Hi @muellerzr,
I won’t have time until at least next weekend. Depending on what happens next week, then if I have time yes I’d love to migrate it over to 2.0
If you want to take a crack please go ahead and I can certainly provide any advise. It should not be too bad and the design will be much more modular under 2.0.
In fact, ideally I have a number of optimizers including RangerQH that need to be broken out into 2.0 (stochastic Adam, Novograd, AliG, etc.) but just have been very pressed for time on non-deep learning stuff (distributed cloud architecture).
Hope you are doing well!
Less
1 Like
Sounds good, I’ll see what I can do. I’m working on converting over my course notebooks into a v2 to help people and I hit our competition and went “hey! these don’t work anymore!” lol. I’ll play around with it and if I get it converted before you I’ll let you know 
1 Like
Here’s a new and very interesting paper on apparently an improved init process vs the usual options:
We should look at this both to test with ReLU but also for Mish!
4 Likes
@muellerzr @LessW2020 any update about Ranger in fastai v2?
I have not looked at it yet myself, I briefly looked at the optimizer notebook to see what’s changed. @LessW2020?
I tried it out briefly but was getting a couple of errors, I’d need to spend a while looking at it to figure out what was going wrong. Maybe after the RSNA kaggle comp
@morgan look at the optimizer notebook. It seemed to me like the new optimizers need to be ported over to the new pytorch to directly use them. (Or redone how fastai expects them)
1 Like
Hey all,
Here is a rough first draft of a working RangerQH port from @LessW2020 for fastai_v2.
The main difference I could see between the original code and what fastai v2 Optimizer wanted was the need to split into updates to the State and then the actual Step function.
stats
Updates to elements in the State happen by passing functions to stats in the main RangerQH optimizer function. Updates to the State happen sequentially in order of the functions passed.
steppers
Updates to the parameters themselves happen via steppers, which again is a list of functions, executed sequentially on your parameters p.
This was my first go at playing around with the innards of an optimizer so there is plenty to improve in my code I’m sure, happy to hear any suggestions around logic and naming conventions in particular 
One thing thats probably worth doing is splitting the Lookahead steppe out from rangerqh_step and into its own stepper, I haven’t had time today.
Also, I have just tested on the MNIST logistic classifer net from the “What is torch.nn Really” tutorial where it consistently beat SGD. Haven’t used it on more advanced architectures yet so there might be a little more work to do yet.
4 Likes
Trialling it out with EfficientNet-b2 but the lr_finder is giving much too high a loss, used to getting closer to 0.07 at the minimum…
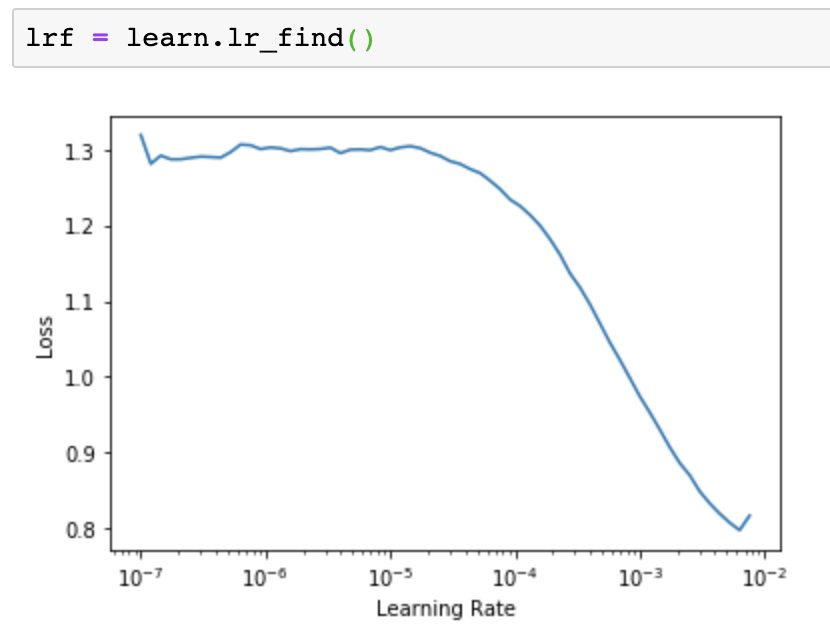
@morgan see sguggers comment here. Turns out we already have a full ranger! This should help with adapting QH
Meet Ranger - RAdam + Lookahead optimizer
Perhaps you could implement the Quasi Hyperbolic Momentum? (Only part missing) and make it modular like RAdam and LookAhead? (Or see if your current version will stack together!)
