@morgan I have read about the links you have posted! Like what Jeremy says, the best practitioner are the one who are persistent.
How is the results with these new techniques?
@morgan I have read about the links you have posted! Like what Jeremy says, the best practitioner are the one who are persistent.
How is the results with these new techniques?
Hmmm the jury is still out. EfficientNet seems to be much more stable using ranger and rangerlars instead of RMSProp, but I’m not sure I can match the accuracy of the paper’s b3 model (93.somthing%).
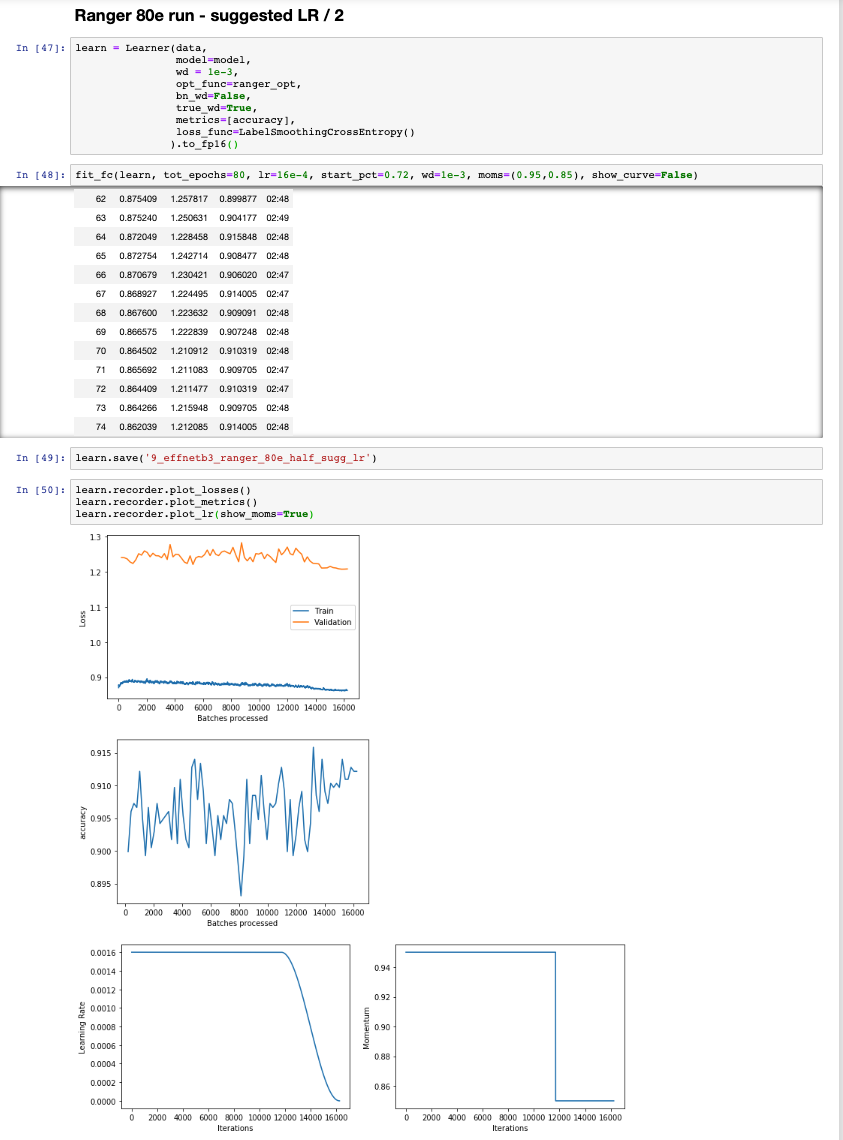
I’m doing some 80epoch runs with a flat to cosine anneal lr and it seems to get slowly better, but still maxing out around 91.2% with ranger. I think I’ll have to go to 150epochs+ just in case its just a matter of brute force and time.
Just playing around with when the anneal starts as they seem to improve once the annealing period kicks in…also need to figure out what to drop the momentum to.
Once I have a baseline for ranger I’ll try rangerlars, and then Mish
This is my latest run:
Why did you choose such scheduling is it suggested by the paper?
@jianshen92 We found in the imagenette/woof experiments that this form of scheduling showed the best results. One cycle was blowing everything up too quickly, and Grankin created this flat cosine annealing function which saw a dramatic increase in accuracy.
@muellerzr I found out the thread where you guys talked about it, great stuff! I guess OneCycle will be suitable with only vanilla Adam for now. Might be completely replaced when newer optimiser becomes the standard i guess?
Exactly as @muellerzr said  Quick (dumb?) question for you both @muellerzr, @jianshen92 , when you are training are you using the fulling training set for training, with the test set as validation? Or are you splitting your train set into train + validation, keeping the test set only for a final evaluation after training is complete?
Quick (dumb?) question for you both @muellerzr, @jianshen92 , when you are training are you using the fulling training set for training, with the test set as validation? Or are you splitting your train set into train + validation, keeping the test set only for a final evaluation after training is complete?
