I created callbacks for masked language modeling and replaced token detection (Electra). Please help me test / check / improve the code, and also I am seeking a chance to PR to fastai2.
Hows the progress going with ELECTRA? Would love to see it working, I might have time to look at it in a couple of weeks
A few questions, maybe you’ve thought of them already:
Are you loading randomly initialised weights? The authors found that loading pre-trained weights didn’t perform so well
Your generator DistilBERT is super small (1 layer), maybe it can’t learn anything useful…the authors found in their setup that a generator of half the discriminator size worked best (so with DistilBERT that would be 3 layers for the generator I think?).
Did you consider using ALBERT-base? It looks like it only has 11M params vs 65M for DistilBERT-base. You could even use ALBERT-base (11M) -> ALBERT-large (17M) for your gen->discrim setup? (Param sizes mentioned here)
Are you loading randomly initialised weights? The authors found that loading pre-trained weights didn’t perform so well
I did load pretrained weights. Thanks for your info, it makes me wonder if different pretraining objective makes different representation that can’t be use by each other.
Your generator DistilBERT is super small (1 layer), …, the authors found in their setup that a generator of half the discriminator size worked best .
Thanks for your comment, I quickly reexamine Electra paper and config. As far as I understood, I found two things.
As figure 3 shows, the authors might want to say generator hidden size is better to be 1/2 * discriminator hidden size. Although I found config in github use 1/4, but refer to the graph, it seems make no big drop on acc but saves time and params.
According to config. Generator will have the same number of layers as discriminator but with small hidden size.
Did you consider using ALBERT-base? …
I might have seen a graph saying weight sharing transformer (Universal Transformer and ALBERT ), although have far smaller params, but have more computational cost than non-weight sharing one. (Sorry I didn’t found the graph.) But we might think one layer of ALBERT if larger than one layer of BERT, so run a ALBERT layer 12 times will cost more than run through 12 BERT layers.
I will update the setting in notebook according to config in ELECTAR repository tomorrow. By the way, I think I should use the newly released Electra in Transformers (Although no pretrained weights now?).
I would like to test it with a reasonable setting but the only GPU available for me now is Colab , so I am thinking if someone could help me try this callback. Or I would need to train a 6.25% trained ELECTRA-small by myself after I finish my work in hand…
It seems that I can’t edit my original post, so post the updates here. All updates is reflected in the original notebook.
==== 2020/05/17 ====
Use Electra pretrained model (with pretrained weights) instead of original distillbert
Normal result when using fp16, it seems because of the change the above point.
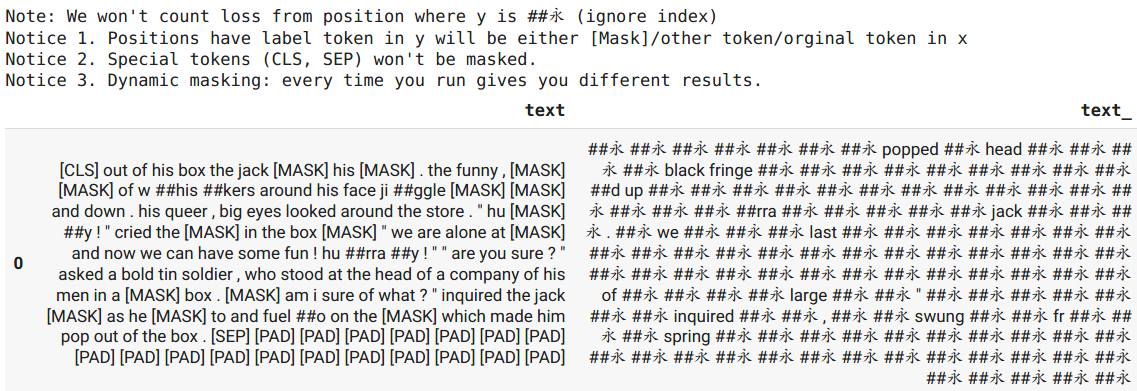
Print masked input and label for easier understanding for MLM callback
Use TextDataloader introduced here for broader context. (which may make you load more tokens a batch than original paper but I haven’t figure out how they load their data.)
Stick to papaer’s hyperameter
use google/electra-small-generator and electra-small-discriminator pretrained model config, so we should be correct about the model part (including number of layers) .
batch_size == 128
scale discriminator by 50
Please let me know if there’s other differences from the original implementation.
Note: The accuracy is about 7%. I don’t know if it is normal, nobody has reported “MLM acc” after all. And I am waiting huggingface/nlp to solve issue #148 so I can try it on wikipedia corpus (where the pretrained model is trained on) instead of simplebook corpus (which have many children stories so mabye a discrepancy in these data ?).
Note: You may not be able to view the notebook on github (I don’t know why, maybe it takes time), but you can download and open it locally.

 , so I am thinking if someone could help me try this callback. Or I would need to train a 6.25% trained ELECTRA-small by myself after I finish my work in hand…
, so I am thinking if someone could help me try this callback. Or I would need to train a 6.25% trained ELECTRA-small by myself after I finish my work in hand…