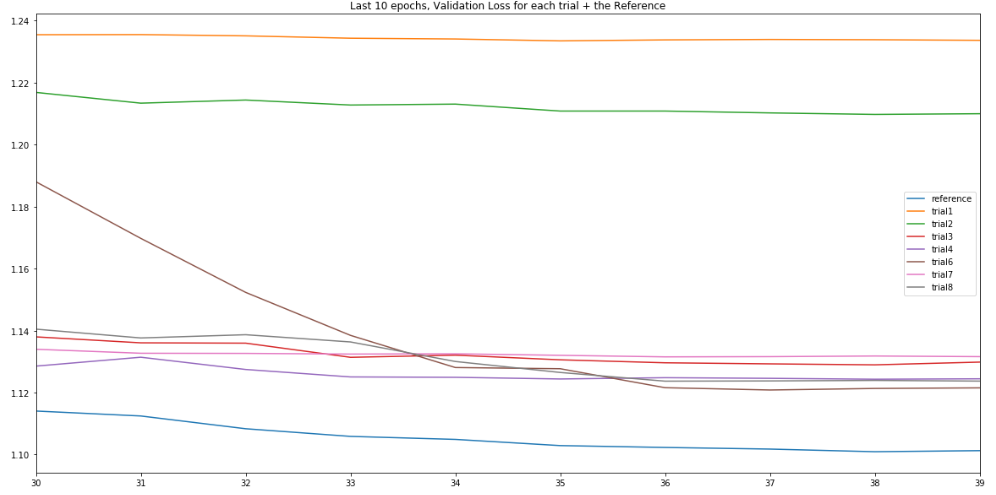
@LessW2020 I’ve been running some trials with Ranger913A over the past few days with EfficientNet-b3 + Mish on Stanford-Cars. Overall I found it matched the accuracy of “vanilla” Ranger but didn’t beat it. It also needed a higher lr (10x) than Ranger and was about 15% slower to run.
If there are 1 or 2 other parameter configurations you feel are worth exploring then I can probably make time to trial them, however in general with Ranger913A and Ranger I’ve found 93.8% to be a hard ceiling with b3, although I have seen 93.9% after adding Mixup.
All results are in the “Ranger913A” notebook here: https://github.com/morganmcg1/stanford-cars
Results
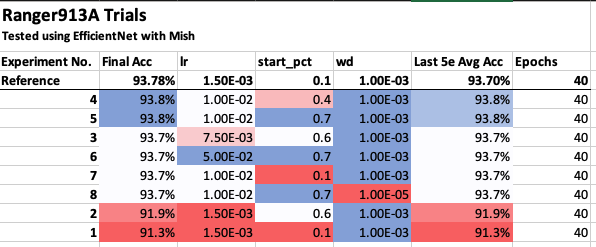
Accuracy, last 10e (full 40e plots in the notebook)
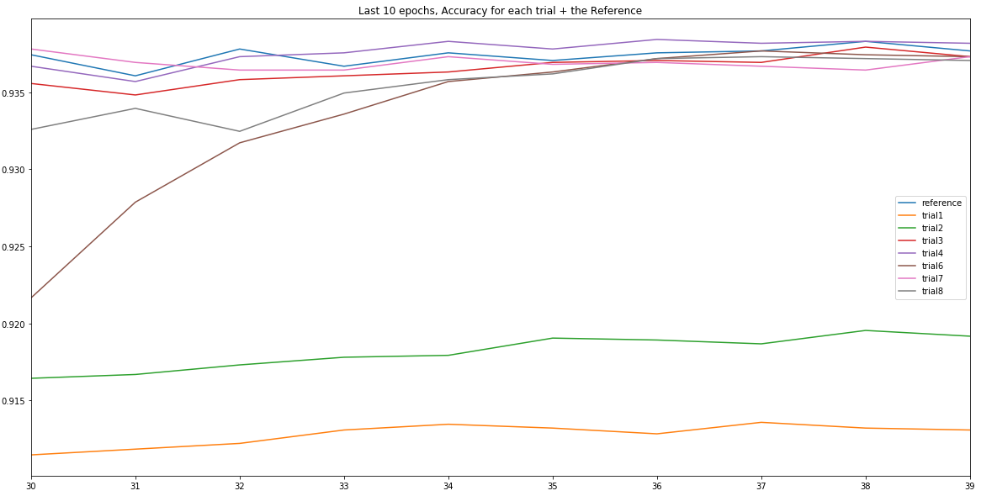
Validation loss, last 10e
@mmauri I have a look at my repo above, and my other results with EfficientNet + Mish + Ranger: [Project] Stanford-Cars with fastai v1
Its not on Imagenette/Imagewoof but I’ve found Mish + Ranger to be super helpful. Also, myself and @ttsantos are working on a PR for the efficientnet_pytorch library to allow you to toggle the activation function between Mish, Swish and Relu…