I was going to run really fast on ImageNette but can’t find the full size edition of it. is there one? I can’t even get 320 to pull…
Odd. There should be? Not URLs.IMAGENETTE?
Also, to my earlier statement actually I am incorrect. Normally the rule of thumb is the higher in resolution (size) you go, the better the accuracy should be due to the ability to extract more features. And yet the higher we go there’s a match if not drop (very slight drop) in accuracy. This is the hypothesis for now but I think this setup is aiming more towards that. I’ll set up an experiment tonight where I do 3x runs of 3x sizes, 128, 196, 256 and I’ll compare them. The reason for this is with colab I’ll run outta GPU at our batch size, so I will limit mine to 16 for each. I’ll post the results when this is done, but it’s something that has been nagging on me since we saw our minimal improvements.
By that I mean we are able to achieve top accuracy at a much lower resolution than needed, and possibly beat having full resolution (or greater than a particular size)
cool, that sounds like a good test!
I found that I can get full ImageNette but it’s this:
URLs.IMAGENETTE
(update - no I can’t. Using that provides files that can’t be loaded…complains about it.)
Anyway going with URLs.IMAGENETTE_320 for now as that does run.
Note the lowercase s…it’s now downloading so will run now and see if we can get another record or two before I PR.
1 Like
Odd. Let me go take a look. Also I’ve got six runs going right now. It’s weird. I hadn’t noticed the effect of the K80 vs the old GPU they use on colab. But 1 out of my 6 instances got it lol. 1:22 min epochs vs 2-3 minutes on the rest!
1 Like
Ok we’ve got two more records to enter,
and I’m running Nette 192 right now…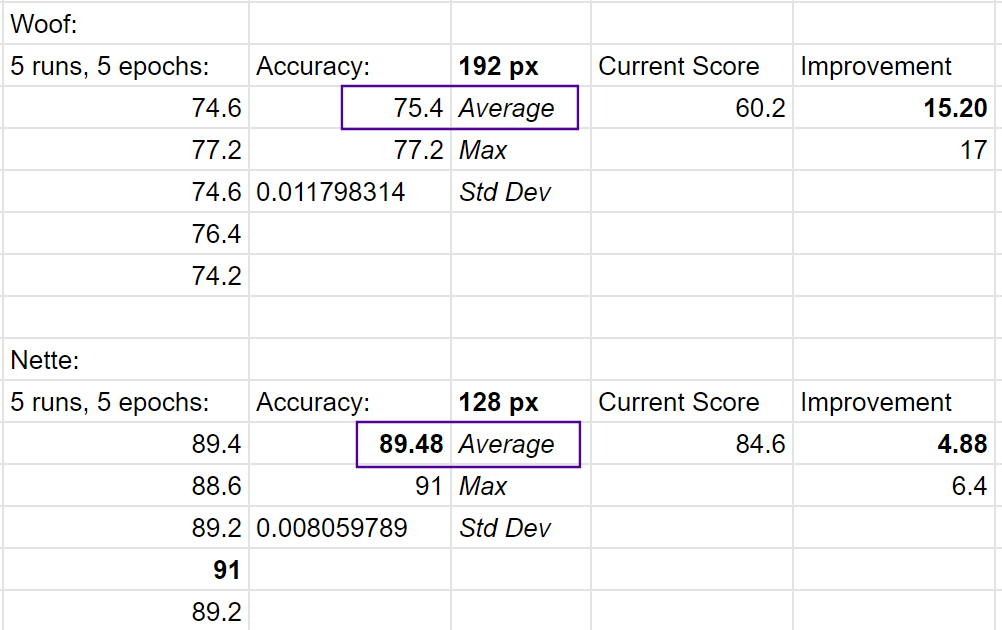
Std deviation on all our runs is very good!
1 Like
Four new to enter, plus the one from this morning (already PR), plus our original…
Effectively 6x record holders 
Okay so. My experiment is done and here’s a sum up:
TLDR: No, increasing image size will not lead to short-term increases in accuracy, which is different than how it is with xresnet, as the original leaderboard had large variances in accuracy.
