Re: CUDA errors - that’s very surprising. I would try running without self attention as a quick check to narrow it down.
That did it… @Seb bringing this to your attention as it ran fine with a resnet34
2 Likes
Not too surprised, but do you mean a CUDA memory error? I wonder what’s different with that dataset.
Nope. Asset assist error. Here’s the stack trace
<ipython-input-9-a5616a3ae23f> in flattenAnneal(learn, lr, n_epochs, start_pct)
8 sched = GeneralScheduler(learn, phases)
9 learn.callbacks.append(sched)
---> 10 learn.fit(n_epochs)
/usr/local/lib/python3.6/dist-packages/fastai/basic_train.py in fit(self, epochs, lr, wd, callbacks)
200 callbacks = [cb(self) for cb in self.callback_fns + listify(defaults.extra_callback_fns)] + listify(callbacks)
201 self.cb_fns_registered = True
--> 202 fit(epochs, self, metrics=self.metrics, callbacks=self.callbacks+callbacks)
203
204 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
/usr/local/lib/python3.6/dist-packages/fastai/basic_train.py in fit(epochs, learn, callbacks, metrics)
99 for xb,yb in progress_bar(learn.data.train_dl, parent=pbar):
100 xb, yb = cb_handler.on_batch_begin(xb, yb)
--> 101 loss = loss_batch(learn.model, xb, yb, learn.loss_func, learn.opt, cb_handler)
102 if cb_handler.on_batch_end(loss): break
103
/usr/local/lib/python3.6/dist-packages/fastai/basic_train.py in loss_batch(model, xb, yb, loss_func, opt, cb_handler)
31
32 if opt is not None:
---> 33 loss,skip_bwd = cb_handler.on_backward_begin(loss)
34 if not skip_bwd: loss.backward()
35 if not cb_handler.on_backward_end(): opt.step()
/usr/local/lib/python3.6/dist-packages/fastai/callback.py in on_backward_begin(self, loss)
288 def on_backward_begin(self, loss:Tensor)->Tuple[Any,Any]:
289 "Handle gradient calculation on `loss`."
--> 290 self.smoothener.add_value(loss.detach().cpu())
291 self.state_dict['last_loss'], self.state_dict['smooth_loss'] = loss, self.smoothener.smooth
292 self('backward_begin', call_mets=False)
RuntimeError: CUDA error: device-side assert triggered
1 Like
I also used multiple datasets, it and pets and had the same results.
1 Like
Strange error! I guess self-attention is still very experimental, so you might run into those kind of issues.
1 Like
Quite so ![]() I don’t know quite enough yet in that part of the fastai code to debug what’s really going on.
I don’t know quite enough yet in that part of the fastai code to debug what’s really going on.
Thanks for posting this paper. I read it and now better understand likely why we were not doing as well on the higher resolutions (proportionately I mean).
The takeaway here is that training can muck with scale and thus affect final perfomance, positively or negatively.
I adjusted our presize from .35, 1 to .75, 1.20 and got a 1.1% boost on 192 Woof, 5 epoch:
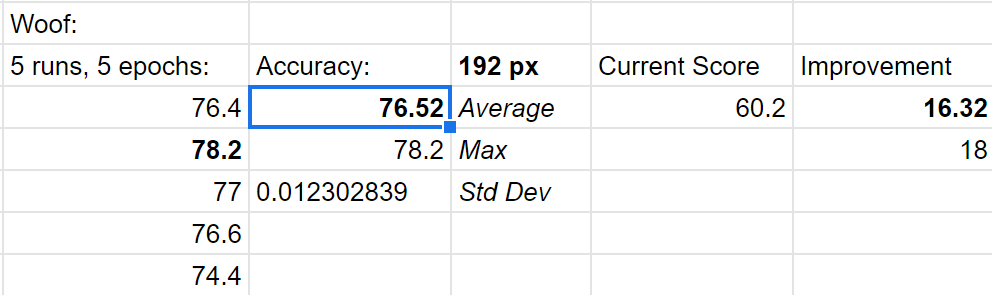
(was 75.4).
