Couldn’t actually find that comment from a scan of that quite long thread. So not sure if/how they resolved it.
The differences between PyTorch and TF reflect slight differences in their implementations of softplus. The single threshold in my CUDA version reflects the PyTorch logic. I don’t think that the differences are big enough that there’s any strong reason to use the same implementation so think you could just as well use the TF logic for Mish in PyTorch. They just both come from borrowing the relevant softplus implementation.
I’m not sure the differences make a real impact and wouldn’t prevent converting models, at least not between TF and PyTorch. As noted this would also potentially apply to any model using softplus.
If there is indeed no theshold in MXNet then that may cause issues. But this also depends on other details. There may be other handling of non-finite values that would mitigate issues. It also depends on the datatypes used. In general this is mostly an issue for 16-bit floats. Though I think I did see some issues with 32-bit floats I think that was with the quite unstable calculation involving multiple exponents rather than the symbolically derived gradient calculation.
Oh and I’ve responded to that post.
I’d also note that you pointed to the Autograd implementation which should reduce memory usage but will result in lower performance. The JIT version combines both the lower memory usage and better performance so should generally be preferred.
The one issue is support in older PyTorch versions. It should be fine in PyTorch 1.2 and 1.3 (though I’ve mostly tested in 1.3). I think it should probably also work in 1.1 and maybe even 1.0 in which case it should always be fine as I can’t imagine you’d want to support pre-1.0 anymore.
But the JIT version should probably be preferred unless older support is key. I’d also note that I don’t think my CUDA version will work pre-1.2 so the JIT version should offer equivalent performance and version support. I just need to run a few extra tests on the JIT version and then will likely update the repo to indicate the JIT version should be preferred.
Additionally, I noticed your implementation takes Mish function to be: x * tanh(ln(exp(x))) instead of x * tanh(ln(exp(x)+1)) which is the original implementation. Both are considerably different.
It performs the same as the non-autograd version for forward as it requires multiple CUDA kernel launches while for backward it is likely a bit slower due to the less efficient backward to recalculate values. The JIT script reduces this somewhat by fusing multiple operations into a single kernel thus increasing performance. Actually while Swish fully fuses into a single kernel launch and so performs about the same as my CUDA implementations of Mish/Swish (which is close to ReLU), the Mish JIT version does not fully fuse as fusing is not supported for Softplus so only the mul and tanh fuse. I did implement a fully fused version by manually implementing Softplus, however this was slower than the partially fused version at least on my initial tests. I’m not quite sure why but my first guess would be perhaps the where op I used to implement thresholding does not fuse well.
Which implementation? I’m pretty sure my CUDA version is implementing the later and it’s tested against x.mul(torch.tanh(F.softplus(x))).
As I said they reflect the implementations in PyTorch vs. Tensorflow. So can’t fully speak to the differences. But I think they mainly reflect different approaches.
In terms of the upper threshold to prevent overflow PyTorch uses a maximal threshold that prevents overflow of a 16-bit float (20). TF uses a value above which the difference between x and Softplus(x) is less than the minimum value that can be represented in the given float representation (varies based on datatype but think from calculations this is around 4 for 16-bit). So I think this generally shouldn’t matter much, neither should overflow and any difference in values between the thresholds likely won’t affect the resulting value due to limited precision (though given the complexities of floating point they may not always be exactly equal).
I’m not really sure why there’s a lower threshold in TF. It seems intended to prevent underflow, i.e. to prevent calculations resulting in 0 due to floating point rounding. But I’m not really sure where this would occur and cause issues. I’d think this shouldn’t be an issue for an activation as you always have to assume that the network output (or output of any layer) could be 0 and so deal with this. So, for example, loss functions should always be fine with this and you see the use of epsilons to prevent division by 0. I guess maybe in other uses of Softplus this isn’t the case though not really sure here.
Yes, I’m aware of 20 being the maximal threshold for PyTorch to avoid an overflow but I’m still a bit doubtful of why a lower margin threshold just like for TF. Even HaskTorch I believe followed the 2 threshold protocol.
which performs better than swish but worse than mish on imagewoof (128px, 5 epchs).
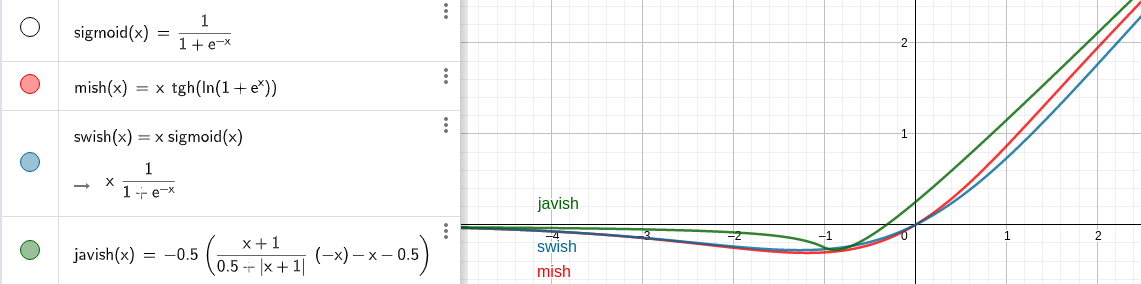
But then i was interested in creating a efficient function with similar shape that mish but similar computation than relu. Then i created this one, whish i called javish, that only do 2 multiplications and the rest is additions, substractions and absolute values:
I did no test this function yet, however i wanted to share the idea of efficient computation to get round shaped functions, inspired by the idea of fast sigmoid.
