Im pretty sure we’ve all been training from scratch in this thread. Let us know if you get some interesting results!
First run with 80 epochs, Adam+Mish = 85.2%. The only comparison I have is the leaderboard at 86.2%.
–woof 1 --size 128 --bs 64 --epoch 80 --gpu 0
–opt adam --lr 1e-2 --mixup 0.2
1 Like
I saw slightly worse results on 5 epoch with RangerLars vs Ranger:
[0.682 0.684 0.674 0.648 0.644]
0.6664
0.017036434
Hi @fgfm,
Thanks for the kind words!
Re: training - 100% from scratch.
That will be great if you are able to test some frozen ReLU + unfrozen Mish - however, I suspect the impact won’t be that great.
The reason Mish works well, at least as best I can tell, is b/c the smoothness of the activation function allows it to propagate information deeper into the network vs ReLU.
Thus, only using it on the last two layer’s won’t take advantage of that property.
That being said, we don’t know until we know so if you are able to test, that would be great. And agree, nice if we can leverage off the trained networks!
Thanks for the initial results! If I had to guess, your learning rate is likely too high? 3e-3 seemed to work better for me with Ranger at least, and the paper recommends lower learning rates with Mish vs ReLU.
That said - AutoOpt code just got released so I’m going to test that + Mish and see how that goes…this way we get out of the learning rate tuning game if AutoOpt works as hoped!
1 Like
For some reason Jeremy picked a higher lr with Adam when increasing # of epochs, so I went with that. Who knows. I’ll run ReLU at the same lr and we can see from there.
1 Like
Second run 86.2%… Still so much variance even after 80 epochs!
1 Like
I’ve started the 20 epoch runs now. I’m repeating 20 times just to be sure on the test. I will run baseline once that is finished.
1 Like
Had to scratch it… having some odd issues right now. Taking a step back and re-running the earlier work I posted above just to double check
Fixed issue… used new version by accident Lesson learned. Back up your own source code you used 
Current experiments running:
For 20 epochs 5 times
- Adam + Mish
- Over9000 (Old version) + ReLU (Standard xresnet50)
- Over9000 (Old version) + Mish
I’ll update in 3-4ish hours with the results
1 Like
Got my runs saved here: https://github.com/sdoria/over9000/blob/master/ImageWoof%20-%20ReLU%20vs%20Mish.ipynb
I should have put those results in a side by side comparison table, but there ya go:
Adam + OneCycle + ReLU
Last epoch accuracy:
[0.856 0.874 0.852]
mean 0.8606
Best accuracy:
[0.858,0.874,0.858]
mean 0.8633
Best val loss:
np.mean([0.843949, 0.836848, 0.864064]) = 0.8482
Best train loss:
Around 0.86
Best epoch number (for accuracy):
75,76,71
Adam + OneCycle + Mish
Last epoch accuracy:
[0.852 0.862 0.87 ]
mean 0.8613
Best accuracy:
[0.862,0.866,0.884]
mean 0.8706
Best val loss:
np.mean([0.880457, 0.86458, 0.829326]) = 0.858121
Best train loss:
Around 0.85
Best epoch number (for accuracy):
61,71,66
I don’t see a strong signal separating the two, would need more runs. Even using the average best accuracy we have p=0.35, which isn’t good.
Mish is slower per epoch in my experience (I would prefer if runs took the same amount of time overall); however the best accuracy comes 8 epochs earlier. It’s as if we could cut the last 10 epochs off, or adapt the learning rate scheduler.
Maybe a bit of overfitting towards the end of each run???
1 Like
Thanks Seb! Interesting results. I’m running 6 batches in the end. A set with 5 and a set with 20 epochs to see. I have a hunch *all at the same time
I’ll see how they compare to mine. But that’s certainly a very non-performing p value
In terms of time atleast:
5 epoch:
Adam + Mish: 2:12
Over9k + ReLU: 2:06
Over9k + Mish: 1:28
20 epoch:
Adam + Mish: 2:07
Over9k + ReLU: 2:06
Over9k + Mish: 2:30
Which is very interesting
Here comes the first three (my 5 epoch test):
| Adam + Mish | Over9000 + ReLU | Over9000 + Mish | |
|---|---|---|---|
| LR | 3e-3 | 1e-2 | 1e-2 |
| Time per Epoch | 2:12 | 2:06 | 1:28 |
| Acc1 | 68.4% | 68.2% | 72.2% |
| Acc2 | 70.8% | 69.4% | 73.8% |
| Acc3 | 67.4% | 68.6% | 74.6% |
| Acc4 | 73.4% | 69.4% | 74.0% |
| Acc5 | 72.2% | 66.6% | 70.8% |
| Mean | 70.44% | 68.44% | 73.08% |
| Std | 2.25% | 1.03% | 1.39% |
Things to note: that 73.08% is very nice. I did not see an improvement with 9000 + ReLU
Each were run five times. Do we need more repeats?
