I immediately tried to use the callback with to_fp16() and it broke, so I created a pull request to add support for mixed precision training.
I also added an option mixed_precision_batch:bool=False which rounds up each batch to the nearest multiple of eight for optimal tensor size for mixed precision.
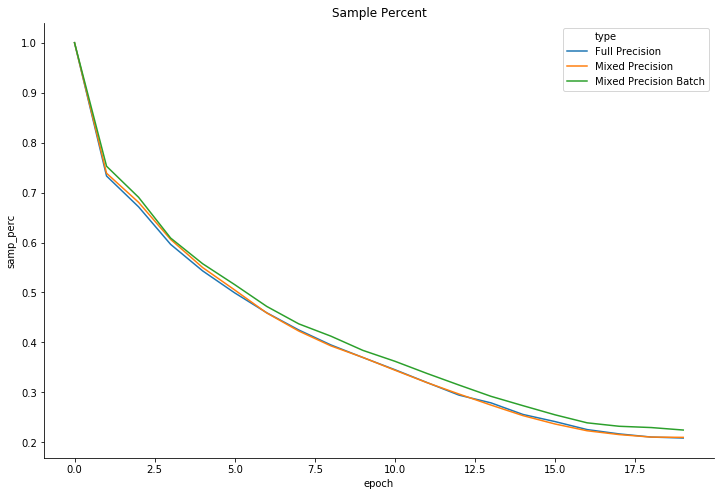
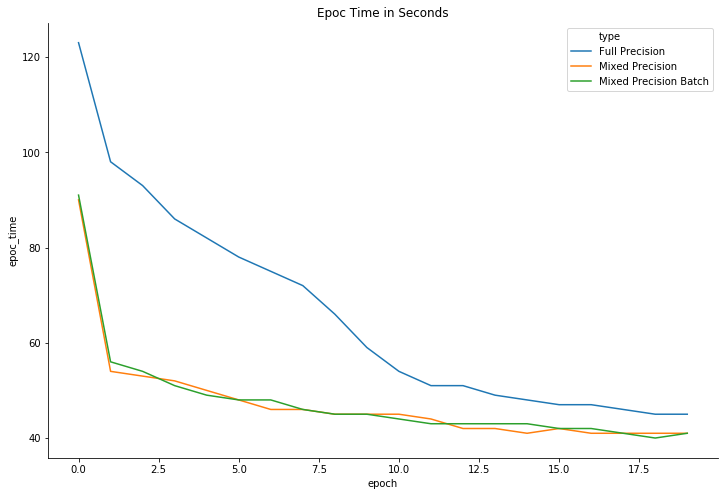
I ran a similar cifar test on a Tesla T4 for 20 epocs in full and mixed precision. Despite using 24 cpu cores, the mixed training was cpu limited. Further testing is needed to see if the mixed_precision_batch option is worth using.
model = models.WideResNet(num_groups=3, N=4, num_classes=10, k=2, start_nf=32)
learn = Learner(data, model, metrics=accuracy).batch_loss_filter(min_loss_perc=.9)
learn = Learner(data, model, metrics=accuracy).to_fp16().batch_loss_filter(min_loss_perc=.9)
learn = Learner(data, model, metrics=accuracy).to_fp16().batch_loss_filter(min_loss_perc=.9, mixed_precision_batch=True)
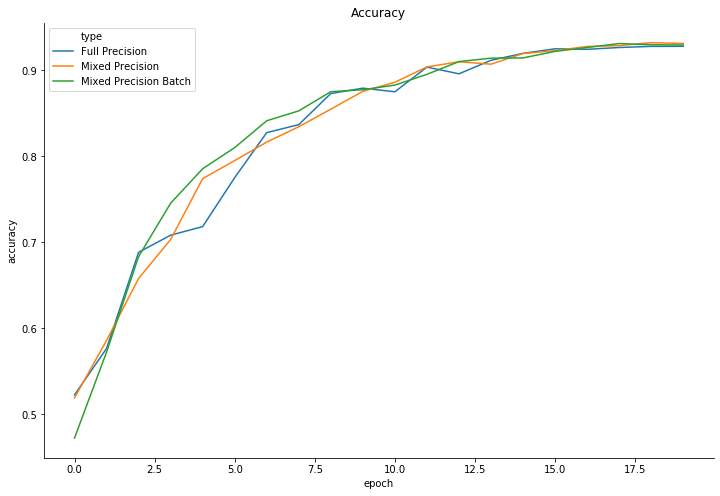
As you’d expect, mixed_precision_batch training has a higher loss percent than normal training.
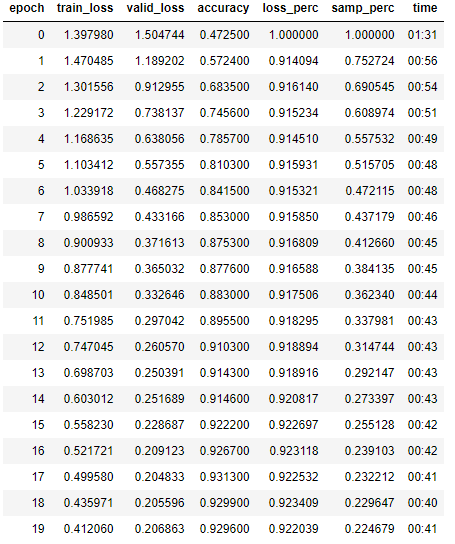
The three modes of training all look very similar otherwise (outside of time).


Currently the callback doesn’t work when predicting n>1 classes, either with flattened loss or non-flattened loss. I plan on taking a look into that in the near future.