2 Likes
Haha nice, lets see what a proper implementation looks like ![]() will see if I can figure a good way to add QH
will see if I can figure a good way to add QH
1 Like
Fit_fc is now in there too as fit_flat_cos (thanks sgugger!)
I believe (if I read it right) you can do: Learner.fit_flat_cos
I’ll port over a notebook to run them all on my v2 repo here in the next few days for ImageWoof
Also just saw that the Simple Self Attention layer got added too
@Diganta and mish! (Swish too) 
4 Likes
Was trying to study the use of Mish in case of transfer learning i.e. only using Mish in the last FC layers. I tested with a pretrained Resnet50 and against ReLU on CIFAR10 and CIFAR100. Although the results are quite similar but there was marginal improvements when using Mish. The runs were only for 10 epochs and only 1 Mish activation function was used in the entire network. But the results did show promise and I observed we can get some improvements just by changing from ReLU to Mish in the head of the model in case of pretrained models.
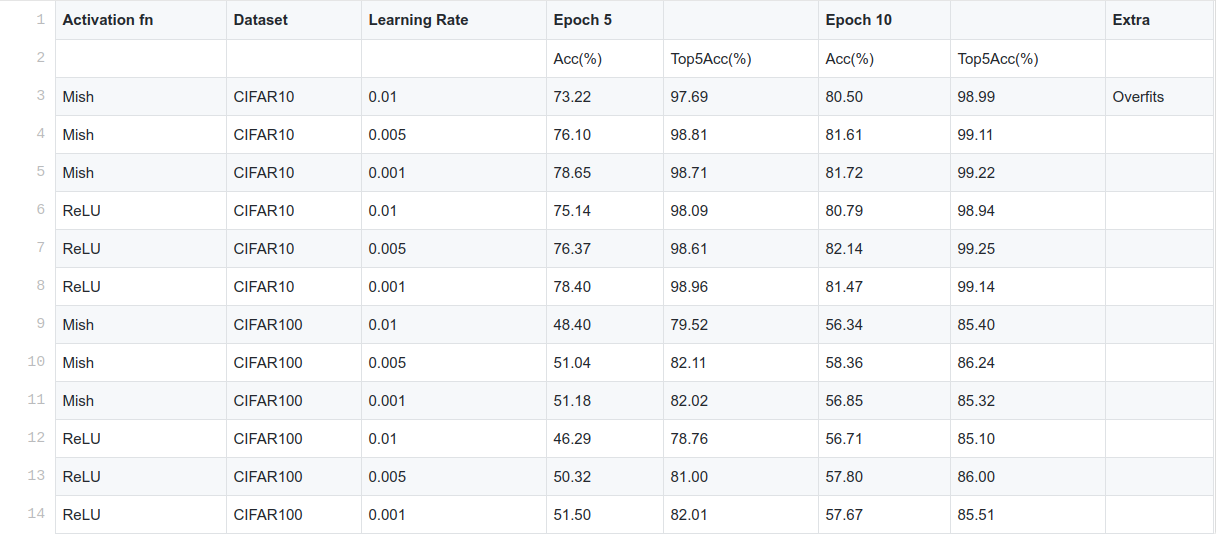
Also, all the parameters were kept the same. So just be replacing ReLU I got some improvements. There was one problem though, Mish overfitted quickly when using higher learning rate, which maybe due to not finding the best parameters.
I also wrote a medium post for the same.
5 Likes
Can someone help me with this issue over here - https://github.com/AlexeyAB/darknet/issues/3994
Commit - https://github.com/AlexeyAB/darknet/commit/bf8ea4183dc265ac17f7c9d939dc815269f0a213
Mish was added to DarkNet however in practical usage it is giving NaN. Would appreciate if someone can point out if there is any mistake with the implementation.
Thanks!
@Diganta and others I have a question. I have seen this being discussed around and wanted to know which would be better. To use a pretrained resnet with ReLU activations and only have Mish on our head? Or to replace all activations with Mish and load the pre-trained model in. Thoughts?
2 Likes
That implementation is not at all numerically stable. All the exps quickly lead to overflow and hence NaN. Should be possible to adapt either the Eigen based implementation from tensorflow contrib or my mostly pure C++ implementation (mostly as it’s using the PyTorch dispatch/templating but is otherwise standard C++). The TF one is probably slightly more stable given handling of both underflow and overflow but will require more adaptation to remove the Eigen dependency.
