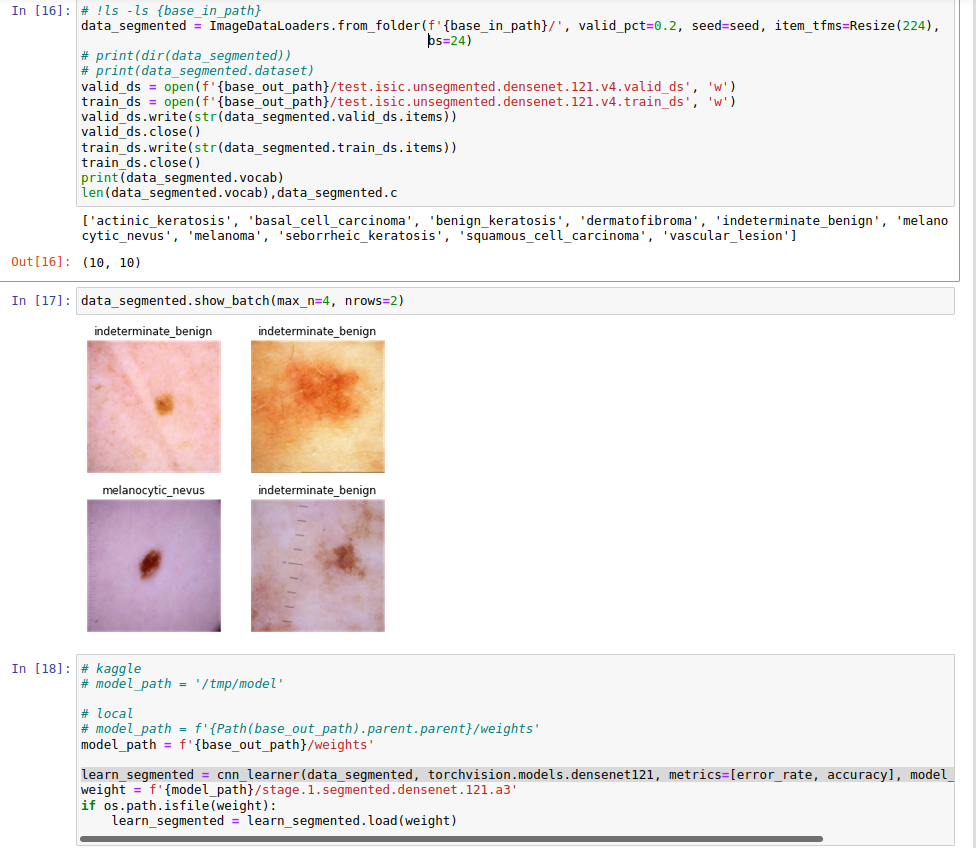
@muellerzr I have now tried v2.5.1, with below fix and it worked ok
@classmethod
def from_learner(cls, learn, ds_idx=1, dl=None, act=None):
"Construct interpretation object from a learner"
if dl is None: dl = learn.dls[ds_idx].new(shuffled=False, drop_last=False)
# return cls(dl, *learn.get_preds(dl=dl, with_input=True, with_loss=True, with_decoded=True, act=None))
return cls(dl, dl.dataset.items, *learn.get_preds(dl=dl, with_input=False, with_loss=True, with_decoded=True, act=None))
# new Interpretation.plot_top_losses in fastai/interpret.py
def plot_top_losses(self, k, largest=True, **kwargs):
losses,idx = self.top_losses(k, largest)
if not isinstance(self.inputs, tuple): self.inputs = (self.inputs,)
if isinstance(self.inputs[0], Tensor): inps = tuple(o[idx] for o in self.inputs)
# else: inps = self.dl.create_batch(self.dl.before_batch([tuple(o[i] for o in self.inputs) for i in idx]))
else: inps = (first(to_cpu(self.dl.after_batch(to_device(first(self.dl.create_batches(idx)))))),)
b = inps + tuple(o[idx] for o in (self.targs if is_listy(self.targs) else (self.targs,)))
x,y,its = self.dl._pre_show_batch(b, max_n=k)
b_out = inps + tuple(o[idx] for o in (self.decoded if is_listy(self.decoded) else (self.decoded,)))
x1,y1,outs = self.dl._pre_show_batch(b_out, max_n=k)
if its is not None:
plot_top_losses(x, y, its, outs.itemgot(slice(len(inps), None)), self.preds[idx], losses, **kwargs)
#TODO: figure out if this is needed
#its None means that a batch knows how to show itself as a whole, so we pass x, x1
#else: show_results(x, x1, its, ctxs=ctxs, max_n=max_n, **kwargs)