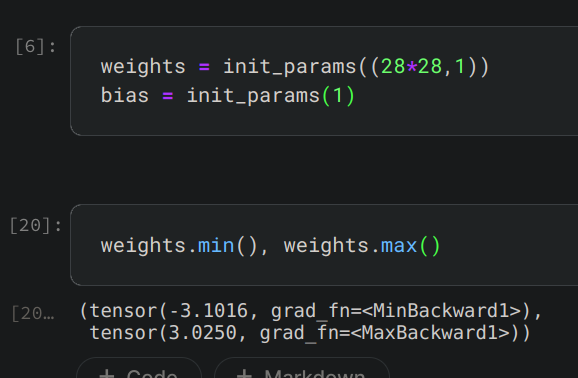
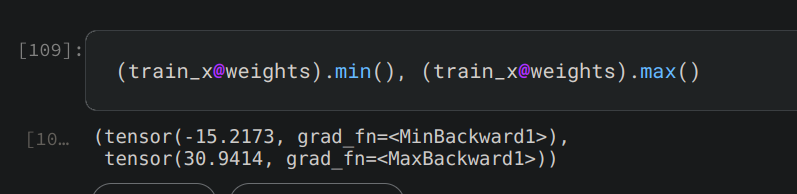
Hi, I’m trying to train a model on the whole MNIST set
class BasicOptimizer:
def __init__(self, model, lr):
self.model = model
self.lr = lr
def step(self):
self.model.w1.data = self.model.w1.data - self.lr * self.model.w1.grad.data
self.model.b1.data = self.model.b1.data - self.lr * self.model.b1.grad.data
self.model.w2.data = self.model.w2.data - self.lr * self.model.w2.grad.data
self.model.b2.data = self.model.b2.data - self.lr * self.model.b2.grad.data
def zero_grad(self):
self.model.w1.grad = None
self.model.b1.grad = None
self.model.w2.grad = None
self.model.b2.grad = None
class Model():
def __init__(self):
self.w1 = self.init_parameters((28*28,30))
self.b1 = self.init_parameters(30)
self.w2 = self.init_parameters((30,10))
self.b2 = self.init_parameters(10)
def init_parameters(self, size):
return torch.randn(size).requires_grad_()
def forward(self, x):
res = x@self.w1 + self.b1
res = res.max(tensor(0.0))
res = res@self.w2 + self.b2
res = torch.nn.Softmax( dim=1 )(res)
return res
class SimpleNetwork:
def __init__(self, dl, val_dl, model, optimizer):
self.dl = dl
self.val_dl = val_dl
self.model = model
self.optimizer = optimizer
def prediction(self, x):
return self.model.forward(x)
def loss(self, pred, target):
return torch.nn.functional.cross_entropy(pred, target)
def step(self, x, y):
pred = self.prediction(x)
loss = self.loss(pred, y)
loss.backward()
self.optimizer.step()
self.optimizer.zero_grad()
def validate(self, x, y):
with torch.no_grad():
pred = self.prediction(x)
val = torch.eq(
torch.argmax( pred, dim=1 ),
torch.argmax( y, dim=1 )
).float().mean()
return val
def learn(self, epochs):
for epoch in range(epochs):
print( "epoch " + str(epoch) )
for xb, yb in self.dl:
self.step(xb, yb)
accs = [ self.validate(val_xb, val_yb) for val_xb, val_yb in self.val_dl ]
acc = round( torch.stack( accs ).mean().item(), 4 )
print("Accuracy " + str(acc))
My accuracy is going up which is good, but is very low. What I’m doing wrong?
epoch 0
Accuracy 0.127
epoch 1
Accuracy 0.1287
epoch 2
Accuracy 0.1299
epoch 3
Accuracy 0.1316
epoch 4
Accuracy 0.1327
epoch 5
Accuracy 0.1335
epoch 6
Accuracy 0.1352
epoch 7
Accuracy 0.1358
epoch 8
Accuracy 0.1367
epoch 9
Accuracy 0.1377