Congratulations! Awesome work.
Sample size + stdev would be nice!
@jeremy bringing this discussion to your attention: adding in standard deviations + sample size (number of runs) to the leaderboard for good statistical significance testing on new findings.
Thanks @muellerzr. I’d rather not add anything that makes it harder for people to contribute. But I agree it’s interesting info. So either include it in the notes column, or in the page that’s linked to in the URL.
2 Likes
Well at 94 on average we can consider it solved already 
2 Likes
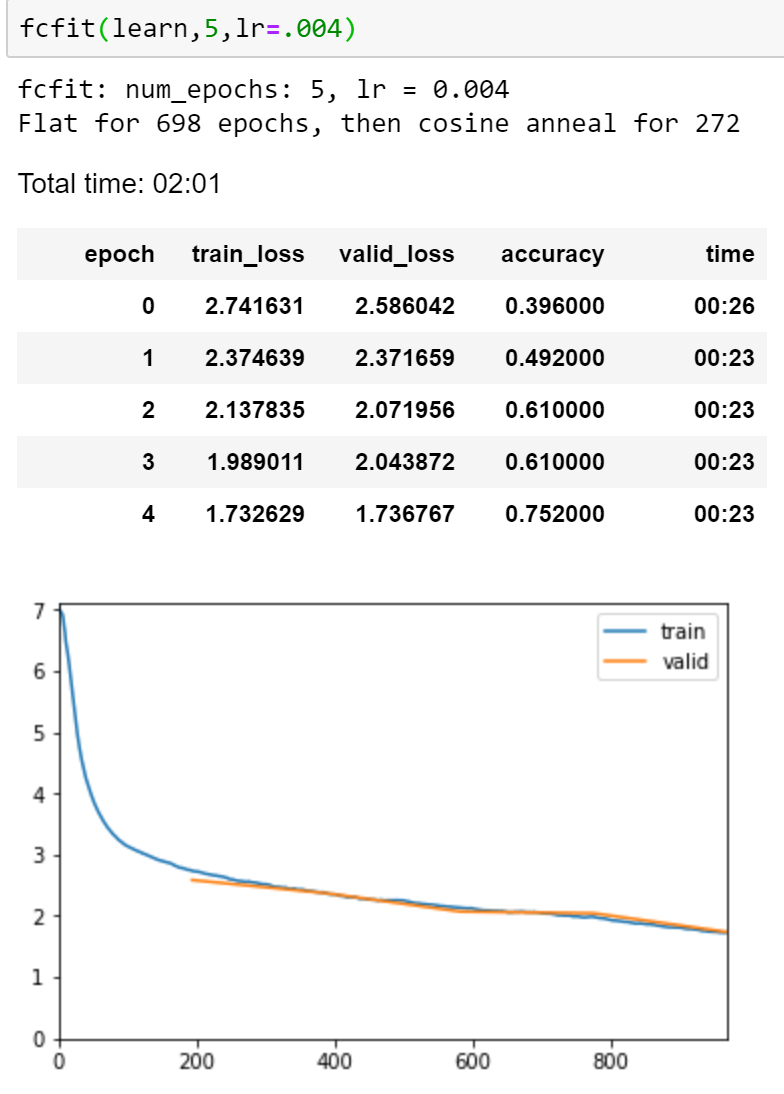
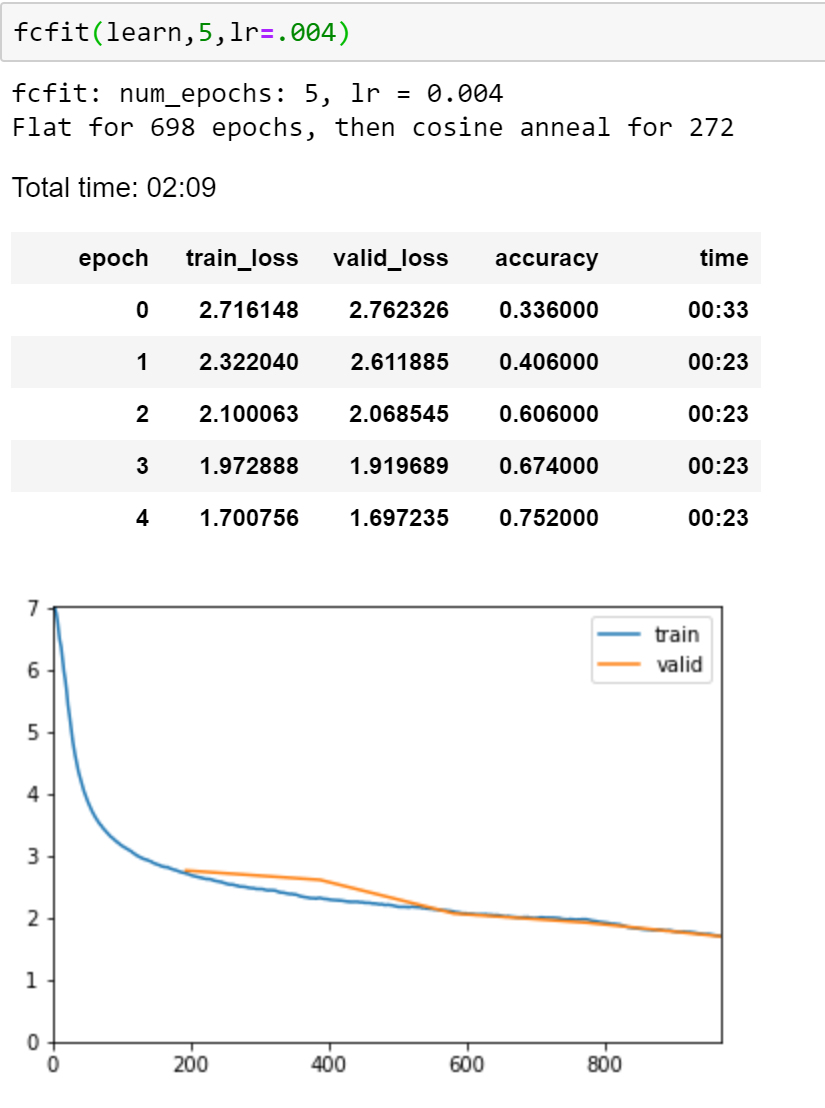
Okay now fit_fc is in the library and working. I’ll write some documentation tonight and probably ask the hive if I had missed something or if I should include anything else
Run !pip install git+https://github.com/fastai/fastai.git to grab the most recent version
Also if we wanted to train on the entire imagenet dataset (to provide a transfer learning model for everyone to use with mxnet) how would we go about grabbing that dataset?
5 Likes
Awesome, nice job @muellerzr
1 Like
Thanks @oguiza!
1 - also thanks for pointing out the size param is incorrect. I had copied the long parameter list since nothing really changed (i.e. bs, mom, optimizer) etc. but obviously the px size did. I’ve put in an updated PR to get it fixed.