Hi @Javi - very cool, thanks for sharing your work!
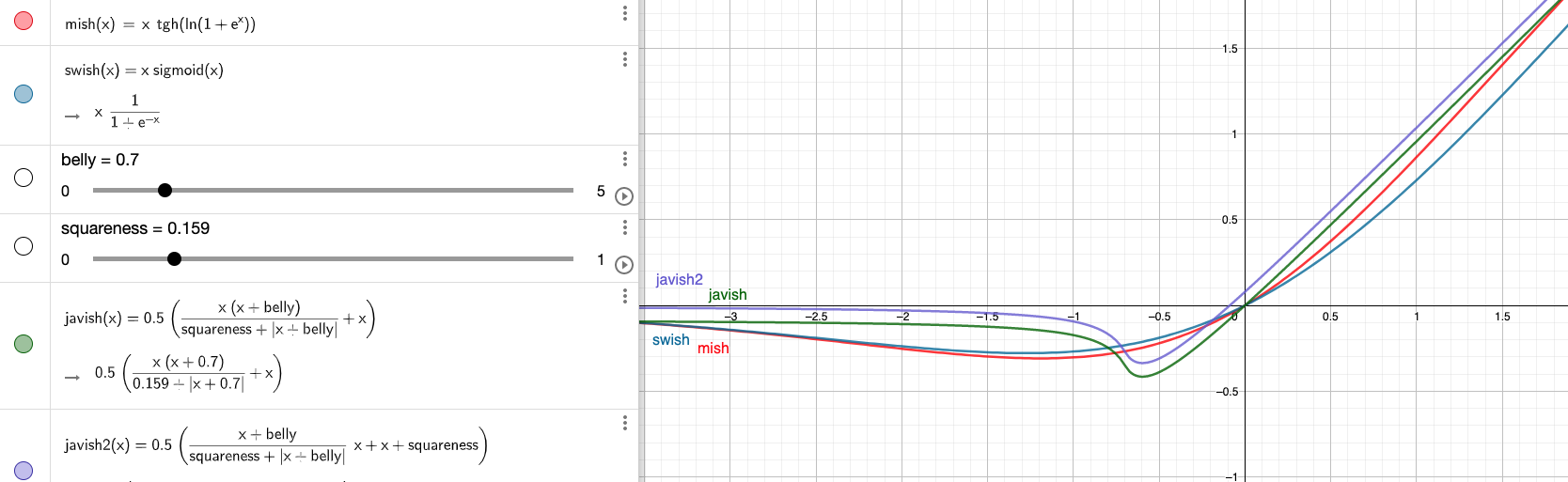
I’ll be interested to see how your testing goes on Javish. What I’m wondering is how the the fact that it intercepts the y axis not at 0 will affect the training.
It has a smooth curve though so it looks promising!
Even I’m working on a new activation function which has so far shown much better results than Mish and Swish and is faster than both, in fact has just 3 ops in total. Still early days on it.
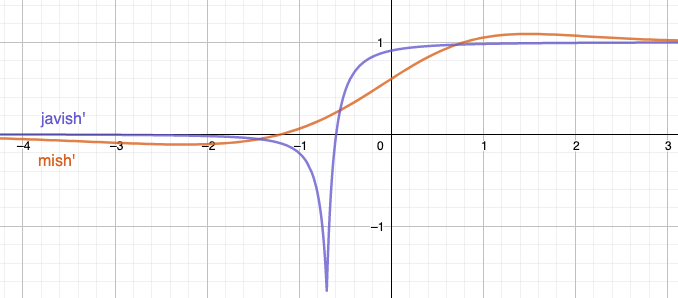
Regarding, Javish function, the only potential drawback I can see is y-intercept not being at 0 at origin as @LessW2020 pointed out. Can you also please provide the derivative comparison graph for the same?
Also, please keep me posted on any benchmarks that you have done to compare Javish with Mish.
The derivative sure does look pretty different from both Mish and Swish derivatives. One positive thing that I can note from the derivative that it more closely satisfies the condition of “Approximating identity at origin” where f(0)= 1 and f’(1) = 0 so that’s a good sign. What I’m concerned is that the gradient at -1 might explode because of the heavy -1 concavity. But I can’t be sure unless this is benchmarked. Additionally can you test this function’s robustness on increasing depth and increasing Gaussian Noise?
Can we replace these new activation act. funcs. like Mish (and others similar to ReLU) with ReLU at inference time in production?
I think, this allows high precision training (Mish) but efficient computation at inference time (ReLU).
Maybe a possible aproach to achieve this trick, could be the replacement from Mish to ReLU at the middle-end of training (80% for example) like a finetunning.
O for a more soft transtition, add a parameter to Mish (see my belly slider) to convert it into ReLU at the end of training.