3 Likes
Nice job! And thanks @DrHB for that find!
@DrHB I’m playing around with EfficientNet b3 + Ranger + FlatConsinAnneal + Stanford Cars at the moment. Currently still not matching the accuracy they achieved in the paper with 80epoch runs, but I find Efficientnet seems to be much more stable for training with Ranger. I also have to bring the lr lower than the typical lr_find rule of thumb of min_loss/10.
Will try with RangerLars and Mish once I think I’ve tuned the lr + moms for plain ranger as much as I can. Here is my best run so far, 91.2%:
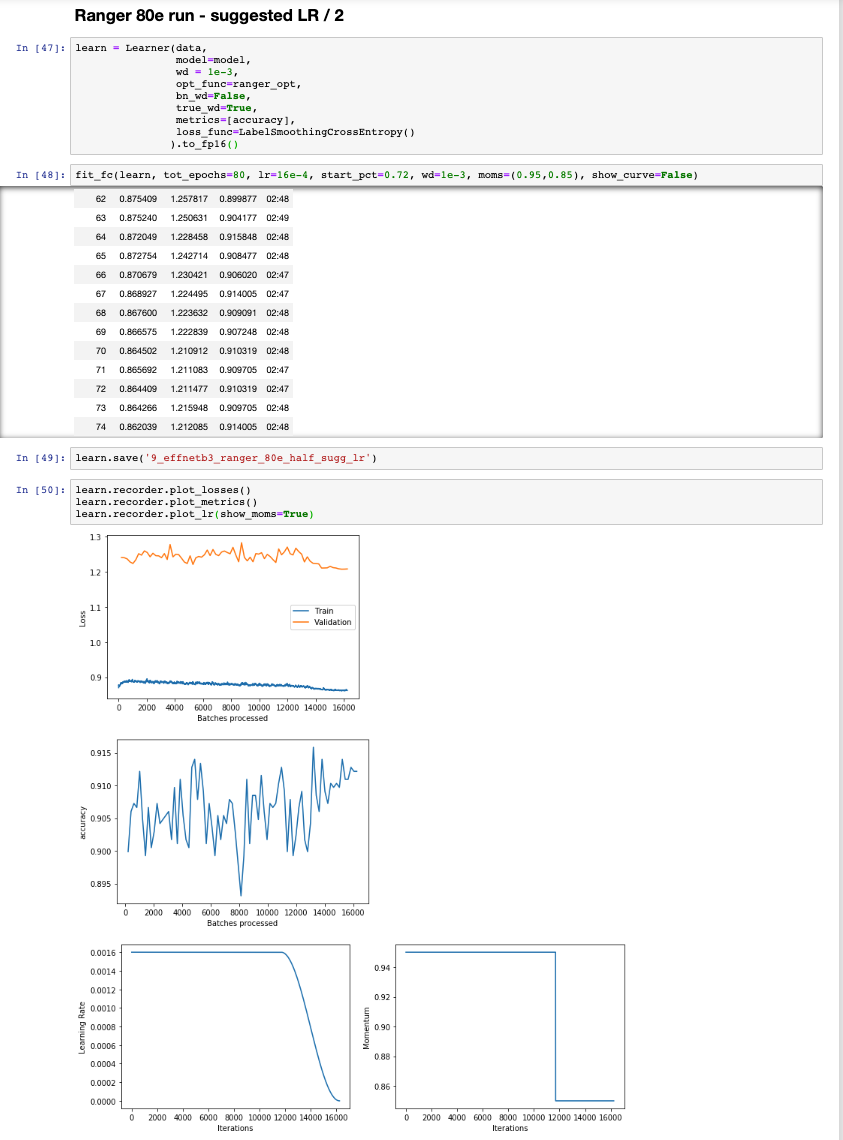
3 Likes
6 Likes
One immediate idea for us is to put lr groups into MXResNet and use differential learning rates.