2 - Re: initialization - that sounds promising. @Diganta just posted some work on inits + mish, lecun_uniform and lecun_normal has the two highest end results. But it would also be interesting to test LSUV initi from part 2.
3 - Related topic, but I did test progressive sprinkles and mixup in the work here at least for…and found that it didn’t really help. flip + presize were the most effective re: augmentation, though seems like there should be something there that would help. Possibly phasing in sprinkles via curriculum learning which is closer to what I did before (instead of just p = .2…p = .1, .2, .3, .4 matching the epochs). Changing presize from .35, 1 to .75, 1.2 worked better though.
Anyway glad you have a GPU again and look forward to any of your findings!
1 Like
@LessW2020 this was a question asked in the other forum post, did we try with LAMB yet? Or LAMB + LookAhead? (or can we run that test briefly?)
1 Like
Generally you’ll need 100+ epochs for those augmentations to help much, in my experience.
5 Likes
Hi -we didn’t test LAMB yet. That was because I thought LAMB was just LARS but optimized for larger batches…however, it seems to be a slight improvement over LARS:
- If the numerator (r₁ below) or denominator (r₂ below) of the trust ratio is 0, then use 1 instead.
- Fixing weight decay: in LARS, the denominator of the trust ratio is |∇L| + β |w|, whereas in LAMB it’s |∇L + β w|. This preserves more information.
- Instead of using the SGD update rule, they use the Adam update rule.
- Clip the trust ratio at 10.
