Thanks @fgfm for confirming this! At least now we know what was going on with that.
Re cosine annealing I was using flat run and then cosine annealing (credit to @grankin for that improvement).
Thus what I mean was by waiting until .75 of the run was complete before starting the cosine decay, I got better results instead of starting cosine at .5 of the run.
Im going to make a quick repo so everyone can try the new setup with Ranger Mish and flat cosine decay, and to put in the pull request to add our new high score for 5 epochs.
@LessW2020 interested to hear about AutoOpt! Just looked at the code. I may try myself (just for practice as it seems very hefty for the callback system).
Also just saw your fix… trying a small experiment… large improvements on first epoch
The reason behind it might be obvious, but it’s quite a significant difference! I wonder if it’s a common mistake. I ran some tests on Imagewoof and will start a new thread.
One quick question. Moreso a conceptual. So top_k, why are we examining this overall? I understand it’s a good baseline for how the model is generally fitting (eg is it ‘close’ to the right answer) but we generally only care about the final accuracy correct?
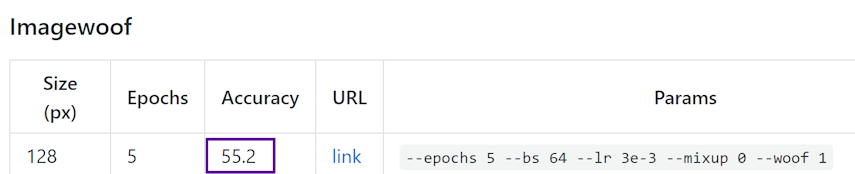
Top k=5 accuracy just happens to be in our code because it is used for Imagenet (1000 classes). Here we have 10 classes only, so I would ignore it or remove it.
Ah got it I may keep it in with a k=2-3 perhaps. But I hear your point. Thanks! I also tried adjusting my betas and tried a new eps, I did notice less volatility in the small-scale tests (train_loss and valid_loss were much much closer)
I’ve got the new repo about all setup so we can add the link.
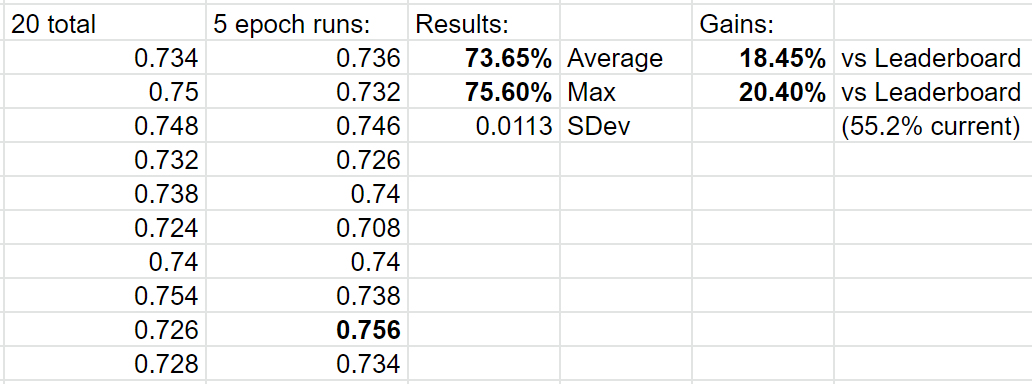
I ran one more 5 run to make it an even 20 and make sure the repo setup works for anyone to test with:
It is! I saw your sneaky modification with the betas and an eps of 1e-8, and tried that (even though different optimizer, why not?) Wound up showing some potential at the very least
That’s why I said I may need a little bit. I’m playing around with the right ranges for each. Currently running a baysian optimization so perhaps it can help with that easier. If you want some code to do this as well let me know, I have fastai starter code
I figured I’d try adding SimpleSelfAttention since it did well in my previous tests with Imagewoof128 (better accuracy on ~100 epochs when constrained by run time - edit: that was with xresnet18). For some reason not on Imagewoof256 but that’s another story.
I imagine it might like the different lr scheduler.
Wow, that’s fantastic - new high on both average and Max (76.8)! Nice job @Seb!
A second or two extra compute is completely worth it.
Only problem is now you messed up my halfway complete post about how we beat the leaderboards…let me run a set as well and I’ll update everything and hopefully you can expand on the SA aspect.
(Jeremy had asked that I make a post explaining what was going on with our new records with Ranger/Mish/FlatCosine anneal for people to catch up with).
The ~ 100 epoch is a previous test (link at the bottom of my other post). I had ran 94 epochs for xresnet18+ssa and 100 for xresnet18 to get the same duration and beat xresnet18 by 0.75%.
I may try with RangerLarsif that’s alright? Or if you want to? I found some hyperparemeters that show stable decent results if you want to try them (unsure how they’ll back apply to you):
Go for it. I might not be around much for a few days.
My only issue with Over9000 is run time. Eventually I’d like to sort through all those additions and see which ones gets to high accuracy the fastest. Maybe we could have a leaderboard on fastest run to 87% on Imagewoof128 with 1 GPU.

 I may keep it in with a k=2-3 perhaps. But I hear your point. Thanks! I also tried adjusting my betas and tried a new eps, I did notice less volatility in the small-scale tests (train_loss and valid_loss were much much closer)
I may keep it in with a k=2-3 perhaps. But I hear your point. Thanks! I also tried adjusting my betas and tried a new eps, I did notice less volatility in the small-scale tests (train_loss and valid_loss were much much closer)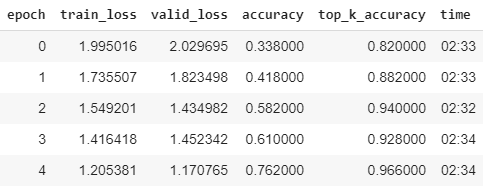
 (I’ll have full results of new test here in the next 15 minutes)
(I’ll have full results of new test here in the next 15 minutes)