FYI I Get 87.69% training xresnet18 from scratch on Stanford-cars, 250 epochs with lr=1e-3, using one cycle.
Edit: that’s without Mixup
FYI I Get 87.69% training xresnet18 from scratch on Stanford-cars, 250 epochs with lr=1e-3, using one cycle.
Edit: that’s without Mixup
nice result for a lightweight model!
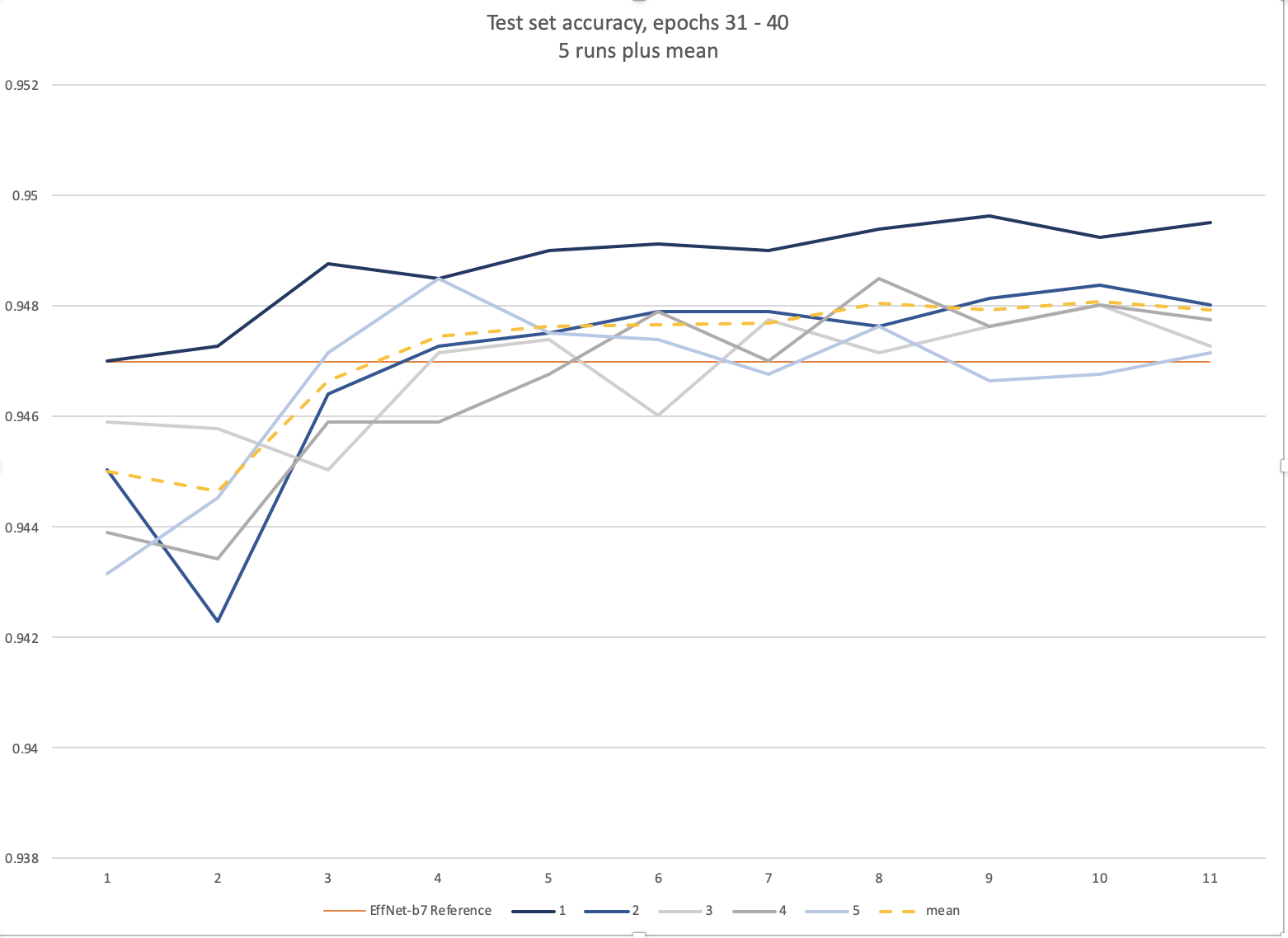
94.79% with EfficientNet-b7 + Mish + Ranger
Code here: https://github.com/morganmcg1/stanford-cars
Nice work! Seems like you’ve figured out what works to train Efficientnet more easily! It’s actually a big thing in itself to have reproduced the paper’s results. Your work might help everyone doing transfer learning. I know I was struggling with Efficientnet when it first came out.
Which model has SoTA results?
Also, you’re saying in the other thread that Mish + Ranger help with training stability. Have you experimented to see if Ranger or Mish on their own helps?
I actually thought it was 94.8% as per the results table in the EfficientNet paper, but they cite Domain Adaptive Transfer Learning with Specialist Models which has a 96% if you look at the paper! From a glance, I think they pretrained an Inception-V3 model on only selection of ImageNet images (e.g. emphasis on cars).
