@muellerzr - check the other thread. @fgfm just rewrote it (RALamb) and says it seems improved.
I was planning to test that in a bit but now I’m busy catching up with @Seb great invention here.
And can we please go with RangerLars for the name - Over9k is so confusing for a name imo. (@grankin already agreed to the name change).
I agree with @Seb about runtime for rangerlars/over9k - but maybe this new impl may improve that.
If you are able to make some progress integrating AutoOpt, that would be great! It’s a lot more work than I was thinking from reading the paper, though ultimately I think it willl be worth it.
I made an empty github here to start if you want to team up on it:
Re: bayesian optimizer - yes if you have code I would love to take a look at it and run it for Ranger/Mish/SelfAttention and see if we can push things further.
Don’t forget, nothing is free. I have the same comment re simple self attention. What’s the cost incurred? It’s never nothing. How many additionaly FLOPS? How many more parameters? How much additional GPU memory utilization? How many more CUDA kernel launches? Etc.
The accuracy numbers from Mish trial runs in paper, here, my own – they do look promising. However, the overhead IS high. Roughly 24% drop in inference speed at 100% GPU utilization on my quick test with a ResNet50-D (same as xresnet50). I made sure it was a test that allows the GPU to ramp to full utilization, not really possible with the imagenette/woof datasets given how small they are.
BTW, Mish as implemented here has another problem, it does not take advantage of inplace computation where possible and results in a 25% increase in GPU memory consumption.
This is a more appropriate impl that doesn’t increase GPU memory allocation over a ReLU with inplace=True.
EDIT: impl modified, can’t make the tanh in place like I thought, memory utilization is impacted regardless
I don’t see Mish replacing ReLU. Perhaps it’ll take the place of Swish in some specific architectures like EfficientNet or new NAS searched architectures that choose which layers should take the performance hit based on feedback metrics for latency/accuracy targets.
Some of the performance can be taken back with a custom CUDA kernel, chaining together multiple small ops like that at the Python API has a high cost. But then the CPU cost is still high, and embedded architectures may not have fixed function (or flexible enough flexible function) units to perform the activation without extra instructions being scheduled…
Don’t know which version of RangerLars you were using, but if the code was using revision 2 or 3, they are broken (trying to fix something we broke other thing). I just published revision 4 with Max of 0.56 at 5 epoch and around 0.54 something as average (didn’t run many times, so variance is high but I would expect it to be around there).
If you were getting 72% with either rev2 or rev3 I would be EXTRA FREAKING VERY SURPRISED!!! (and with caps)
Awesome, thanks! Like you, I’m out of time for this as well (back to work that pays lol) but I’ll try to pick things up this weekend on the Bayesian/AutoOpt front.
Thanks a bunch for your input @rwightman!
Question though - I can’t see any difference time wise between your impl above and mine. The above breaks down to this b/c inplace is not allowed (like you, I also tried inplace tanh_ which doesn’t work either):
def forward(self, x):
inner = F.softplus(x).tanh()
return x.mul(inner)
Is that any better than this?
x = x *( torch.tanh(F.softplus(x)))
return x
You’ve got better tools than I do to investigate so appreciate any improvements!
Thanks!
@LessW2020 time wise there was no difference, memory wise, when I had the tanh_() as inplace there was an improvement, but realized after that change (and forgetting to rerun in train with gradients), that inplace isn’t allowed. The mul_() alone doesn’t have as much impact, so overall, likely not much difference on any count now.
Both performance and memory utilization are impacted fairly significantly using this activation.
Thanks @rwightman. I found removing the temp x and putting it as one line did improve the speed, 1 second per epoch.
Not sure how that impacts memory but did shave off a second per epoch which is nice.
I’m going to check this into the ImageWoof5 github, along with the new Mish speed improvement and I’ll write up the post I promised on this whole effort.
