I tried this by error, at least for Mish the performance drop is very hard.
2 Likes
What did you try exactly? I might be missing something.
I trained with Mish and then run with Relu activation instead.
1 Like
Right. Okay
Found this post of a 4th place solution to Kannada MNIST using Over9000 and Mish:
3 Likes
I was recently trying to train ImageNet on a p3.16xlarge cluster (8 V100 GPUs) using a ShuffleNet but have no clue why it’s so slow. 15 minutes into training not even a single epoch gets completed and the connection times out because of idle instance. Any clue what I might be doing wrong?
Updated CUDA to 10.2
And increased idle instance wait time
Still the same result
Repository - https://github.com/LandskapeAI/ImageNet
A somewhat big news. A custom ResNet 9 using Mish activation function beat the fastest CIFAR-10 training time to 94% accuracy on the Stanford DAWN Benchmark. Previous best timing - 28 seconds. New Score - 10.7 seconds. Find the PR - https://github.com/stanford-futuredata/dawn-bench-entries/pull/124 . Official Results (not updated yet) - https://dawn.cs.stanford.edu/benchmark/#cifar10-train-time

10 Likes
Hi, I’m the one who made that submission. I’m surprised that someone found it so fast. I just submitted the PR yesterday.
Mish was super helpful. It helped shave approximately 2 seconds off the final training time, bringing my 4 GPU timing close to the 8 GPU timing submitted by Apple (which was 9.x seconds, I think). But if both Apple’s PR and my PR get merged, this won’t be the fastest overall but will be the fastest on 4 GPUs. Unfortunately, I don’t have access to 8 GPU nodes on HAL (which is the computing cluster I used to train), but I’m trying out a few more things to speed it up, like the CUDA version of mish and maybe a different optimizer.
Note: most of the work was done by David Page and Apple. I tweaked a few hyperparameters and ran the training on different hardware.
5 Likes
Hey
Firstly, thanks for giving Mish a try, glad you got good results with it. I wasn’t aware of the Apple submission timing since it wasn’t updated on the DAWN website but being the fastest on 4 GPU is remarkable in itself.
Did you use the CUDA implementation of Mish by @TomB ?
Nope. Not in this submission. I used the JIT version that’s in fastai. I’ll probably try @TomB’s CUDA sometime soon, though.
1 Like

3 Likes
ResNet-50 with Mish trained on ImageNet is now available on my repository to download. Find the link here - https://github.com/digantamisra98/Mish#imagenet-scores
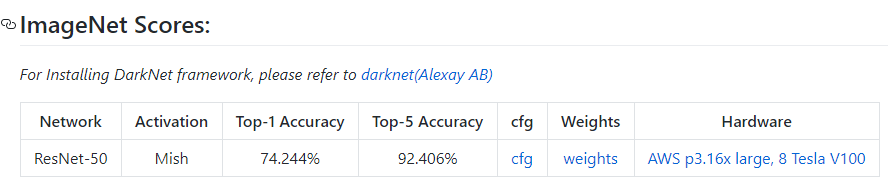
4 Likes
DarkNet 53 + Mish on ImageNet is now available to download - https://github.com/digantamisra98/Mish#imagenet-scores
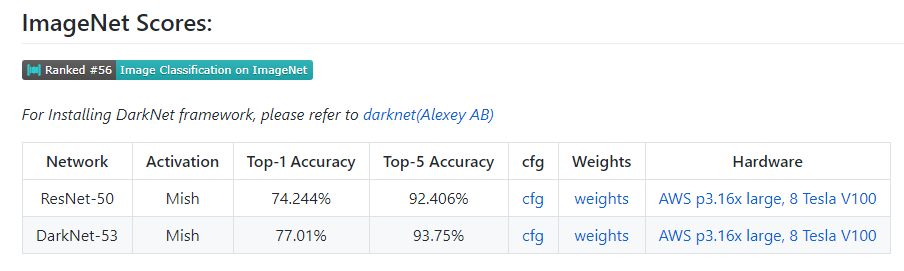
4 Likes
Is there a version of mxresnet that can work with unet_learner in fastai v1?
Faster Approximation for Mish? https://github.com/digantamisra98/Mish/issues/22
2 Likes
As is pointed out by tmassingham-ont in the linked thread,
It is an identity rather an approximation. But of course whether the results are indeed “identical” is hard to tell considering all the floating point operations and different platform involved.
Anyway, preliminary results with naive code show faster in the CPU, slower than original code and CUDA versions in the GPU.
However tmassingham-ont pointed out that the code might be accelerated with @torch.jit.script.
Could anybody suggest any further potential optimizations to the code?
1 Like
I missed out that it was an identical function. My bad. I think Fast.ai v2 uses torch.jit decorator for the function so maybe @muellerzr can comment more on the same?
2 Likes
Yes, using the @torch.jit script (similar to how Mish is defined) in the v2 library is how you’d want to go about that  (I wish I had the time to test it out but I do not). Look into here if you want to see how to do it in fastai2:
(I wish I had the time to test it out but I do not). Look into here if you want to see how to do it in fastai2:
2 Likes
Hi @TomB , I’m trying to use mish activation with MobileNetv2. The model implementation is borrowed from pytorchcv, it works fine with relu6 activation but throws
CUDA: Out of memory
error for mish, swish, h-swish (Haven’t tried any others). I’ve created issue regarding this on my repository.
I’m using Google Colab with fastai_1.0.61dev0, have tried torch.cuda.empty_cache() and restarted the runtime as well. But the error still persists except for relu6 activation.
The code producing this error could be found in experiments.ipynb
Please help me in this regard.
Those simple implementations use more memory as intermediates need to be saved for the backward pass. Either the autograd function implementations as in fastai2 here or my CUDA implementations will use similar memory to ReLU (possibly a bit more than the inplace version of ReLU but this shouldn’t be much difference).
The comparison notebook I made for Swish shows the difference in memory usage between the various implementations.
3 Likes