Can anyone please tell me how are you guys able to make the databunch because i cant get the classes right because class 1 is supposed to be hummer SUV where as in the images its actually some audi sedan here are the images.
Here are the classes:
Thanks for quoting @morgan. This project was an entry to an AI challenge by Grab, which is the Uber here in Southeast Asia. This submission made it to the top 50, so I’m very grateful for Jeremy and team for creating this library!
Happy to answer any questions regarding my notebook!
Hey @jianshen92, in your notebook above was there a specific reason you trained your model in bursts of 5 epochs? Instead of maybe just doing fit_one_cycle for 25epochs for example? It seems to have worked well so I’m just curious if there is a little trick that I don’t know about
@morgan It is something I found out empirically and I have no strong mathematical explanation for this
When I was experimenting I trained every cycle with 5 epochs because I wanted to try to tune the parameters after every checkpoint to see if the model will improve further without waiting for too long.
One thing for sure though, fitting one cycle for many epoch vs fitting many one_cycle with less epoch, is not exactly equivalent, because of the cyclic momentum and cyclic learning rate within a cycle. Perhaps fitting it for many cycles enable it to search deeper to the hyperspace’s minima because of the multiple cycle of increasing and decreasing learning rate.
Nice! I get the practicality of it, I’ll be sure to remember to try it in other projects! I’m trying to run your notebook now, starting with Facebooks’s ResNext 101 WSL model (trained on 840m Instagram images and fine-tuned on Imagenet) weights, but I’m hitting OOM errors at the moment. Will keep trying reducing the batch size and/or use a smaller model version
I tried with ResNext too but just with the one provided by torch.vision. End up not using it because improvements are very minimal, like .05 % increase in accuracy but train much longer.
Updating progress here, current accuracy at 93.29% (with TTA), 93.19% without. Using the SQUISH resize transform as well as paying more attention to the LR at each stage really helped here!
Thanks! Yep I just started playing around with EfficientNet to see how close I can get to their SOTA on stanford cars. EfficientNets seem tricky to train though, have you tried them? will keep playing around
Thats awesome! Can you describe abt what you mean by “paying more attention to the LR at each stage really helped here!”? What did you observe and then change?
Thanks @bluesky314, just that I trained for a smaller set of epochs (5 or sometimes 10) and then ran lr_find() again to see if it suggested I needed to change the learning rate, I more or less copied how @jianshen92 had done it
Haven’t tried the EfficientNet, haven’t been working on this project ever since the competition has ended. I admire your perseverance on this!
Recently there is this Radam and LookAhead optimizer that just came out and the community almost says that it guarantees improvement in accuracy and allows us to use a higher learning rate. I think it is worth a try!

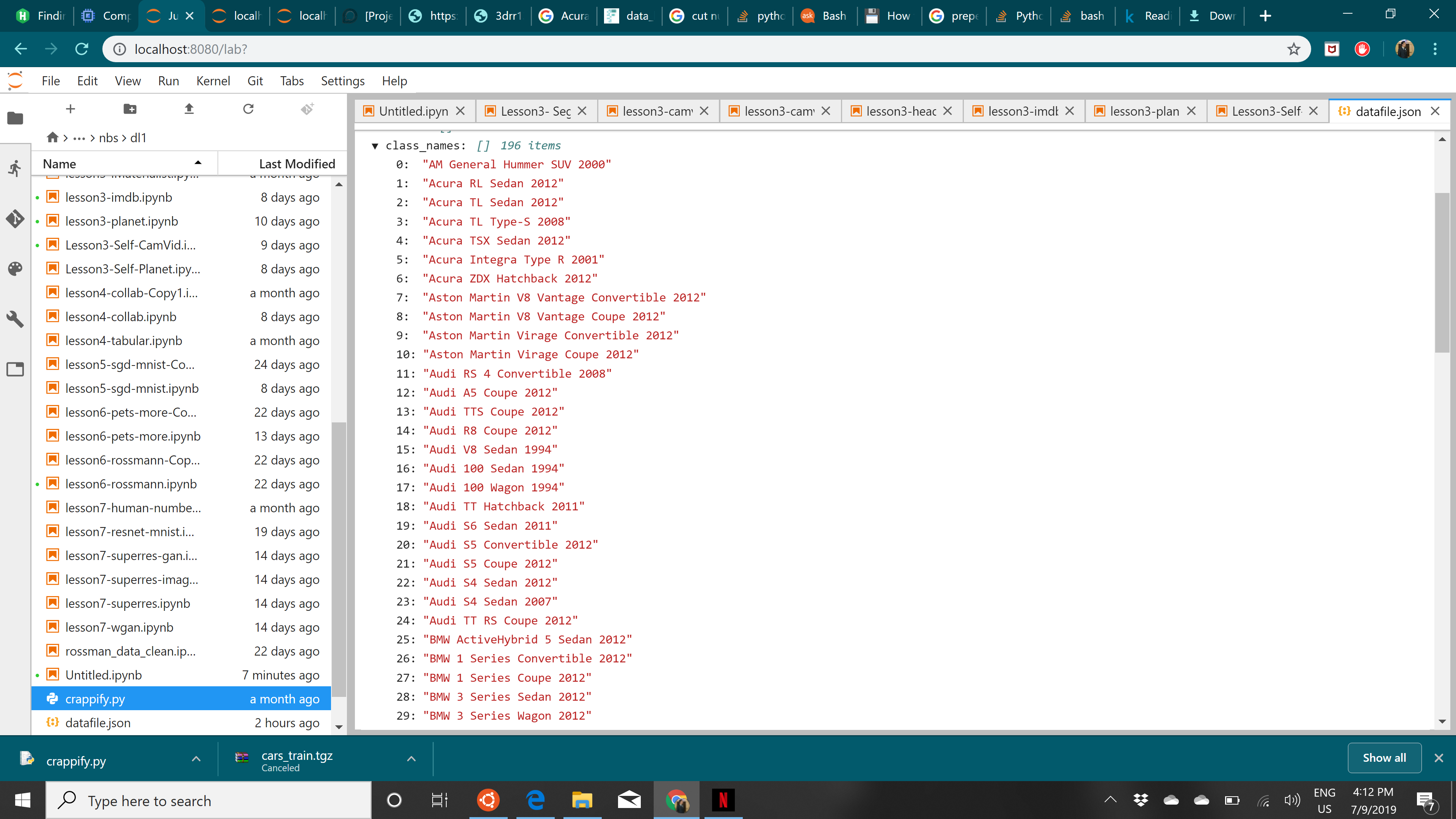

 ) which should help with your data import :
) which should help with your data import :
