, mom=0.1, eps=1e-5):
super().__init__()
self.mom,self.eps = mom,eps
self.mults = nn.Parameter(torch.ones (nf,1,1))
self.adds = nn.Parameter(torch.zeros(nf,1,1))
self.register_buffer('sums', torch.zeros(1,nf,1,1))
self.register_buffer('sqrs', torch.zeros(1,nf,1,1))
self.register_buffer('count', torch.tensor(0.))
self.register_buffer('factor', torch.tensor(0.))
self.register_buffer('offset', torch.tensor(0.))
self.batch = 0
def update_stats(self, x):
bs,nc,*_ = x.shape
self.sums.detach_()
self.sqrs.detach_()
dims = (0,2,3)
s = x.sum(dims, keepdim=True)
ss = (x*x).sum(dims, keepdim=True)
c = s.new_tensor(x.numel()/nc)
mom1 = s.new_tensor(1 - (1-self.mom)/math.sqrt(bs-1))
self.sums.lerp_(s, mom1)
self.sqrs.lerp_(ss,mom1)
self.count.lerp_(c, mom1)
self.batch += bs
means = self.sums/self.count
varns = (self.sqrs/self.count).sub_(means*means)
if bool(self.batch<20):
varns.clamp_min_(0.01)
self.factor = self.mults/(varns+self.eps).sqrt()
self.offset = self.adds-means*self.factor
def forward(self, x):
if self.training:
self.update_stats(x)
return x*self.factor+self.offset
The error message something like :
one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor []] is at version 6; expected version 5 instead…
I suspect this error happens is because of this operation
self.count.lerp_(c, mom1)
But I don’t really have whole concept of this ,please check and help…
Thanks in advance and have a great day !!!