Null Hypothesis: Image size is not affecting the accuracy at five epochs and they all will reach the same as 128x128.
Experiment Setup:
3 runs of 128x128, 196x196, and 256x256 for five epochs, looking at the average by epoch and end state. Batch size of 16 due to GPU limitations.
Results:
Baseline 128x128:
| 1 | 2 | 3 | Avg | STD | |
|---|---|---|---|---|---|
| Epoch 1 | 0.28 | 0.342 | 0.246 | 0.289333 | 0.048676 |
| Epoch 2 | 0.472 | 0.418 | 0.438 | 0.442667 | 0.027301 |
| Epoch 3 | 0.572 | 0.628 | 0.544 | 0.581333 | 0.042771 |
| Epoch 4 | 0.622 | 0.672 | 0.572 | 0.622 | 0.05 |
| Epoch 5 | 0.718 | 0.75 | 0.706 | 0.724667 | 0.022745 |
196x196
| 1 | 2 | 3 | Avg | STD | P-Value | |
|---|---|---|---|---|---|---|
| Epoch 1 | 0.264 | 0.362 | 0.324 | 0.316667 | 0.04941 | 0.5324 |
| Epoch 2 | 0.468 | 0.416 | 0.5 | 0.461333 | 0.042395 | 0.5563 |
| Epoch 3 | 0.562 | 0.58 | 0.542 | 0.561333 | 0.019009 | 0.5003 |
| Epoch 4 | 0.598 | 0.612 | 0.578 | 0.596 | 0.017088 | 0.4421 |
| Epoch 5 | 0.736 | 0.718 | 0.724 | 0.726 | 0.009165 | 0.9245 |
256x256:
| 1 | 2 | 3 | Avg | STD | P-Value | |
|---|---|---|---|---|---|---|
| Epoch 1 | 0.284 | 0.304 | 0.298 | 0.295333 | 0.010263 | 0.8447 |
| Epoch 2 | 0.448 | 0.438 | 0.414 | 0.433333 | 0.017474 | 0.6441 |
| Epoch 3 | 0.562 | 0.536 | 0.53 | 0.542667 | 0.01701 | 0.2194 |
| Epoch 4 | 0.538 | 0.626 | 0.56 | 0.574667 | 0.045797 | 0.2932 |
| Epoch 5 | 0.75 | 0.748 | 0.698 | 0.732 | 0.029462 | 0.7501 |
Discussion:
As we can see, we were not able to reject the null hypothesis, as each p-value was well above 0.05. Ideally, this should be run again for 10 times to account for variance, as the batch size did seem to (relatively speaking) limit our overall accuracy when we compare to earlier scores, however I’m going under the assumption that the results should be the same if batch size was increased equally.
This was further confirmed when I took the 128, 192, and 256 epoch runs that @LessW2020 completed earlier, with p-values of 0.5171 and 0.9401 for 192x192 and 256x256 respectively.
What does this mean?:
It means our model can achieve the same accuracy using a smaller image size, which in turn should decrease both computational overload and training time. This goes against what we were taught, that generally a higher image size would perform differently than a smaller one, as this is what we have seen! However here it’s not quite the case. If we look at the original ImageWoof scores, we saw a change in accuracy of between 3-5% when increasing our image size (55.2%, 60.2%, and 57.6% for 128, 192, and 256 respectively) where we also lead that closer to 192/256 we can expect our “best” accuracy.
Possible Explainations:
Perhaps this setup is very good at generalizing our best line-of-best-fit for this dataset, and we have reluctantly “peaked” as high as we can go. Or perhaps more augmentation was needed. Currently only the base transforms have been used, but utilizing mixup has not improved accuracy at all in previous findings, and even can hinder the results. More work needs to be done on this behavior to see how it is effected at the 20 epoch level.
2 Likes
Nice writeup! I think we need to look at data augmentation more in the future.
