We follow the hyperparamter of ELECTRA paper (Table 7), and its official implemenation of linear warm up and decay, to train the MRPC dataset.
Finetune_GLUE_with_fastai.ipynb
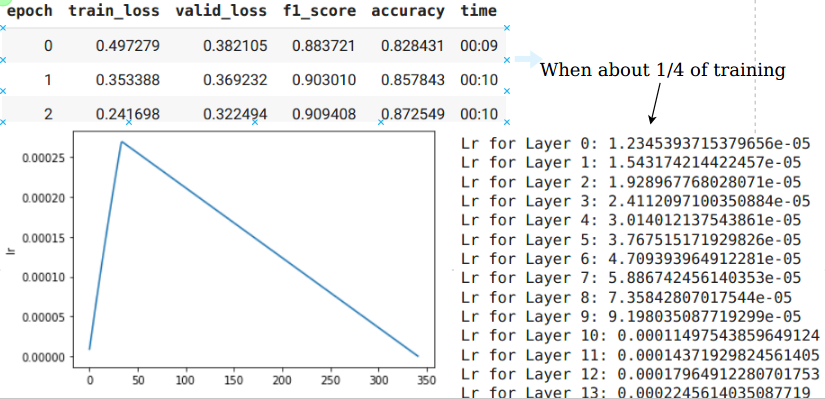
Note
- One cycle seems (didn’t run many times) to perform very similarly, with the same learning rate’s’ under default setting (pct_start…).
- According to the lr schedule of official implementaion , it is not two phase lr shedule, but do both warmup and decay at the same time. My understanding is it is equal to this
lr = (lr-end_lr)*(1-step/total_steps)**1 + end_lr
lr = lr * min(1.0, step/total_warmup_steps)
so warm up has no effect after warming up, decay has little effect in the early phase. If you know some tensorflow, please correct me if I am wrong !!
“Pretrain MLM and fintune on GLUE with fastai”
Previous posts.
-
TextDataLoader - faster/as fast as, but also with sliding window, cache, and bar
-
Novel Huggingface/nlp integration: train on and show_batch hf/nlp datasets
Also follow my twitter Richard Wang for updates of this series. In the end of series, we’ll try to reproduce the result of ELECTRA from scratch with fastai.
(Spoiler alert: multi task training are on their way !!)