3 Likes
Not sure which would be better in that case. I did try replacing Swish with Mish using pre-trained weights and that seemed to work well from minimal tests. I didn’t do anything special in terms of freezing or LRs.
But may not work so well from ReLU. But don’t think it’s that dissimilar in terms of general output range at least.
I gather the idea of the various initialisation procedures is to choose random initial weights that give similar activation ranges to those you’d find in a pretrained model. In which case presumably pretrained weights shouldn’t be any worse, only potentially better (given there is no special init handling for Mish).
Perhaps a bit of extra care around initial training would also help. Trying to ensure the previous learning is preserved rather than a poor step early on changing too much. Maybe training for a few iterations with everything but the batchnorms frozen (the default if you freeze the entire model in fastai). I wouldn’t think you’d need much to update the BNs, probably not even a full epoch assuming a reasonable dataset size. Then maybe a lower LR for a little bit, again maybe even less than an epoch. You could do both of those by using a warmup schedule from 0 over the first epoch (at least if testing suggested it was likely to be worthwhile).
2 Likes
UPDATE:
Lost results of my initial tests due to some Jupyterlab issues (lost connection then it went a bit feral). But got some information from the partial results and have re-run a more selective set of tests. Just testing various setting with 1-cycle not the schedulers. Some promise with schedulers but need some more work there as think you really want differential learning rates across layer groups but not sure that will work with the schedulers.
I’ve updated the notebook (note it won’t run and produce those results but all the code for them is there). Tables and graphs at the end show main results.
Not shown in these results is the very poor performance if you don’t first train the classifier with the body frozen. I initially missed this and while ReLU also suffered quite a lot this really affected the cases with Mish.
I tried both replacing Mish across all layers from the start (mish_all in the results) with a staged approach (mish_stg) of first replacing Mish in the classifier and just training that, then replacing Mish in the body when you unfreeze and fine-tune. Results here are a bit mixed with probably a slight overall advantage to the non-staged approach. But I think this is largely because I was comparing everything across just 10 epochs, unfreezing at epoch 5. So the staged approach gives a lot less time for the body to adapt.
Differential learning rates seemed to help quite a bit so I compare a couple of settings there. Quite low rates on initial layers do seem to help with the adaptation but there’s a bit of a trade off as this gives less overtall learning. Again this is probably slanted given the short testing time. With more epochs I think these might lead to better final performance.
Tests with a lower learning rate seem to suggest a lower rate can help avoid big drops when you switch, but again likely due to the very limited time they gave worse final results.
My overall view from testing would be that there does seem to be the possibility of getting pretty good results with Mish across the whole model but it is a little sensitive to parameters and it may not be possible to use basic parameter settings to optimally adapt it.
I’d tend to think based on this that trying to replace Mish in the body while training a new task may not be worthwhile. Especially if you are only training for a limited time and/or don’t have a lot of training data so overfit is a concern.
But it seems like it may be worth trying to adapt existing weights to Mish. It seems like you may be able to come up with a fairly minimal training regime to create weights quite well adapted to Mish with much less work than full ImageNet training. Particularly promising here is that the best performing all Mish model outperformed the worst ReLU model even though they’re all fairly reasonable settings. So the gap isn’t that big.
One thing that might be interesting to try is progressively replacing the activations in the body. So replacing the final activation and just unfreezing and training layers after it. Then the next to last activation and so on. This would need a bit of training time but I don’t think that much. I’d guess you might get good results with just a few hundred batches per step (the epochs there being ~200 batches). Not really appropriate for normal use, but may produce some nice weights with a lot less work than training from scratch.
5 Likes
There’s an issue in your Repository. Someone from the YoloV3 team needed some clarification with how to integrate Mish CUDA in their script. Letting you know in case if you haven’t checked. Thanks!
@TomB also can you please take a look at this comment:
Also as you can see there are 3 different Mish-implementations , even forward-mish functions are different, so we can’t convert model between TF(2 thresholds) <-> Pytorch(1 threshold) <-> MXNet (0 thresholds):
- your implementation: Mish/Mish/Torch/functional.py at master · digantamisra98/Mish · GitHub
- Pytorch: mish-cuda/csrc/mish.h at master · thomasbrandon/mish-cuda · GitHub
- TF: tensorflow/addons@093cdfa#diff-ba79ea22df25d0228e4581894a324095R40-R49
How do you think to solve this issue?
Link to discussion - [Feature Request] Mish Activation function +0.5 AP wrt. Swish · Issue #3994 · AlexeyAB/darknet · GitHub