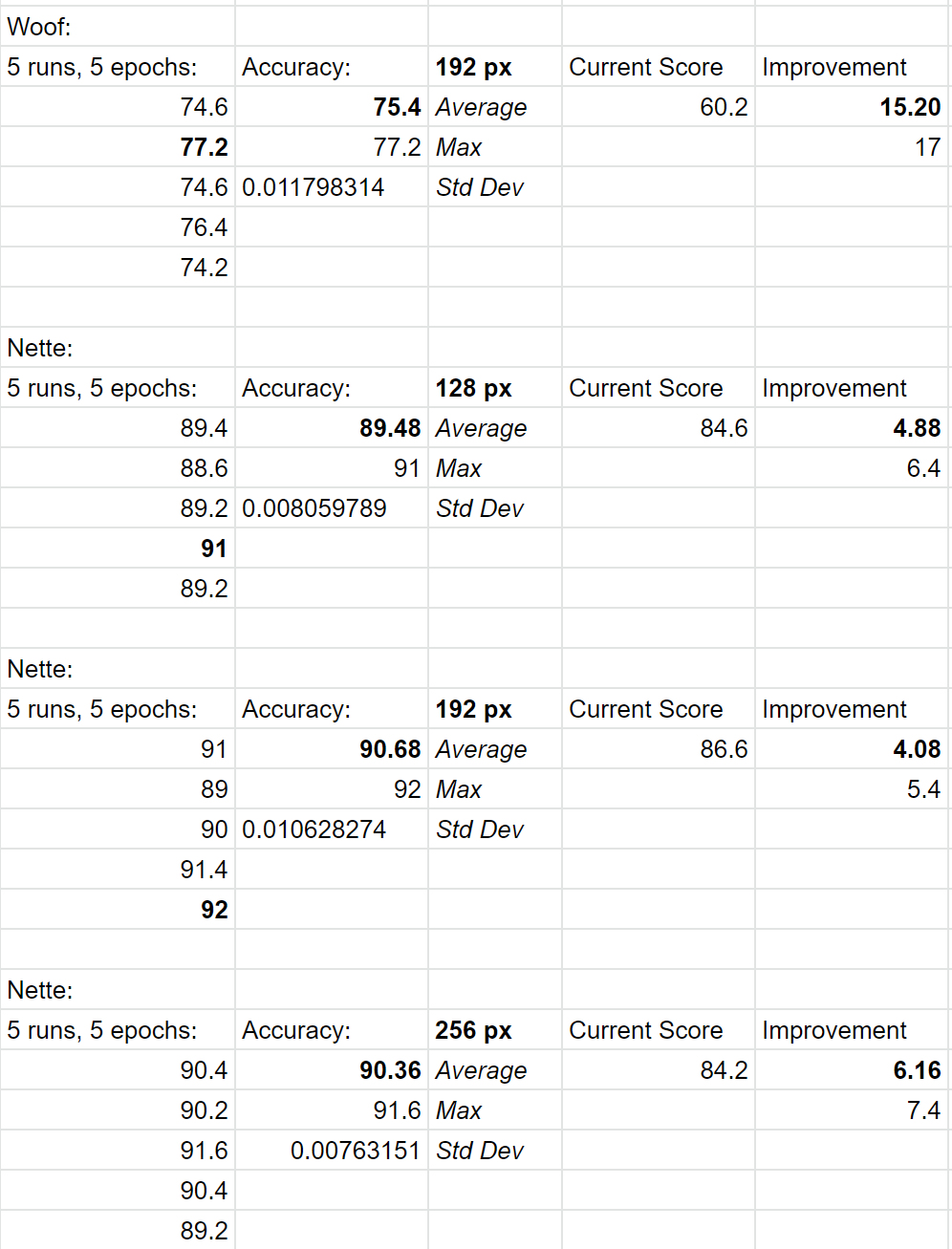
That said, we’ve added 2 more to our medal count - now up to 8x record holders with RangerMishSelfAtt + FlatCosine:

I’m going to PR all these and call it a day
I agree. I’m going to go through all the runs we have done and see if there’s more data hidden away that can lead to a larger picture… I’ll update that post below with those results.