@morgan when we’re running the imagenette/woof tests the test is the validation set for us. (It’s how Jeremy set it up in the example notebook)
@morgan I asked the exact same question to myself. I think for research purpose it is okay to use test set as validation set. For the stanford car dataset in the competition I entered, i thought it would be “cheating” to use the test set as validation, although not specified.
Is the fit_fc function new in the library? I can’t seem to find it in the current version (1.0.57) library that I am using.
@jianshen92 run !pip install git+https://github.com/fastai/fastai.git to grab the most recent version to grab the absolute newest version to use it
Thanks both, I had been splitting the train set, but I think I’ll switch to using the test set for validation. I copied it from that crazy thread, but great that its being pushed to fastai, nice! 
I think if you want to compare the performance with other researcher (outside of fast.ai), it would be more accurate with an independent test set that is not used to benchmark your training. Being said im not sure how it is done when researcher report their results for benchmark dataset (imagenet etc.). @muellerzr do you have any insight for this?
Generally how I do it is I use the labeled test set ‘trick’ that I found and I report two scores. A validation accuracy and a test set accuracy. If you do a search for labeled test sets on the forum and filter to responses from me you should be able to find the source code for my technique
Thanks @muellerzr, nice tick, posting one of your answers here for future reference:
I had been wondering the same @jianshen92, I don’t think I recall reading a paper where they specify whether or not they used the test set as validation. So I never new if it was just taken as a given or not…
For another example of them doing that, look at IMDB and how we train it. Jeremy does the same thing
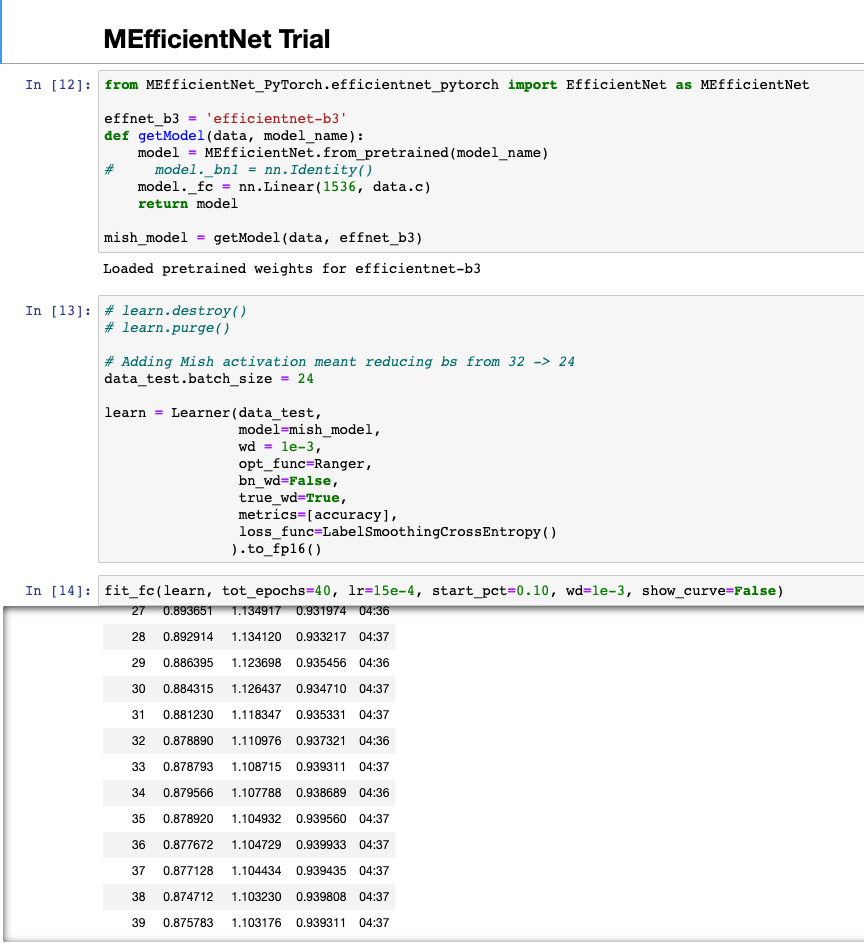
Positive signs with Ranger + Mish for EfficientNet-b3, 1-run test set accuracy of 93.9% for Stanford cars with EfficientNet-b3 after 40e. Their paper quoted 93.6% for b3. Note I’m training on the full training set here, using the test set for validation.
