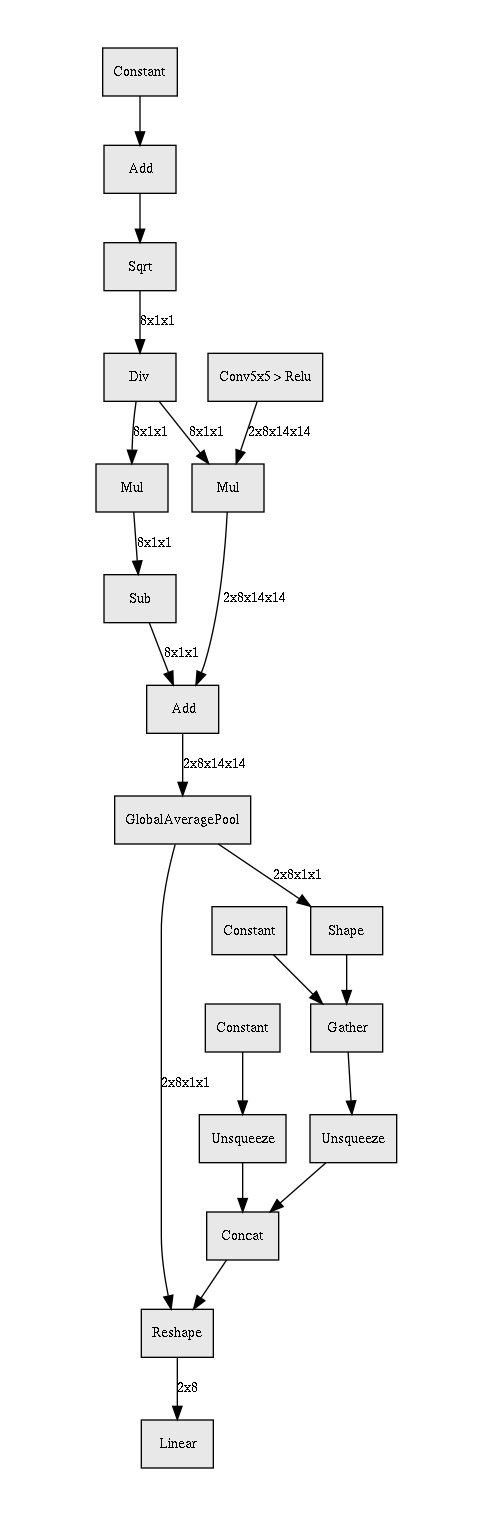
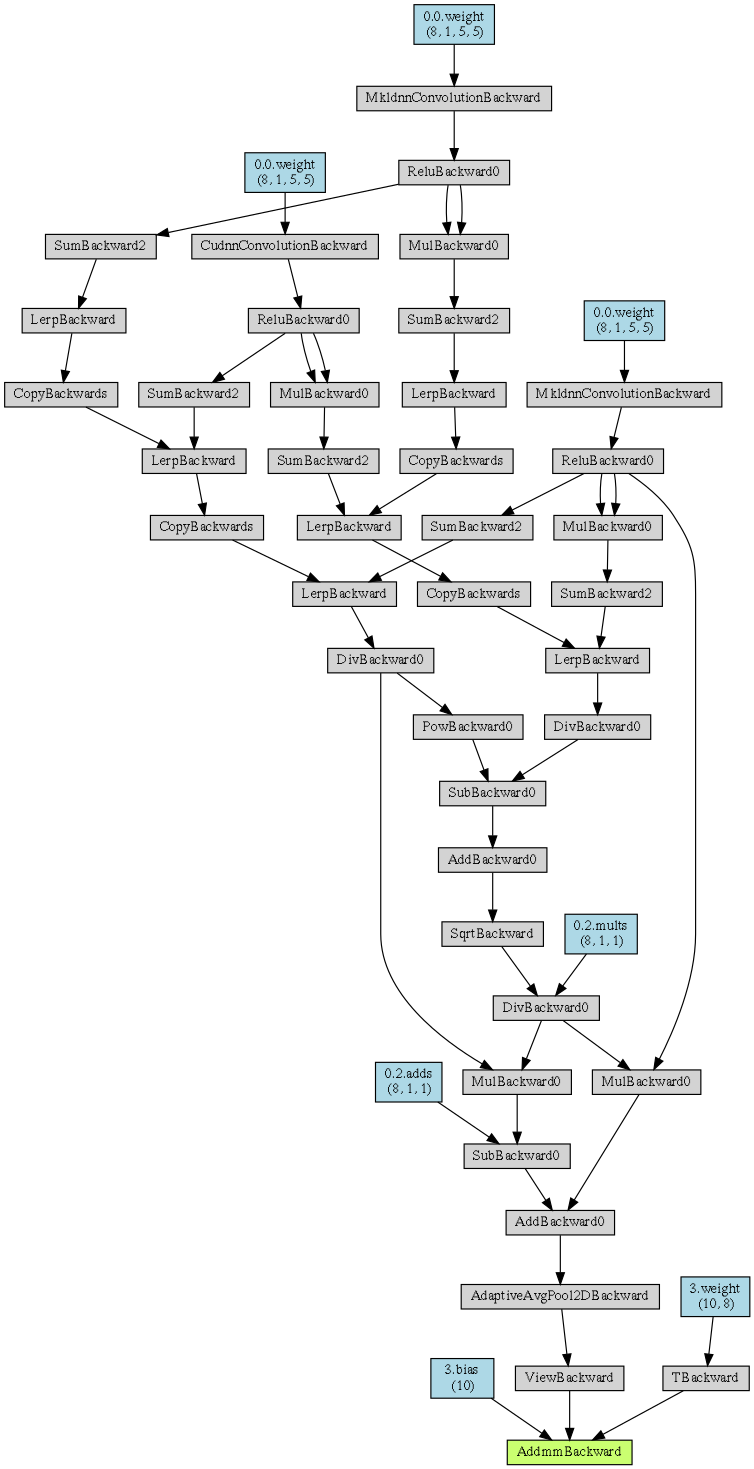
Continuing a discussion from Lesson 11 thread… The goal is to speed up running batchnorm (rbn) by only recalculating statistics occasionally. Something like this (although this isn’t working):
class RunningBatchNorm(nn.Module):
def __init__(self, nf, mom=0.1, eps=1e-5):
super().__init__()
self.mom, self.eps = mom, eps
self.mults = nn.Parameter(torch.ones (nf,1,1))
self.adds = nn.Parameter(torch.zeros(nf,1,1))
self.register_buffer('sums', torch.zeros(1,nf,1,1))
self.register_buffer('sqrs', torch.zeros(1,nf,1,1))
self.register_buffer('count', tensor(0.))
self.batch = 0
self.iter = 0
def update_stats(self, x):
bs,nc,*_ = x.shape
self.batch += bs
self.iter += 1
if self.batch > 1000 and self.iter%2: return
self.sums.detach_()
self.sqrs.detach_()
dims = (0,2,3)
s = x .sum(dims, keepdim=True)
ss = (x*x).sum(dims, keepdim=True)
c = s.new_tensor(x.numel()/nc)
mom1 = s.new_tensor(1 - (1-self.mom)/math.sqrt(self.batch-1))
self.sums .lerp_(s , mom1)
self.sqrs .lerp_(ss, mom1)
self.count.lerp_(c , mom1)
self.means = self.sums/self.count
self.varns = (self.sqrs/self.count).sub_(self.means.pow(2))
if self.batch < 20: self.varns.clamp_min_(0.01)
def forward(self, x):
if self.training: self.update_stats(x)
factor = self.mults / (self.varns+self.eps).sqrt()
offset = self.adds - self.means*factor
return x*factor + offset
 )
)