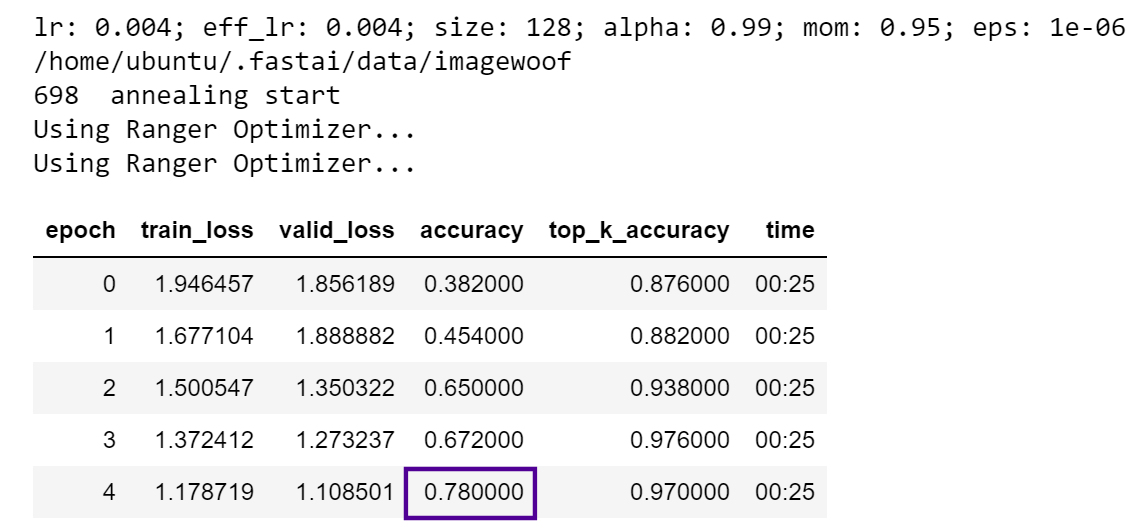
By the way, do we have the annealing fit using the callback system done? (Or are we still calling it via 6 lines) I was thinking of trying to recreate it as a callback for an eventual merge with the library (if it seems fit) like fit one cycle
For mish, it does seem to be quite a bit slower per epoch, so I’m not sure it will help us train faster… I was hoping the layer could be improved quite a bit.
For SimpleSelfAttention (ssa), I didn’t measure FLOPS, but I did pay attention to total run time when making my comparisons. In one case (which might not generalize), I got to 86.3% accuracy in 19:27 with ssa compared to 85.76% in 20:05 without. Accuracy is over 23 runs (enough for statistical significance), and runtime is averaged over 4 runs each (alternated on the same machine).
In terms of parameters, it’s one extra conv1d, so 256* 256 on resnet50, 64* 64 on resnet18.
Isn’t GPU memory directly linked to number of parameters?
I have no idea how to measure CUDA kernel launches…
I’m still not convinced ssa is a useful addition to a resnet, in fact I haven’t touched it for two months for that reason. But I believe your important points as well as the exploration from this thread might steer me back in the right direction.
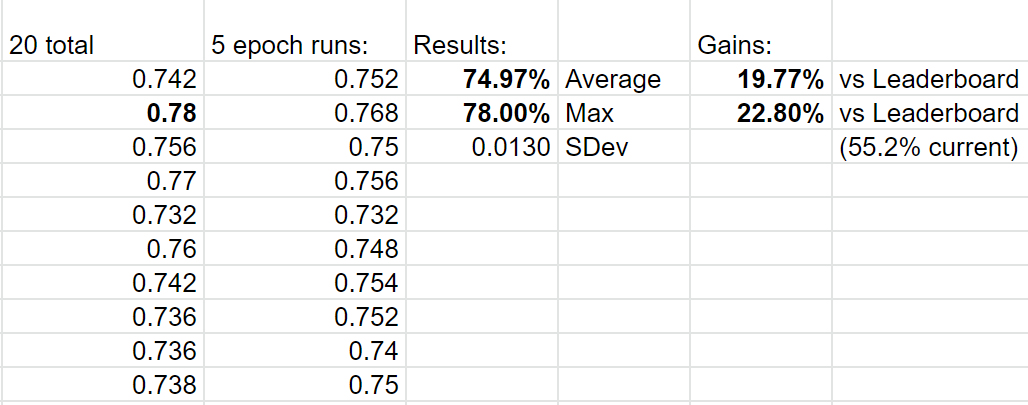
@Seb - I’ve updated the main github repo with your self attention addition, the speed improvement for Mish and the chart showing the new high scores and instructions for how people can toggle it to build on/repro (i.e. --sa 1).
Do you want to do the honors with the PR to update the leaderboards to 74.97% since it’s your self attention improvement?
With the inlining I have 22 seconds with ReLU and 24 seconds per epoch with Mish. So it’s 9% slower, not sure about the memory difference though.
That said, can’t argue with the results it’s producing at least with the 5 epoch runs!
My opinion is Mish is a more perfect activation function based on theory at least - smoother = better information propagation and thus a more robust network with better generalization.
The smooth landscape Mish produces vs. the harsh edges of ReLU provide a visual on that (see the paper images).
Ultimately nothing is likely to be faster than ReLU (it’s about as simple as it gets) but …hardware gets cheaper by the day vs. results (i.e. smarter nn’s with better accuracy) is what pays off for business.
Anyway, we’ll see how it plays out over the next year+!
On the topic of ReLU vs Mish - to check the speed of the inline Mish, I re-ran everything for 10 epochs but with ReLU in there.
Appparently, Ranger + CosineAnnealing is doing a lot more than I thought for the results:
Here’s the ReLU results, everything the same:
[0.748 0.696 0.738 0.722 0.724 0.736 0.728 0.714 0.72 0.712]
0.7238
0.014069831
Mish still beats by +2.5%+, which is inline with the paper and my earlier testing (1-3% improvement) but clearly Ranger and Flat-CosineAnneal are doing a lot of the improving considering the previous baselines with ReLU + OneCycle.