AutoAugment: Learning Augmentation Policies from Data is the paper with 94.8% (they actually quote 5.2% error rate as their result)
I just updated the Papers With Code leader board here for the Stanford Cars dataset: Stanford Cars Benchmark (Fine-Grained Image Classification) | Papers With Code
I had done some quick and dirty testing yes and found that individually they seemed easier to train than the default EfficientNet swish + rmsprop. But I don’t have much to back that up, it wasn’t a proper paper-style ablation test so maybe take it with a grain of salt ![]()
Hello Morgan.
Great implementation. I am trying to run your example code with a simpler and different dataset.
Instead of the data_test loading that you are using, I am trying to use keras imagedata generator.
However when it is time to train the model I have an error:
How could I solve this error? Could you help me with this issue?
Thanks a lot.
I’m not sure you can mix and match the Keras image generator with fastai, better to stick within fastai if you can I think…
Thanks for your response.
How could I proceed then? Basically I created an image dataset uploaded to Google Drive and I am trying to implement on Google Colab the EfficientNet + Ranger + Mish code that you kindly provided.
I can send you the notebook if it not a problem. Sorry if the question is a bit introductory, but I was used to work with Keras, I am starting to work now with Pytorch and Fastai.
Again, thanks for your help.
Do you have the train and test image files in folders in your Google Drive? If so you should be able to more of less just run my code I think. I’m not familiar with linking Drive to Colab (e.g. what the “path” should look like), but I think that should be the only change needed. I think sharing your notebook might help yep 
It worked!!
Thanks very much, great implementation by the way.
great to hear 
Hello!
I’m curious why you trained your model in notebook 9 with .to_fp16() even though you were training it on a p4000? That makes it 64x slower than fp32. Also, why did you pick 15e-4 to be your learning rate?
Hey!
I pick the lr because thats what had generally worked in previous experiments.
re fp_16(), wouldn’t it be faster than fp32? As you can train with larger batch sizes? Or do the P4000s not work as well with fp16 as other cards (e.g. 2070/2080 etc)?
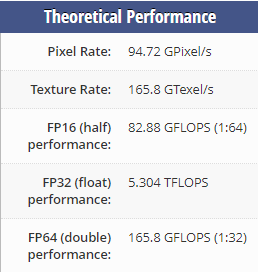
It’s only faster when the GPU processes fp16 faster than fp32. For example:
P4000:
1080Ti:
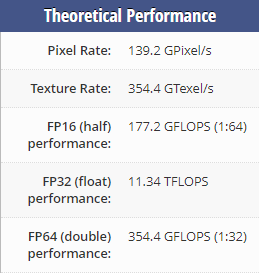
2080Ti:
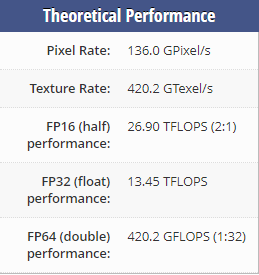
Take my words with a grain of salt though as this article claims to have gotten ~20% faster training with mixed precision training on a 1080Ti too. Also, there was a paper posted here that suggested not to go over 32 batches: The "BS<=32" paper
I’m curious to know your opinion about this matter because it’s a little bit confusing.
iiiinteresting  I’m no expert in this to be honest. Possibly its the case the FLOPS don’t correspond to memory usage? My understanding was that fp16 allows you to fit more data in RAM and so allow you use large batches
I’m no expert in this to be honest. Possibly its the case the FLOPS don’t correspond to memory usage? My understanding was that fp16 allows you to fit more data in RAM and so allow you use large batches
That’s true, it’s stated in the article I linked to. The question is do higher batch sizes maintain training quality? The paper in the BS<=32 thread claims that a batch size higher than 32 generally leads to worse accuracy and loss. I tried using fp16 to train a modified Stanford cars dataset and also noticed a 20% increase in training speed. I can’t document my test however because for some reason all of my data disappeared from my paperspace notebook. I’ve sent them an email to see if the data can be recovered. I was using the Efficientnet b3 + Mish and Ranger combo you used in notebook 9 in your stanford-cars repo.
Update: I’ve tried .to_fp16() on a P5000 instance on paperspace and got ~2.5x slower training compared to nothing after defining the learner and about 20% slower training time on Google Colab with GPU set as hardware accelerator. My advice? Run an epoch on fp16 and another without it and see if there’s a difference in speed. I’ll look more into this tomorrow. Please note that I did not increase the batch size (32) when I used fp16. I hope I’ll have a comprehensive test up by the end of the weekend.
Thanks for testing! Would love to hear how fast it trains when you max out the batch size with fp16
I’m getting predictions that have confidence 5.x and 6.x when I predict things with my model trained with your notebook 9 method. Do you know how I can fix that? I just used load learner and have a ranger.py and mefficientnet in the same dir as the predictor python script.
What do you mean by 5.x or 6.x?