Thanks!
The only other one I have is Herring. The results with InceptionTime were also poor in comparison to HIVE-COTE and TS-CHIEF, and with the addition of mixup, it would beat both of them.
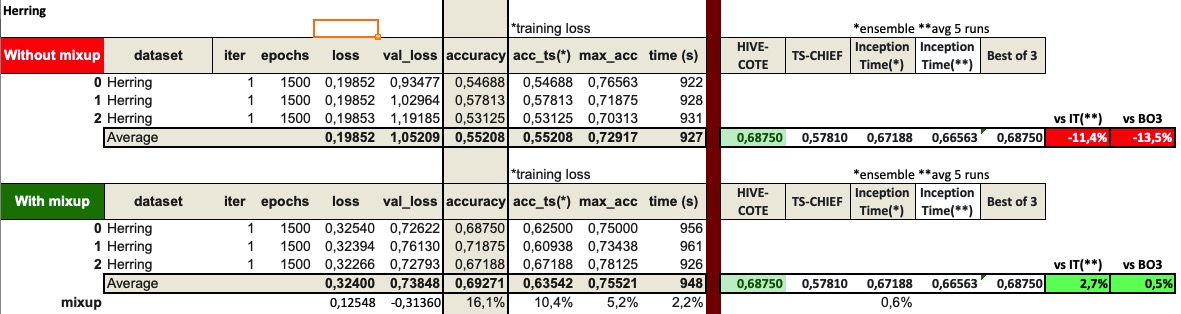
That’s all I have tested (and I’m not currently planning to run more tests as they take a considerable amount of computer time).
EDIT: I may run a test with the new BatchLossFilter if I can find some time. It’s a technique that can also be used with time series.