Notebooks are here:
- Will update with p value but 3% seems pretty strong. Actually @Seb or @LessW2020 how would we go about calculating those p values? (Been a hot minute since I took statistics)
3 Likes
*Fantastic testing @muellerzr!!
Just an update on my end that may help speed up things - Ranger is doing as well or better than RangerLars/Over9000:
1 - I was able to improve on the earlier score from @muellerzr but using Ranger, by tweaking the cosine annealing to .75 instead of .5, and as noted, using Ranger and not RangerLars.
RangerLars takes nearly 2x as long per epoch on my server (39 seconds for RangerLars, 24 seconds for Ranger). So I’m much more favorable towards Ranger due to that.
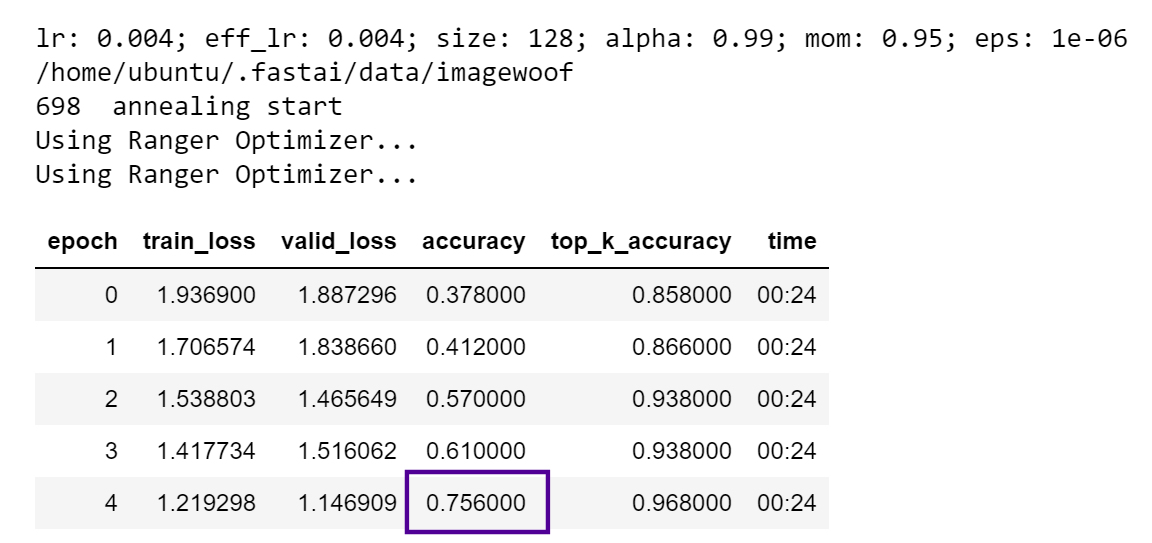
[0.708 0.74 0.738 0.756 0.734]
0.7352 average
0.756 peak (!)
0.01552288
[0.724 0.74 0.754 0.726 0.728]
0.7344 average
.754 peak accuracy
0.011271209
changes:
momentum =.95
anneal = .75
lr=4e-3
2 - There’s something else though. I couldn’t reproduce the RangerLars/Over9000 posted earlier results…so I finally downloaded the workbook and ran that. Then I could repro, but in chasing down the difference, it’s this:
If you use ImageWoof-160 and resize to 128, you will get worse scores than if you use ImageWoof and resize to 128.
There should be no difference, but there clearly is b/c I see about 2% difference just depending on which way I get to 128 images. I suspect there is improved resizing by doing it directly from ImageWoof.
i.e.
path = URLs.IMAGEWOOF_160
path = URLs.IMAGEWOOF #jump +2% in accuracy
3 - Re: OneCycle results - I’m pretty much of the opinion now after a lot of testing that OneCycle destroys most of the momentum that smarter optimizers and Mish build up. I continue to see much better results avoiding it, unless it’s with Vanilla adam and Relu. Then it seems to work well.
1 Like
@LessW2020 beat me by that much why don’t ya (Pretty sure we’re in the not statistically significant yet portion)
Just seeing what’s happening in my 20 epoch notebooks, I’m noticing some accuracy variability throughout training (Eg dropping from 79 to 72 then back up to 80ish) did you notice this behavior at all @LessW2020?
And that’s quite interesting to find about the imagewoof. All of my experiments were done using the base imagewoof, not resizes
For motivation - here’s that amazing peak score:
Someone just checked in a fix for Ranger, saying I was off by one, in the variance threshold vs the paper…let me run that right now and see if much difference.
1 Like
Definitely saw this, usually in the 12-16 epoch range. Overall though, I usually had relatively smooth curves otherwise.
I think this means we still don’t have a good grasp on the best lr setup for Mish.
related - I tried to get AutoOpt going but it’s not integrating well into FastAI…so I need to figure out how to give the optimizer access to the model itself.
