Consider you want to pretrain a model with max_sequence_length=512, but avrage length of your corpus is about 100~200. And you think you would like to concatenate sentences to full use the max sequence length and get a broader context for prediction.
Here comes the TextDataloader, which is able to use a sliding window over tokens or sentences, and deal with bos(CLS) and eos(SEP) token as you want.
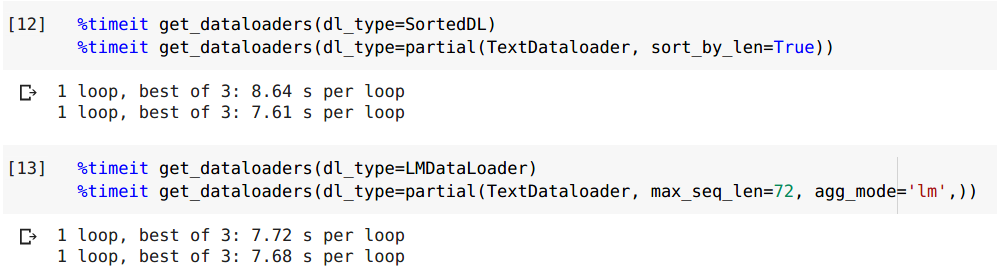
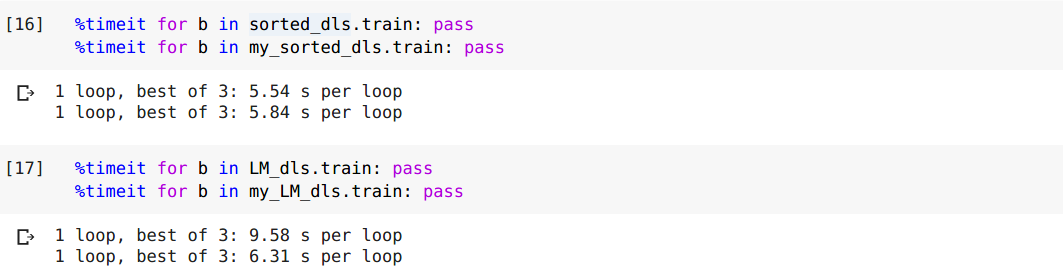
Also it is a general dataloader, you can use it as SortedDL or LMDataLoader.
See more examples and try it with this notebooks.
Examples:
(Note that these are just examples, we can deal with bos and eos in other ways we want)
Lines mode: sliding window over sentences

Window mode: sliding window over tokens

Question / Help
- Is every sample used in BERT, RoBerta, Electra,…, always have only a CLS at the head and a SEP at the tail, no matter how long it is and whether it is concatenation of tokens or lines? Only when finetune on GLUE will CLS…SEP…SEP appear ?
- Is there more efficient implementation ?
- Try it on your / other problem to see if there is any problem.
Follow the series.
Help me in this thread tag someone might be interested in or could help !
Also follow my twitter Richard Wang for update of this series.
(Spoiler alert: cache the dataset, prepare GLUE data, single/multi task training on GLUE is in the line !!)