Source for the above:
An intuitive understanding of the LAMB optimizer | by Ben Mann | Towards Data Science
So let me get it up and running and will test in an hour or so!
4 Likes
Thanks Less!!!
I see that you two have kept up with the awesome work, congratulations!
Regarding the clipping, I recall we’ve had a discussion about whether we should only clip the numerator r1 or the full trust ratio (empirically if I remember correctly, numerator clip was performing better). But regarding the weight decay fix, I disagree that it was new in Lamb.
In LARS paper, the author mentions it, just makes a simple illustration with SGD and maximize |∇L + β w| with |∇L| + β |w| (β being positive, the case of equality is only possible if the two tensors are colinear). But I can confirm it performed better on my training runs 
Keep up the good work!
EDIT: typo on the tensor condition for norm equality
2 Likes
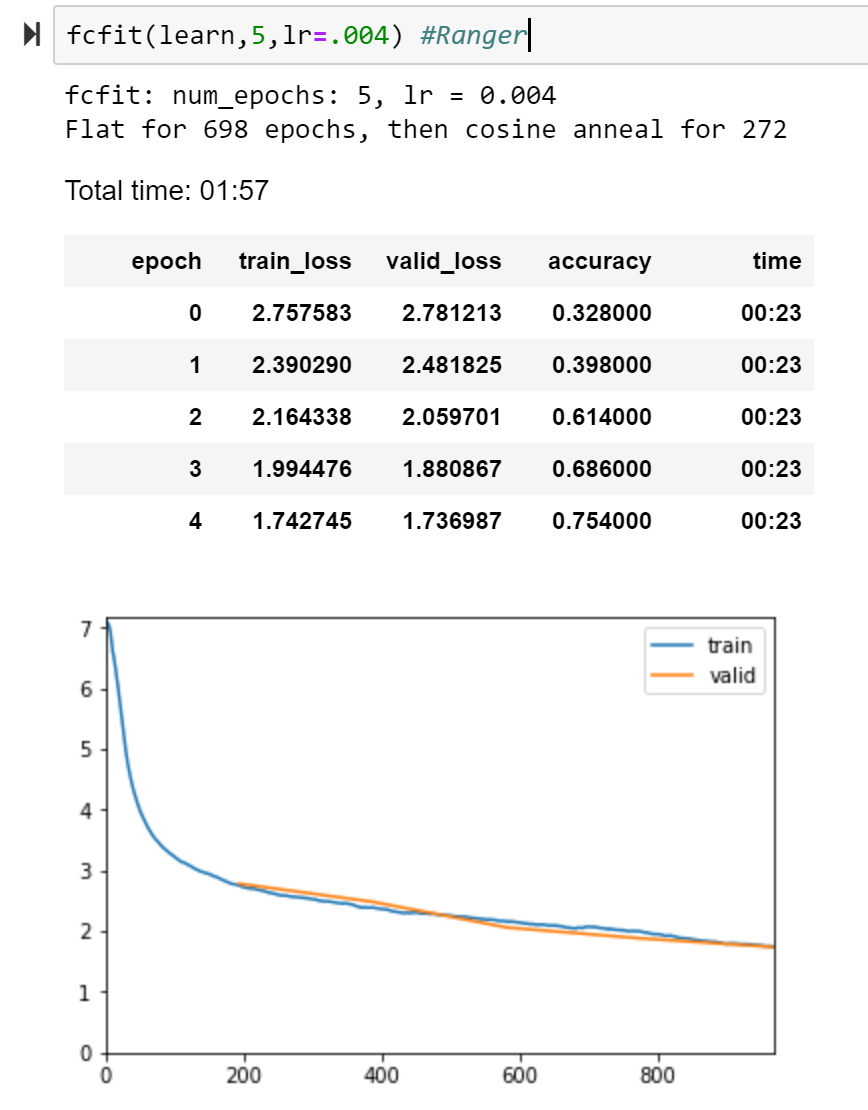
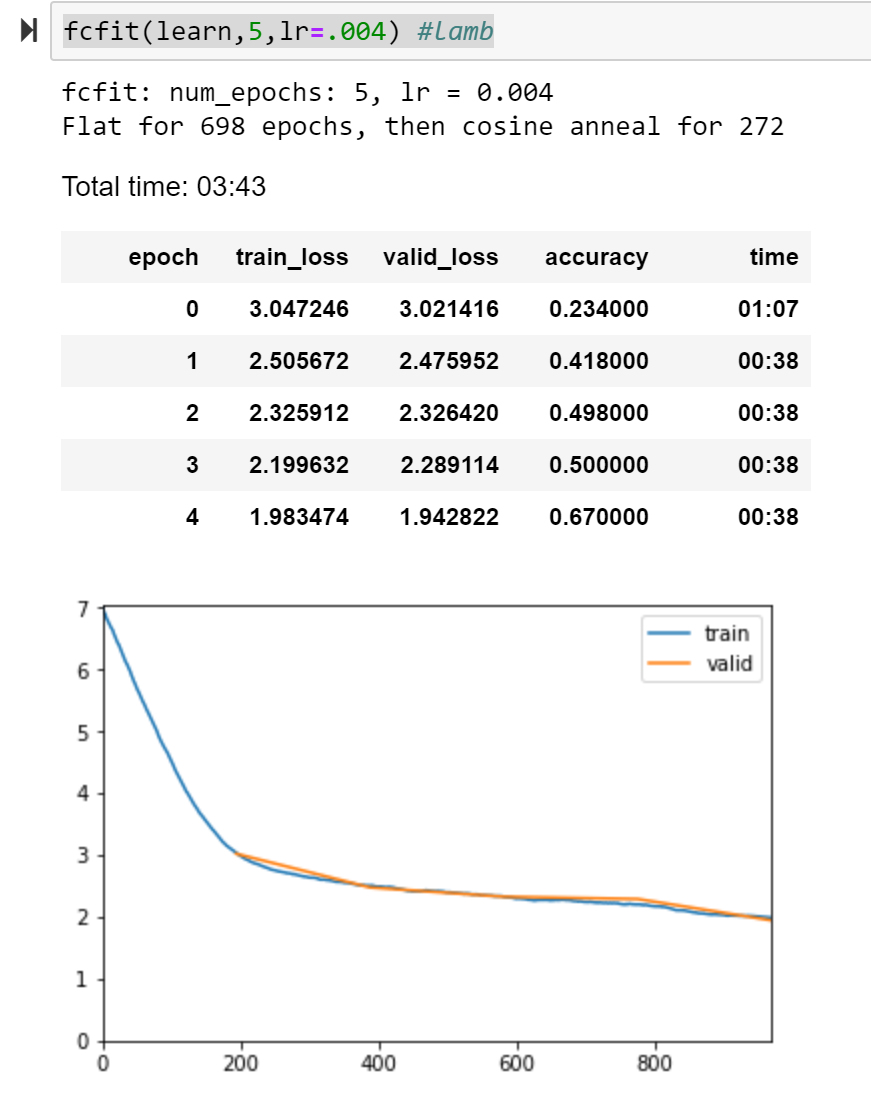
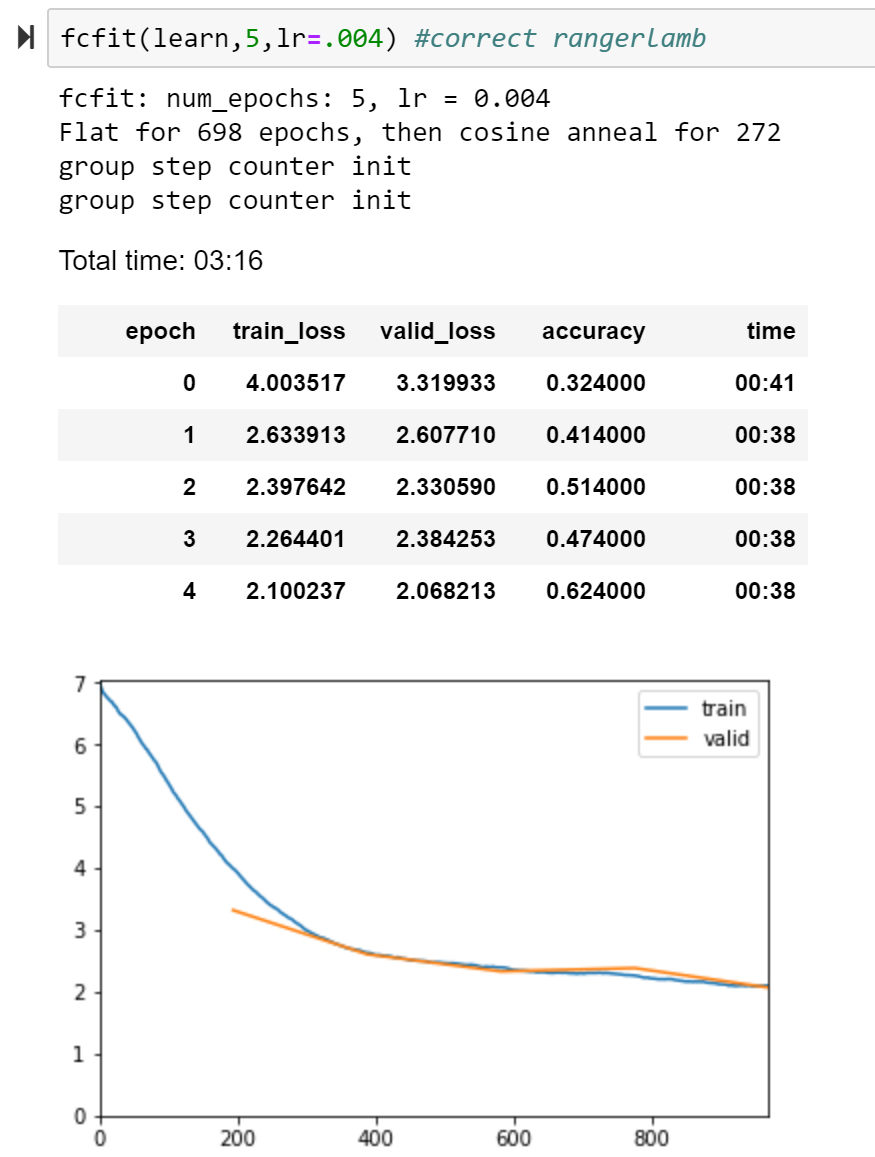
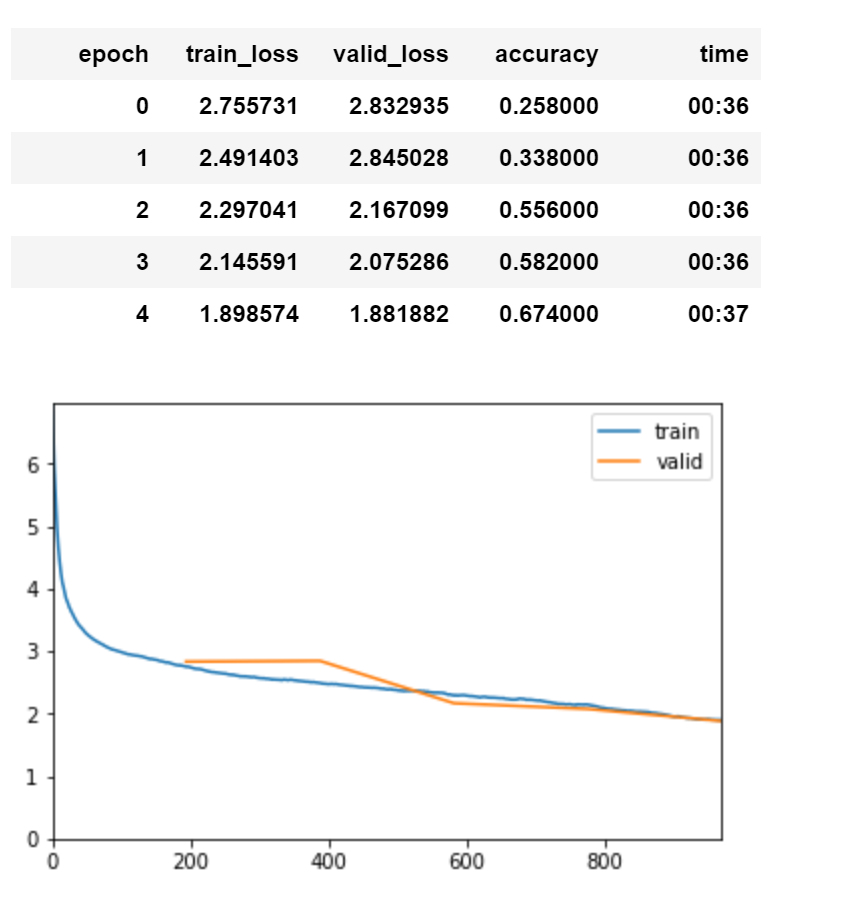
I ran quick tests on Lamb, RangerLamb (lookahead+lamb), RangerAdam (adam+lookahead)…at least for five epochs, none were competitive. Small sample set of 1x5 epochs each, but the big ding on lamb is it’s like 2-3x as slow as Ranger…so for the same time, Ranger could run 2x+ epochs and beat on that basis alone.