No worries- I was mainly happy to see Ranger doing well b/c the compute time is so much better. vs. RangerLars I emailed Jeremy btw to see about getting the leaderboards for 5 epoch updated and referenced both of our results. ![]() and pointed him to this thread.
and pointed him to this thread.
I remember Jeremy talking about how they had improved the FastAI resize quality in one of the lessons (part 2) so that is likely where this comes from.
Note - I tested that check in fix for Ranger, and my scores immediately dropped a 2-3% even with some various tests…so I reverted back but made it a customizable param for initing Ranger now.
I ran one more set with Ranger after reverting to the original N_sma_threshold as well:
[0.736 0.732 0.746 0.726 0.74 ]
0.736
0.006811751
I’m calling it a day at this point though, burnt up a lot of money on GPU time today but hopefully we can get the 5 epoch leaderboard score updated with our work.
Thanks for the testing and work today!
1 Like
Definitely saw this, usually in the 12-16 epoch range. Overall though, I usually had relatively smooth curves otherwise.
I think this means we still don’t have a good grasp on the best lr setup for Mish.
related - I tried to get AutoOpt going but it’s not integrating well into FastAI…so I need to figure out how to give the optimizer access to the model itself.
I agree, probably needs some work and hyper analysis and fine-tuning. I may bring this up in my study-group in a few weeks when they’re ready and perhaps four+ brains can tackle how to handle it best ![]()
I emailed Jeremy btw to see about getting the leaderboards for 5 epoch updated and referenced both of our results.
and pointed him to this thread.
Perfect! ![]()
I’m calling it a day at this point though, burnt up a lot of money on GPU time today but hopefully we can get the 5 epoch leaderboard score updated with our work.
Thanks for the testing and work today!
We got some good work in! I’ve been using google colab, and while it does take a bit longer (and I also had 6 google accounts lying around) I highly recommend it if you want to save some $$$ (if you can afford the time to have constant access)
Last bit from me is I’m finishing up the 20 epochs runs. They should be finishing up here in the next 18 minutes, I will update this comment with the results ![]()
Results for 20 epochs for 5 runs:
| Adam + Mish | Over9000 + ReLU | Over9000 + Mish | |
|---|---|---|---|
| LR | 3e-3 | 1e-2 | 1e-2 |
| Time per Epoch | 2:07 | 2:06 | 2:30 |
| Acc1 | 83.8% | 82.2% | 85.2% |
| Acc2 | 83.2% | 83.4% | 84.2% |
| Acc3 | 84.2% | 82.6% | 85.4% |
| Acc4 | 82.8% | 82.2% | 83.6% |
| Acc5 | 84.8% | 82.4% | 84.8% |
| Mean | 83.76% | 82.56% | 84.64% |
| Std | 0.70% | 0.44% | 0.66% |
Notebooks are available here:
Things I noticed: Despite the Over9k + Mish having a smaller train time in the 5 epoch, it seems the more epochs one has the longer it takes. I wonder if there would be any variance and accuracy change if we did batches of 5 epochs instead? Doubt it but FFT.
I’m unsure if this beats what’s on the current actual leaderboard (hidden in the forum) but I do know this beats the current leaderboard by ~7% on the github
2 Likes
For p value I just use this https://medcalc.org/calc/comparison_of_means.php.
Are your times per epoch reliable? Or is colab giving you variable resources? Because in my experience Over9000 was slower than Adam, and Mish was slower than ReLU.
2 Likes
- That whole resizing thing is a huge deal if confirmed!

3 . I was seeing a similar pattern as now when running xresnet with SImpleSelfAttention and OneCycle months ago IIRC. As in the last few epochs weren’t improving accuracy. Might need to revisit that…
Also, for the leaderboard you can just do a pull request.
1 Like
My resources maintained the same for all runs. But I can try again using some other platform.
P-values between Adam+ Mish vs 9000+Mish
5 Epoch:
0.0561
20 Epoch:
0.0751
1 Like
By the way, what do you mean exactly by tweaking cosine annealing to 0.75 ?
If you refer to
scale_factor = 0.75 * (1 + math.cos(x * math.pi))
the scaling ratio above can go above 1, meaning that you will get higher than the maximum LR that you passed to the scheduler. I assume that the update in your scheduler is done with:
base_lr = div_factor * max_lr
lr = base_lr + (max_lr - base_lr) * scale_factor
If this is the case, it means that we need to actually select a maximum LR to
new_max_lr = prev_max_lr + 0.5 * (prev_max_lr - div_factor * prev_max_lr)
new_max_lr = (1.5 - 0.5 * div_factor) * prev_max_lr
new_div_factor = div_factor / (1.5 - 0.5 * div_factor)
of instead of changing the cosine annealing computation?
On the resizing finding, resizing with common interpolation methods to a close smaller resolution will give poor results compared to performing the interpolation from a much higher resolution ![]()
1 Like