It’s only faster when the GPU processes fp16 faster than fp32. For example:
P4000:
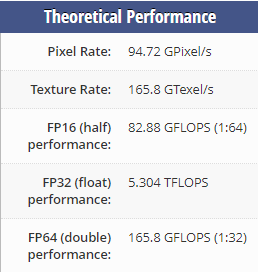
1080Ti:
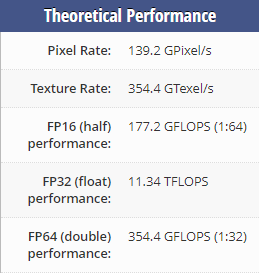
2080Ti:
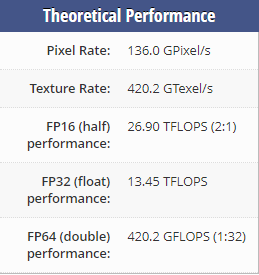
Take my words with a grain of salt though as this article claims to have gotten ~20% faster training with mixed precision training on a 1080Ti too. Also, there was a paper posted here that suggested not to go over 32 batches: The "BS<=32" paper
I’m curious to know your opinion about this matter because it’s a little bit confusing.