Also did we try for the 20 epoch leaderboard yet? A quick test and I beat the current score at epoch 11 
1 Like
I’m reasonably confident we can beat the 20. The bigger issue was just one of time consumed/GPU dollars spent, but I think we should go for it and try to get both 5 and 20 on our trophy case ![]()
1 Like
I’ll run some notebooks here shortly on google colab. I estimate I could probably get those results in ~20-30 minutes, though for efficiency they would be entrapped in 10 separate notebooks, which may not work the best  If not I’ll just run a colab session overnight tonight
If not I’ll just run a colab session overnight tonight
1 Like
Ok awesome! I’ve got a server starting up now, so I’ll spend a bit to see if we can put together a winning score today 
1 Like
well I guess that was a big mistake to setup for v2 on the same server lol.
Anyway, with a new server up and running again…80.6 at epoch 8. Current score is 78.4.
First epoch ended at 84.40…so hopefully a good sign for us to have a new record today.
Will try and get in 5 runs here.
1 Like
How is the relative stability of the loss? I was thinking if it’s still bad perhaps try introducing some weight decay or batch norm?
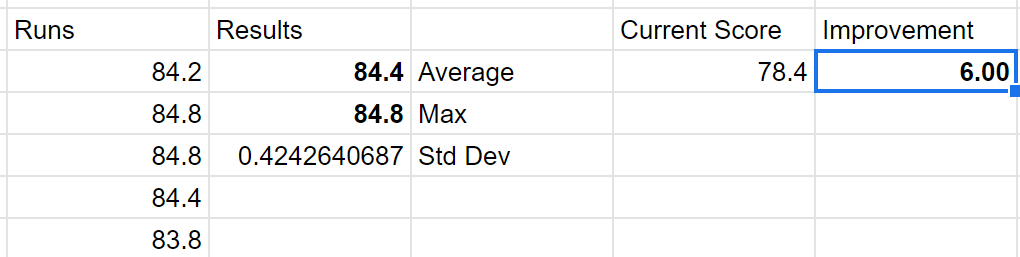
It looks pretty stable - here’s results so far:
84.2
84.8
84.8
84.4
Even epoch by epoch it was fine? I’ve seen a trend of when we begin the annealing loss spikes for a short period
I didn’t see too much on training loss at least. I’m rerunning with a slightly lower lr since I think that will help for 20 runs vs 5.
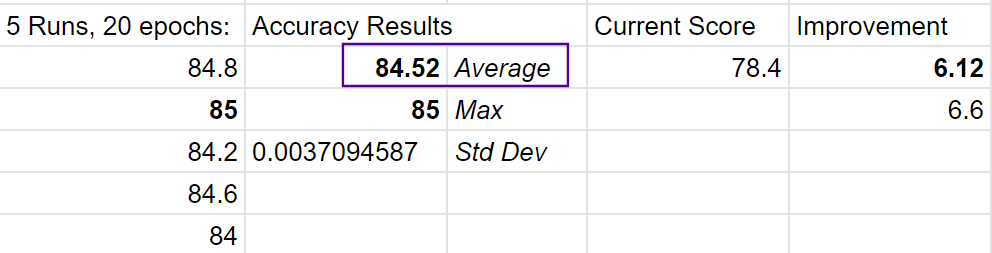
First results:
84.2
84.8
84.8
84.4
83.8
or:
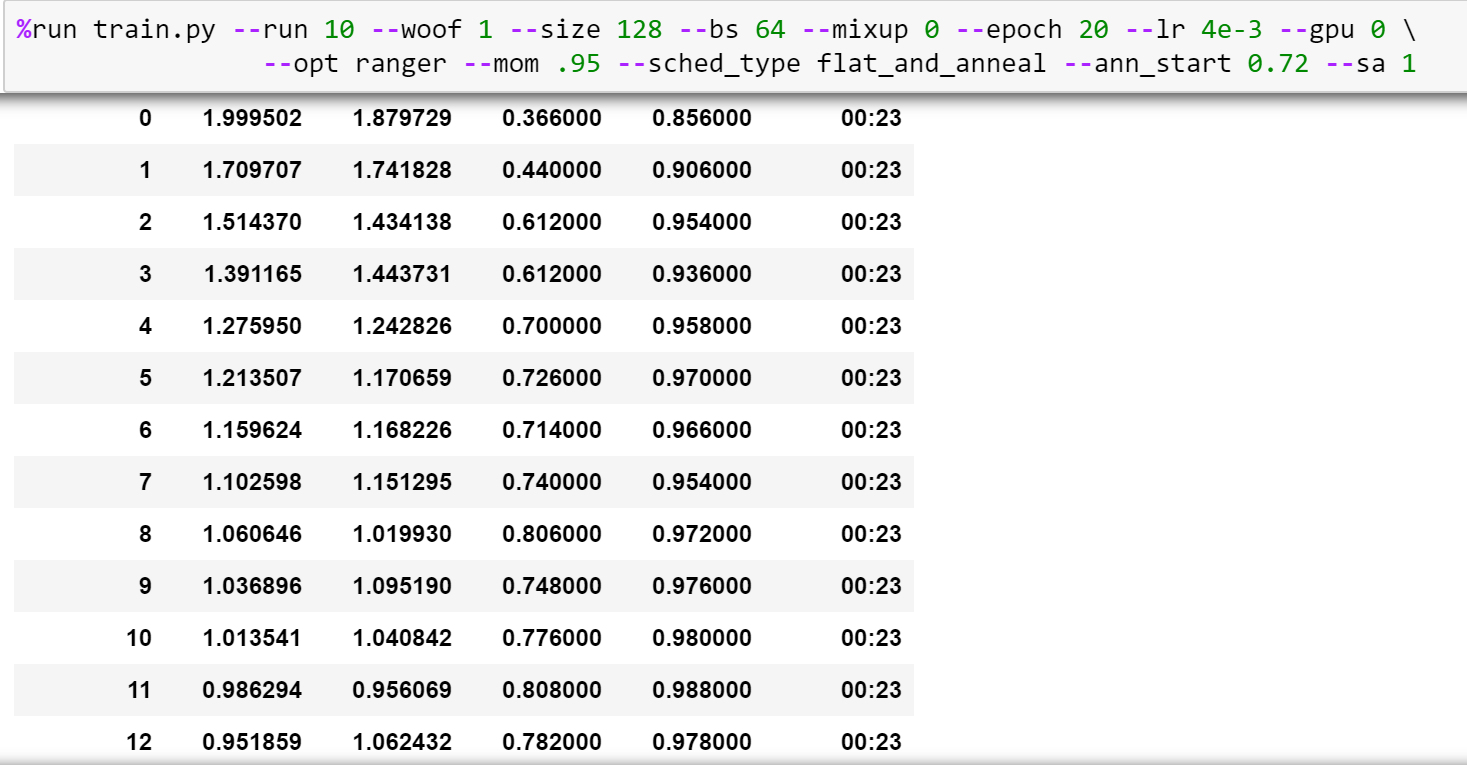
here’s a sample of the training:
I dropped lr a tad to 35e-4 (vs 4e-3) and got 85.20 on first run.
I do think you are right though, there is definitely room for improvement - might be weight decay, we might want to try mixup, etc.