Another github contirbutor updated Ranger today with a fix to support multi-group learning rates (i.e. differential learning rates).
I’m testing moving the slow weights into param group as well now, and if that works then we should try and divy up MXResNet into three groups and support varying learning rates just like they do in FastAI v1 with ResNet.
I suspect that will help as we get into longer runs ala 80 epochs or more, we are likely doing more harm than good jiggling the early layers at the same rate as the later layers.
That may be another reason btw the learning rate finder doesn’t work as well…
2 Likes
Sounds like a good idea. I’m working on v2 stuff right now for the next few days so I’ll leave that to you guys (minus the PR, still waiting to finish that import up!)
1 Like
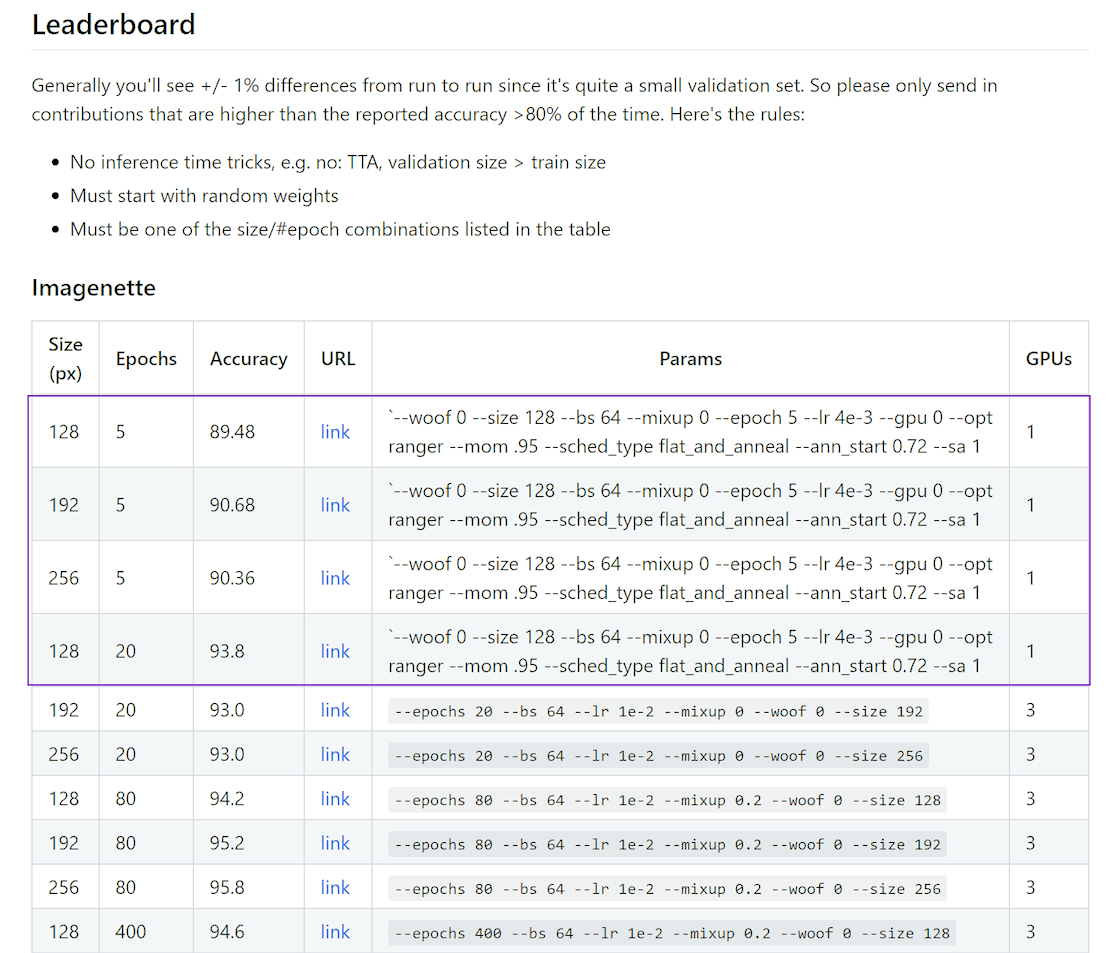
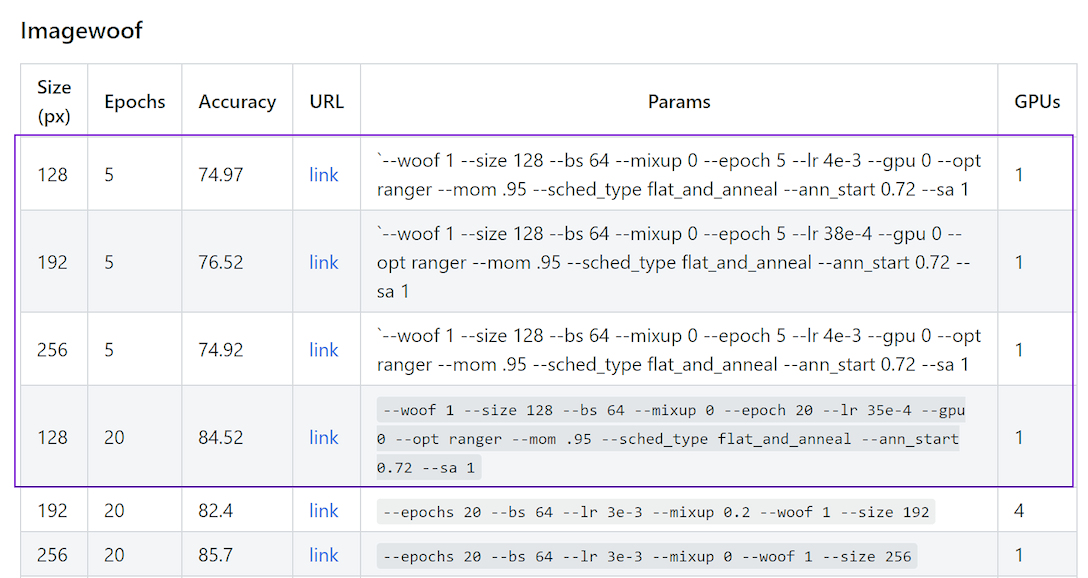
Ok 2 more records (one was our closest win yet, with only 1.5%…but over the 1% min jump to enter regardless).
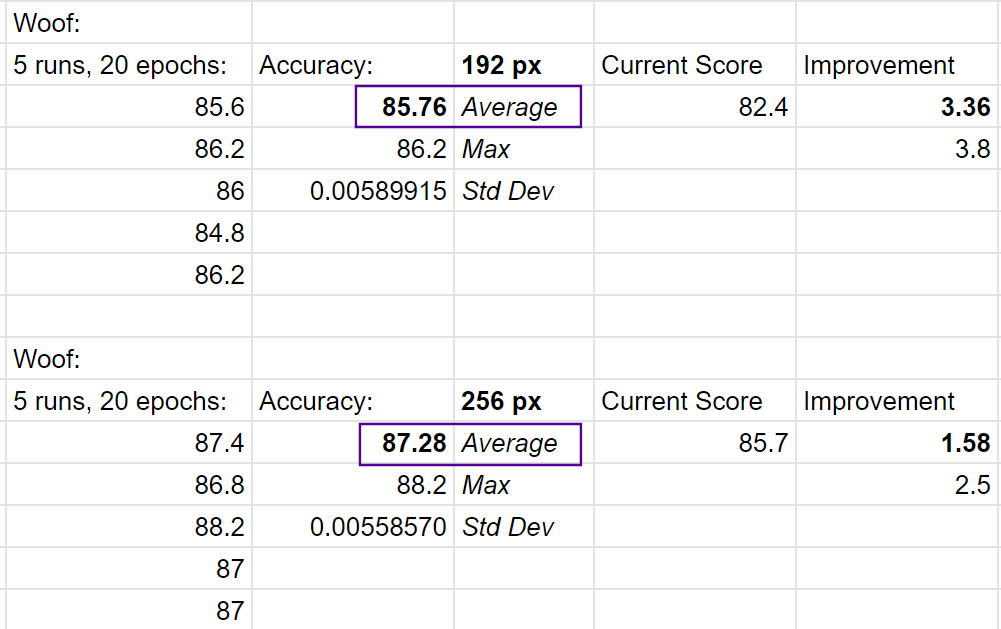
That brings us up to 10!