I didn’t play around with the hyperparameters at all, just took what seemed to work well for Ranger:
40 epoch
lr=15e-4
start_pct=0.10
wd=1e-3,
Will kick off 4 additional runs so I can get a 5 run average, but its slow going, 2h20m per run
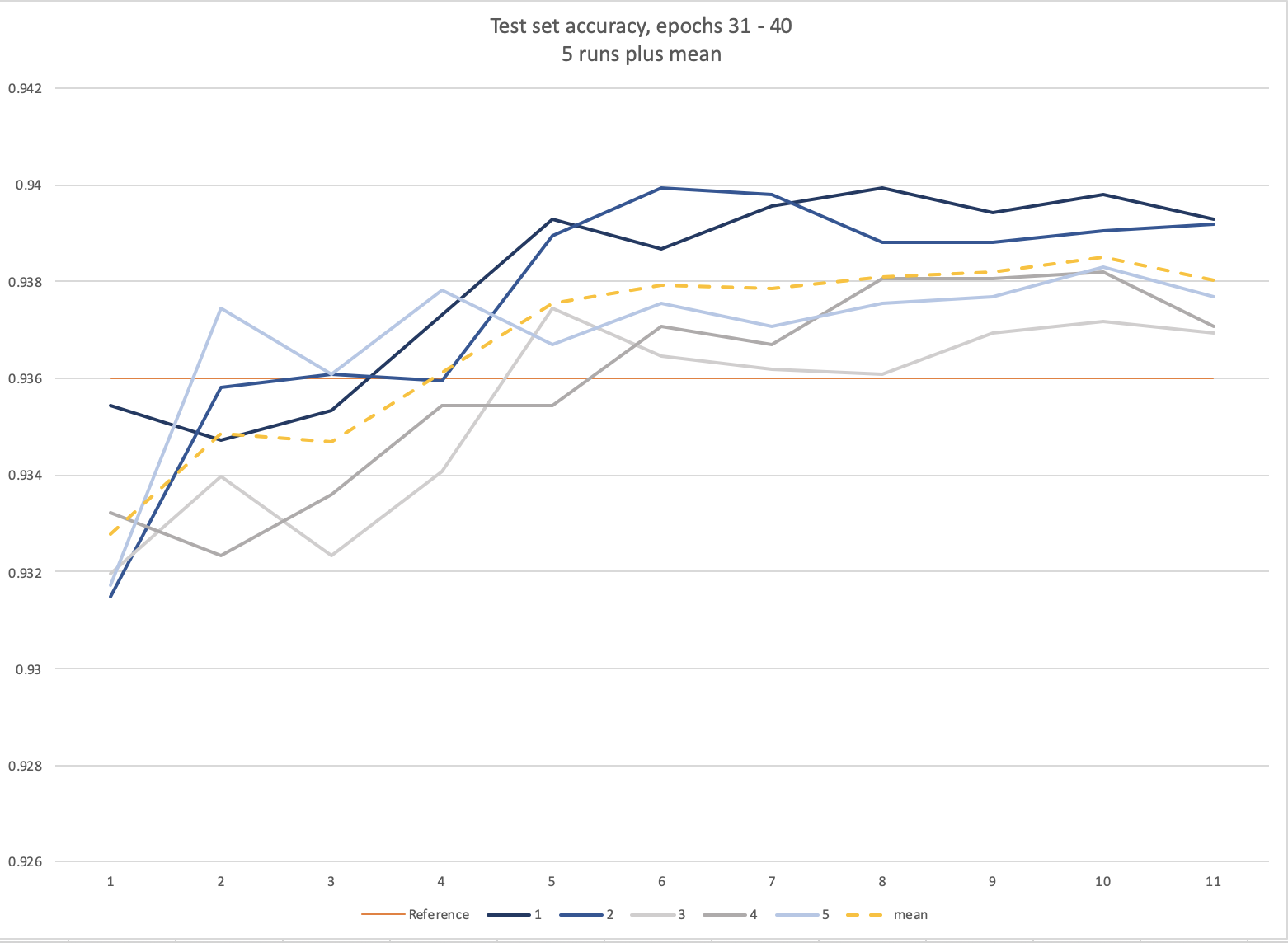
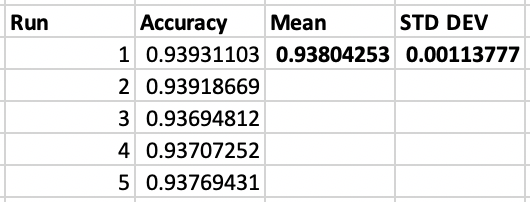
Ok, finally got through running the model 5 times!
TL;DR
Quick Medium post here, my first post, feedback welcome!
Mean accuracy and standard deviation:
Validation set (=test set) accuracy, last 10 epochs:
Default Ranger params were used :
Hello, in you code I didn’t find any information about how to create EfficientNet with Mish, could you please give me more details about it? Thank you!
Hello, in you code I didn’t find any information about how to create EfficientNet with Mish, could you please give me more details about it? Thank you!
Oh yep of course, I just replaced the relu_fn in the model.py file in the EfficientNet_PyTorch with the below:
def mish_fn(x):
return x *(torch.tanh(F.softplus(x)))
Easy!
For anyone that wants to go for more than b3, I found out that layers for others are:
b4 - 1792
b5 - 2048
b7 - 2560
If you want to change on model._fc