1 Like
When I did initial experiments on 5 epochs I found that mixup was actually hindering, not helping. I can try some weight decay experiments and see if I can’t beat that max. That variance though is very nice
1 Like
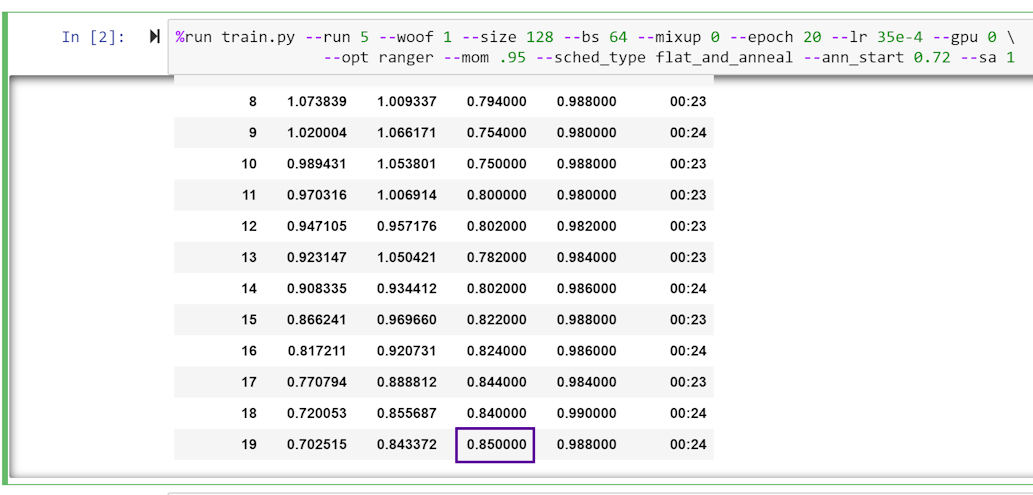
ok lr=35e-4…slight improvement. sdev went down a lot though:
[0.848 0.85 0.842 0.846 0.84 ]
0.84519994
0.0037094587
1 Like
I tested with mixup but results were not improved. (oddly).
Anyway, I’ve put in a new PR for our new 20 epoch record (!):
and a screenshot from the max score:
I’m happy to see our improvements still performing as we extend the epoch window.
I’ll update our repo as well.
1 Like
The only thing that bugs me is the fact of how mixup just doesn’t work here. All the literature says so but with these new optimizers not so much. Perhaps they’re more sensitive to the transforms we choose to use?
Yes, it is odd. I’m planning to do more work this week on AutoOpt and v2 optimizers, but I’d like to test more with additional data augmentation with our setup to try and understand what’s happening there.
I wonder though if the newer optimizers and Mish are simply traversing the loss landscape better and so some of the augmentation is not as helpful? I.e. was mixup helping push it towards better minima, but now is not needed with smarter optimizers? Same thing as the OneCycle?
If that’s the case, that’s kind of neat b/c it says the optimizers are truly helping the AI learn better/faster.
That said, it still seems augmentation has room to further improve it…we may just need to find what works better.
Ricap was kind of ‘too challenging’ for training before (vs mixup) so that might be something to try with Ranger. I also want to test my progressive sprinkles.
Anyway, happy to see we now have both 5 and 20 epoch Woof record! Off to the gym for now.
Enjoy! I am still trapped at work. I’m running a quick test on 256 with 5 epoch to see if it’s maintainable (very small brief test of 1 run). I’ll update those results here
1 Like
My brief run did show success but not as much as I was expecting. 72.6%. Which is an improvement from the 67.6% baseline but again, not nearly as much improvement as I would have thought.
1 Like
I’m going to run 192 right now. (first run 74.6 vs current score of 60.2)
Ok here’s our score for 5 epoch, 192:
[0.746 0.772 0.746 0.764 0.742]
0.754 (vs 60.2)
0.011798314
So I’ll put in a PR for that - it’s a bit off we barely improved vs 128 though, but still a new record.
I’ll try 256 now.
re: 256 - Seb said his selfattention did not perform there (unclear why). It is interesting though why we are not outperforming as greatly relatively though.
That said, I figure we might as well sweep up the leaderboards here even if the difference is not as large. Mostly to set the bar for everyone going forward. I don’t want to spend a bunch of time tuning per resolution.
Maybe the data augmentation will come more into play with higher res?
67.6% on 256px is not the same baseline as usual, it’s my submitted high score from a while back.
1 Like
I’m running 256, 5 epoch right now…getting 75%…I had to double check I had 256 and not 192 as almost no difference in scores so far.
Though I guess that’s not really a big change in resolution overall (192 vs 256)
Ah that would explain it ![]()
I wonder if we’re hitting the threshold of “best this can do”
1 Like