Let us start from the beginning. Randomly initializing weights gives values like so
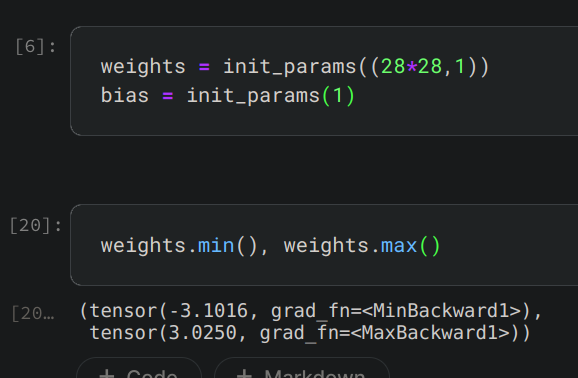
We know that train_x has values between 0 and 1. So, train_x@weights (with weights initialized randomly) gives outputs like so
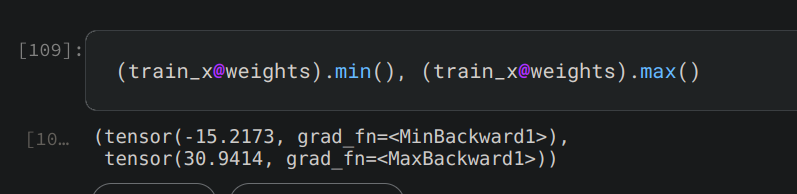
This confirms that our linear model outputs both negative and positive values around 0. Convincing yourself of this and then reading @ benkarr 's comment should help you understand why
> 0.0 equals a good prediction.