Regardless, here’s the runs and their loss curves…basically what appears to really set Ranger ahead is it continues with a fairly aggressive path in the middle of the run. I believe this is from the solid launch pad that RAdam provides at the start. Lamb and variants all start off ok but then flatten quite a bit in the middle. I suppose this might be the trust ratio clamping down too hard there, but not sure.
Ranger curve:
Lamb curve:
RangerLamb:
RangerAdam (Lamb running as Adam is why it’s so slow…same calcs but then ditches trust ratio):
4 Likes
I was the one asking about using LAMB. Thanks for doing the experiments!
3 Likes
fyi, I’ve rewritten parts of Ranger to provide a much tighter integration for the slow_weights…
New version 9.3.19
*Refactoring slow_weights into state dictionary, leverage single step counter and allow for single pass updates for all param tensors.
*Much improved efficiency though no change in per second epoch time.
*This refactor should eliminate any random issues with save/load as everything is self contained in state dict now.
*Group learning rates are now supported (thanks to github @SHolderbach) This should be a big help as we move from R&D to more production style use ala freeze/unfreeze with other models.
Passes verification testing
6 Likes
Great work @LessW2020!!!
1 Like
Hey guys, need a small help. I’m having a bit of trouble replicating the outputs of this paper - https://drive.google.com/file/d/11K9Fi0n0BTq22dEl4V6YSCpJ4yLxVPBQ/view?usp=drivesdk
Especially figure 3 where the authors have plotted the Edge of Chaos for 3 activation functions. Can someone provide me any helper or boiler plate code? Thanks!
1 Like
@LessW2020 We haven’t dig much yet on the Ralamb thingy, but apparently a ‘coding mistake’ appears to be the source of the high performance of Ralamb against a properly implemented RAdam + LARS. @grankin repo has the latest iteration (mistake included). https://github.com/mgrankin/over9000 Those numbers are vanilla – pre improvements – with the only addition of the annealing schedule.
You should try that implementation as it appears to be much more aggressive at the start and during the optimization and still work.
For details of what we know of the error so far: https://gist.github.com/redknightlois/c4023d393eb8f92bb44b2ab582d7ec20#gistcomment-3012275
3 Likes
Here is my results:
woof, 5 epochs.
Xresnet50, Adam, as base, only without fp16.
Selu, a=1, lr=3e-3
[0.602, 0.616, 0.628, 0.608, 0.626, 0.6, 0.590, 0.632, 0.630, 0.608]
mean: 0.6140, std: 0.0138
Selu, lr 3e-3
[0.62, 0.636, 0.616, 0.606, 0.578, 0.63, 0.618, 0.626, 0.62, 0.626]
mean: 0.6176, std: 0.0153
Celu
[0.65, 0.616, 0.598, 0.622, 0.610, 0.596, 0.590, 0.636, 0.626, 0.622]
mean: 0.6166, std: 0.0178
Mish
[0.586, 0.590, 0.612, 0.608, 0.636, 0.616, 0.6, 0.616, 0.62, 0.646]
mean: 0.6130, std: 0.0177
So - it close, need to check on 20 epochs.
Actually a i thought it is better than baseline, Relu, it was ~0.59 on my comp.
But now i’m rerun baseline and it is:
lr=3e-3
[0.628, 0.614, 0.630, 0.610, 0.618, 0.610, 0.626, 0.624, 0.618, 0.592]
mean: 0.6170, std: 0.0107
So - i’m confused, all equal.
Nbs: