I’m doing Lesson 04_mnist_basics of the 2020 course and am in section The MNIST Loss Function.
Within this section, the initial benchmark that is used to decide whether an image is a 3 or a 7 is if the linear combination of an image is greater than 0, then that image is a 3, else that image is a 7.
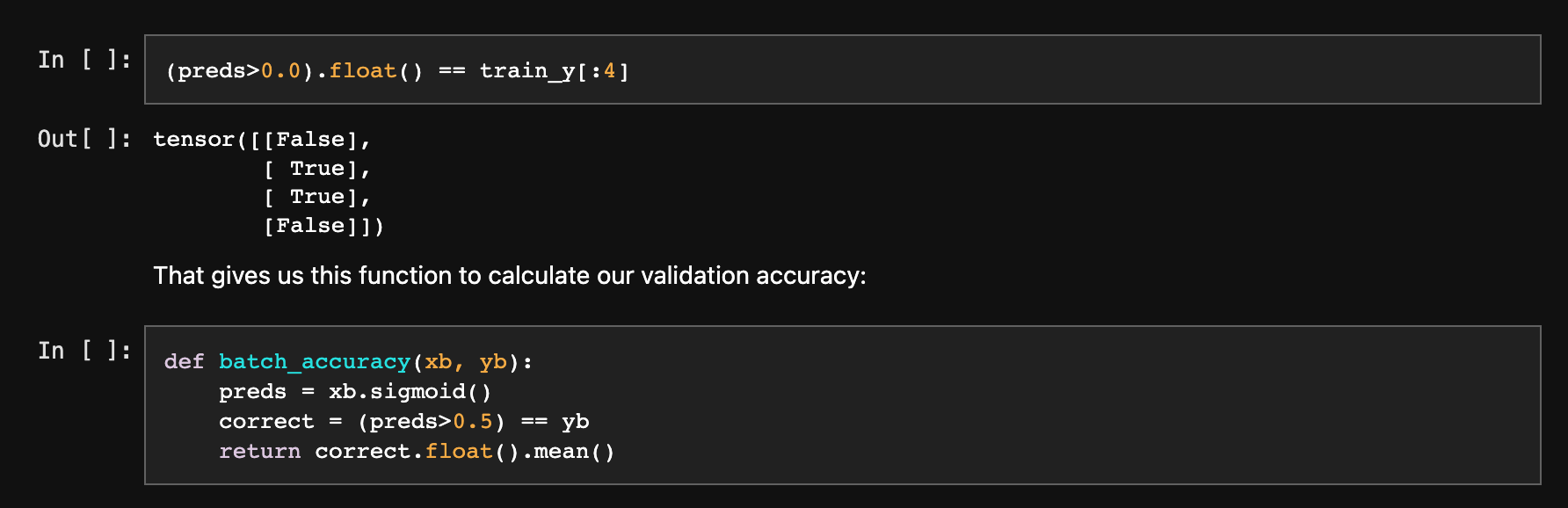
corrects = (preds>0.0).float() == train_y
Why are we choosing 0? What if images with a linear combination above, let’s say, 2 is a 3? What if a combination less than -4 is a 3?
The lesson states the following.
Let’s check our accuracy. To decide if an output represents a 3 or a 7, we can just check whether it’s greater than 0.0, so our accuracy for each item can be calculated (using broadcasting, so no loops!)
It feels that 0.0 is being chosen quite arbitrarily. I would appreciate any clarification on this.
Only reason I can think of to do preds>0.0 is that if the prediction is negative it’s a 7 (or 0) and if it’s positive, it’s a 3 (or 1). So, in other words, they are splitting it halfway between negative and positive predictions. However, I don’t know for sure.
Later on when passing the predictions through sigmoid they change the accuracy calculation to preds>0.5, which makes sense.
Forgot to click “Reply” on the response I meant to send yesterday (-‸ლ)
That forum post definitely is helpful, and now I think I understand why 0 is chosen.
Firstly, it’s because the way that the weights that have been chosen means the model ends up producing predictions that are either 0 or 1.
Secondly, it’s because of the sigmoid loss function we use later on. This function maps any input number to a value between 0 and 1, with negative numbers resulting in an output closer to 0, positive numbers resulting in an output closer to 1, and a 0 resulting in an output of 0.5 — the middle point of the sigmoid. Later on in the notebook, we use the sigmoid function in such a way that any output larger than 0.5 is one class, and any output less than 0.5 is another class.
That post definitely helped clear this confuzzlement.