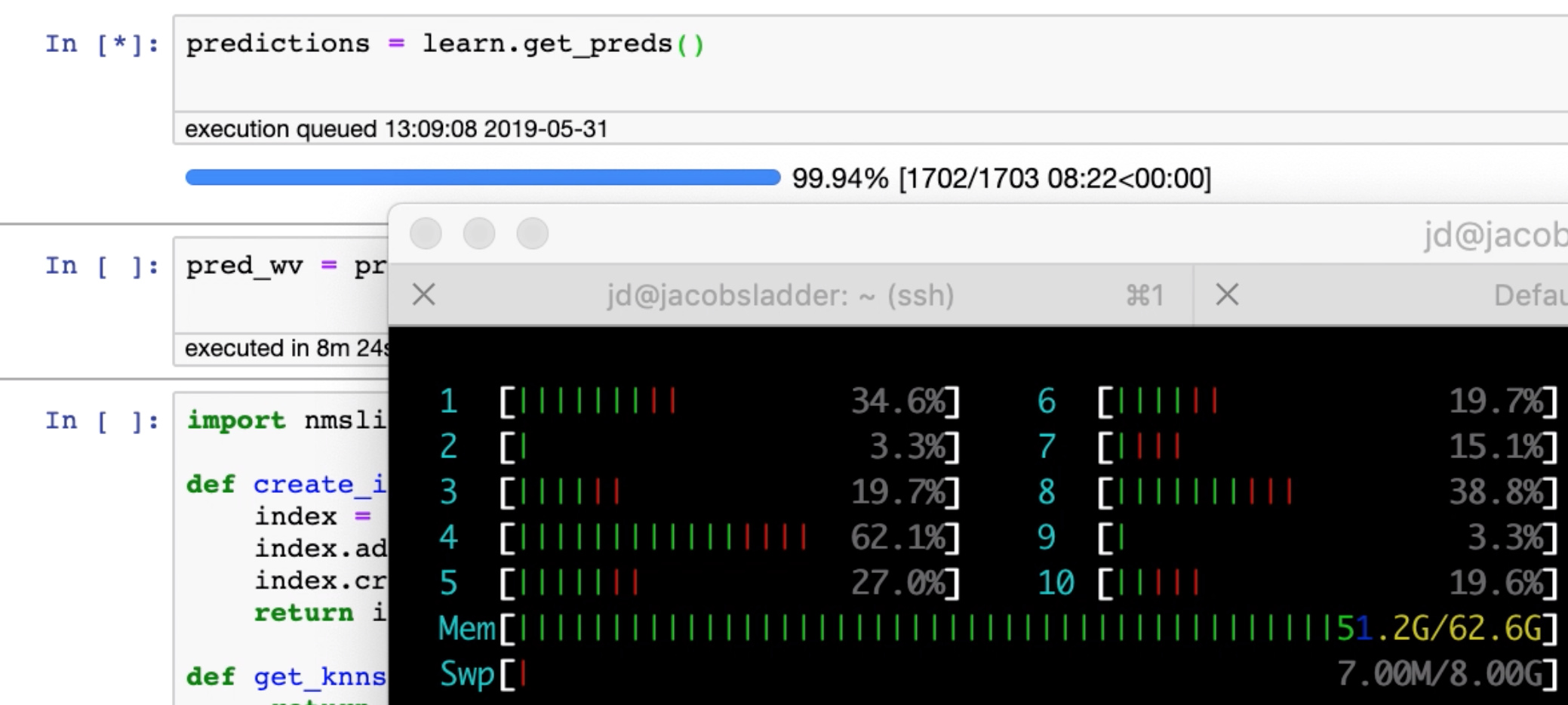
I believe during get_preds I am running out of memory (62.6 gigs). Not sure if it is just a spike in memory usage at the end but does anyone have an idea how to fix?
I got the error [enforce fail at CPUAllocator.cpp:56] when I looked it up on google it appears that there is a problem with CPU memory. Sure enough, I was able to see the problem right at the end. I am using the predictions with nmslib to create a KNN for similar images so I would like to keep all the data. Not sure why it punted to CPU, but my GPUs have less than 51G, so I don’t see that as a way to solve.
I think my hacky fix would be to reduce the number of files I am predicting against.
Screenshot of running out of memory at the end:
Full error below:
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-24-9aa6c3114742> in <module>
----> 1 predictions = learn.get_preds()
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in get_preds(self, ds_type, with_loss, n_batch, pbar)
335 lf = self.loss_func if with_loss else None
336 return get_preds(self.model, self.dl(ds_type), cb_handler=CallbackHandler(self.callbacks),
--> 337 activ=_loss_func2activ(self.loss_func), loss_func=lf, n_batch=n_batch, pbar=pbar)
338
339 def pred_batch(self, ds_type:DatasetType=DatasetType.Valid, batch:Tuple=None, reconstruct:bool=False) -> List[Tensor]:
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in get_preds(model, dl, pbar, cb_handler, activ, loss_func, n_batch)
42 "Tuple of predictions and targets, and optional losses (if `loss_func`) using `dl`, max batches `n_batch`."
43 res = [torch.cat(o).cpu() for o in
---> 44 zip(*validate(model, dl, cb_handler=cb_handler, pbar=pbar, average=False, n_batch=n_batch))]
45 if loss_func is not None:
46 with NoneReduceOnCPU(loss_func) as lf: res.append(lf(res[0], res[1]))
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in <listcomp>(.0)
41 activ:nn.Module=None, loss_func:OptLossFunc=None, n_batch:Optional[int]=None) -> List[Tensor]:
42 "Tuple of predictions and targets, and optional losses (if `loss_func`) using `dl`, max batches `n_batch`."
---> 43 res = [torch.cat(o).cpu() for o in
44 zip(*validate(model, dl, cb_handler=cb_handler, pbar=pbar, average=False, n_batch=n_batch))]
45 if loss_func is not None:
RuntimeError: [enforce fail at CPUAllocator.cpp:56] posix_memalign(&data, gAlignment, nbytes) == 0. 12 vs 0