1 Like
Well more good news - we are now up to 12!
We’ve effectively swept the leaderboards for 5-20 epochs, so congrats!
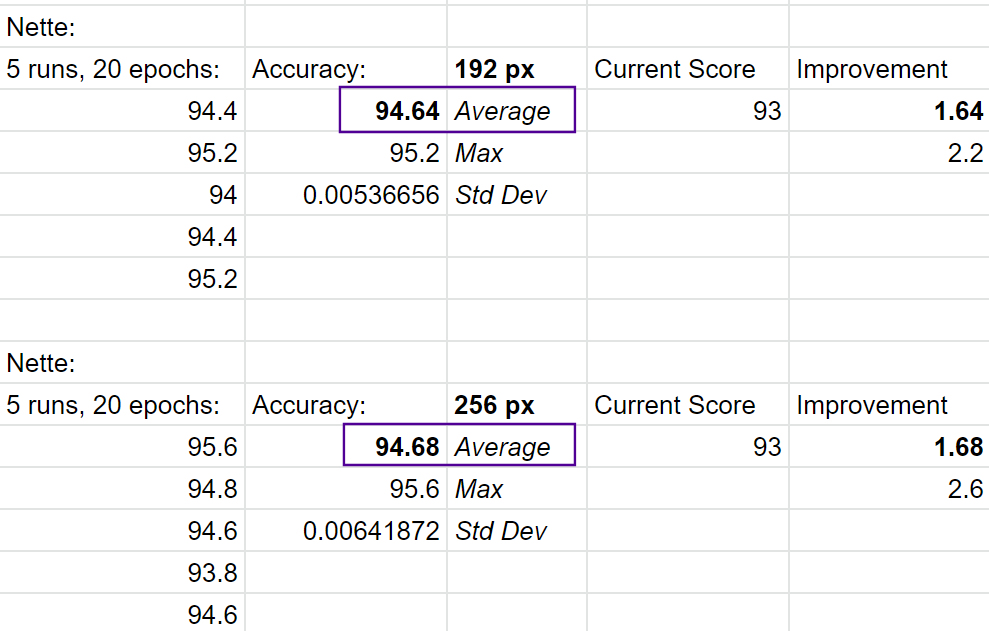
I’m planning to work on Ranger more this week and moving some stuff into v2 optimizer form. So no plans to work on more records at this point 
One very nice thing about our scores, the std dev is quite tight so indicative of consistent results.
3 Likes
Congratulations on your work!  Seems you have really found a more effective and stable set up! And have really raised the bar for the next ones who try to beat you.
Seems you have really found a more effective and stable set up! And have really raised the bar for the next ones who try to beat you.
Now that I have access to a GPU again, if I can find the time, I’ll try to understand the impact of a good initialization. There are a few approaches I’d like to test that I really like to understand if they have some value.
BTW, I’ve noticed the size parameters in the Imagenette github site are incorrect. The show the same size for all records.
3 Likes
Food for thought: Should the leaderboard also include standard deviation? This would allow for a real sample size significance test to be done.
Congrats!
As mentioned before, you are moving tooo fast!
I’m experimenting with different activations / optimisers.
By the way - as about topik name, i find what Mish work good. And i tester another variant and find what Celu and Selu works very good to
1 Like
Can you provide me your results? I would like to see the comparison.
@a_yasyrev
Absolutely. It would help to evaluate which entries where the most stable. I think this should be recommended to Jeremy to have std. Dev of results.