Actually, dang @LessW2020 I’m glad we were as thorough as we were! All the data I need is here ![]()
What sizes with 20 epochs have you/we done with the setup?
1 Like
I’ve only run 128 for the 20 epochs (Nette and Woof).
So, in theory we might be able to get up to 4 more records (192, 256 x Nette, Woof)?
Okay. I’m curious about the above statistics if they hold true then as well. I can probably run a 192 run tommorow
1 Like
Hi guys, great work! I really like how much more open this is than just reading a paper. I am wondering to what extend some of these methods would be transferable to NLP problems (for instance text classification and s2s). I would be interested in starting such a project. However, I think a few decisions should be made with care before starting:
- choosing dataset(s): What I like about Imagewoof and imagenette is that they are small (iterate quickly) but also challenging enough (see difference between models). Of course there is GLUE and superGLUE in NLP but they dont really meet the “iterate quickly” requirement.
- baseline model: for text classification, ulmfit+finetuning would work out of the box, however for s2s you would need a second model. I am aware of the s2s model in the new fastai NLP course, however I felt that it was great for educational purposes, but not yet state of the art (for instance, it didnt use any pretraining).
Sorry for posting this here, but it would make sure this would get your attention. I would love to know your thoughts on this
Hi @koenvdv! Glad to have you in the conversation I’ve had thoughts on this as well! (I plan on trying segmentation too!)
A few thoughts:
Try IMDB. It can still have improvement and is relatively fast to train. As a small test you could use IMDB_SAMPLE and make sure everything seems okay. I can’t 100% recall what my usual accuracy was on that at this very second, but I know that it certainly wasn’t above 90.
The models we have are pretty darn good (ULMFIT), I’d like to see trying to just plug and play these methods in whenever possible, optimizer being the obvious choice, and then certainly the activations’
The others may chime in with their thoughts as well!
@koenvdv Would highly suggest to try the WMT En - De dataset. The paper by Google Brain on Swish have mentioned the Benchmarks of Swish on that dataset for NMT task.
1 Like
Also good news gang! If you update the library, learn.fit_fc() now exists 
Edit: not quite. I typo’d a dependency wrong! (from fastai.callback instead of callbacks)… will update when it gets merged 
2 Likes
Thank you for doing awesome work. Few questions.
-
If i understand correctly you guys are using resnet. I wonder if you change the network the same conclusion could be reached ? The reason I am asking this questions its because in the recent efficient paper, they clearly demonstarte that higher resolution leads to better accurracy.
-
There was a recent paper that achieved new state of the art using resolution trick here is the link: https://arxiv.org/pdf/1906.06423v2.pdf . I wonder how this match up with your conclusions?
-
In this experiments you guys are training from the scractch. I wonder if same conclusions will hold if you did transfer learning ?
Thank you again for doing great work.
2 Likes
To a certain extent we are, but it’s turned into much more than a resnet now, as we have Mish activation functions along with Seb’s self attention layer dotted everywhere.
To the test time resolution trick: I’ve read the paper and thought about trying it as it holds promise. I still believe the conclusions are valid though, as we didn’t modify anything to achieve such a state (Maybe with doing so our results could change!)
To transfer learning: we have zero pretrained models for xresnet, hence why the library doesn’t even use them either.
1 Like
Correct me if I am wrong. In your experiments you are training on 4 resolutions from scracth? If this is the case what about reusing lower images weights to train higher resolution model ?
Yes, we have 128,196, and 256. Honestly we haven’t tried transfer learning yet, as with the competition for imagenette/woof that’s not allowed, and all of our efforts have been there. If we can think of a good challenging transfer set to try on perhaps that’s a start. Maybe the UCSD birds dataset. FFT if someone were wanting to try it.
I also may have some people from my study group try it as well ![]()
1 Like
@LessW2020 seems we have a new issue. I’m getting CUDA errors when trying this on other datasets (I tried quickly on birds)
I’ll open up a new issue