I’d like to share with you a new callback I’ve created that has worked very well on my datasets.
Last week @Redknight wrote a post about this paper: Accelerating Deep Learning by Focusing on the Biggest Losers.
The paper describes Selective-Backprop, a technique that accelerates the training of deep neural networks (DNNs) by prioritizing examples with high loss at each iteration.
In parallel I also read a tweet by David Page:
Those idea really resonated with me. I’ve always thought that it’d be good to spend most of the time learning about the most difficult examples. This seemed like a good way to do it, so I decided to try it.
The paper’s code base in Pytorch is publically available here.
However, I thought I’d rather implement the idea with a different approach. The idea is very simple: identify those items within each batch that are responsible for a given % (I chose 90%) of the total batch loss, and remove the rest. In this way you force the model to dynamically focus on the high loss samples. The percentage of samples remaining will vary per batch and along training as you’ll see.
So I’ve created a new callback (BatchLossFilterCallback).
It’s very easy to use this technique. The only think you need to do is to build your DataBunch, model and learner and usual, and then:
learn.batch_loss_filter()
That’s it!
I’ve run the callback in CIFAR10, and have shared a notebook within the fastai_extensions repo.
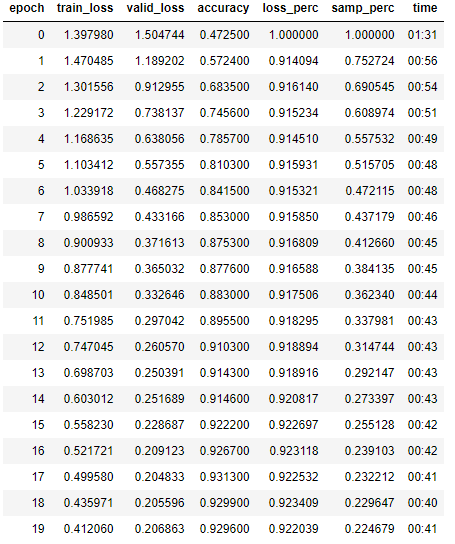
Here these are the test results:
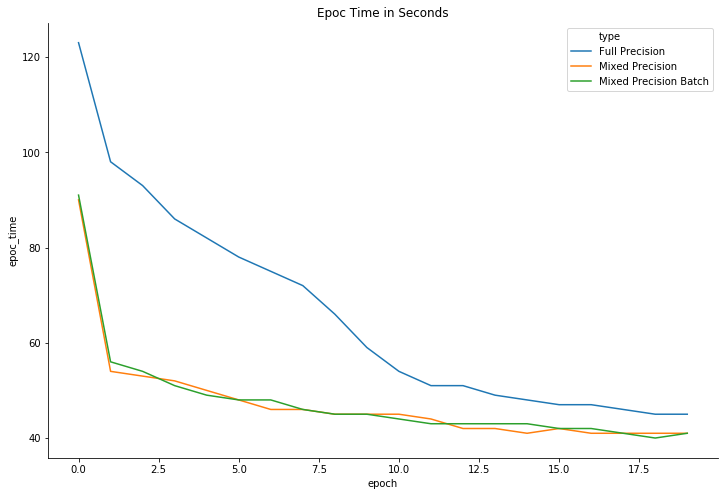
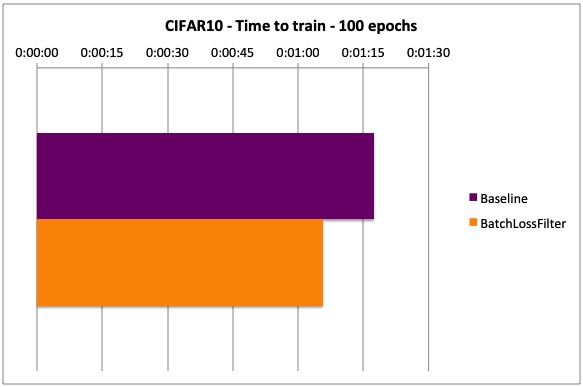
- Time to train (100 epochs): 15.2% less time to train (in spite of the additional overhead)
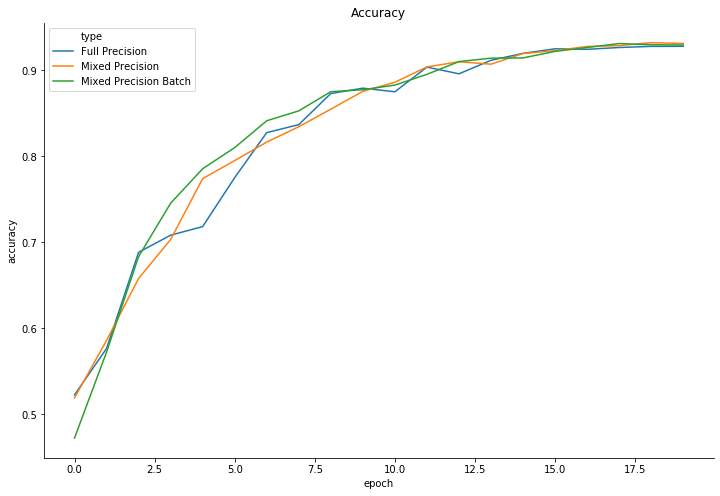
- Accuracy: same as the baseline model (at least in 100 epochs)
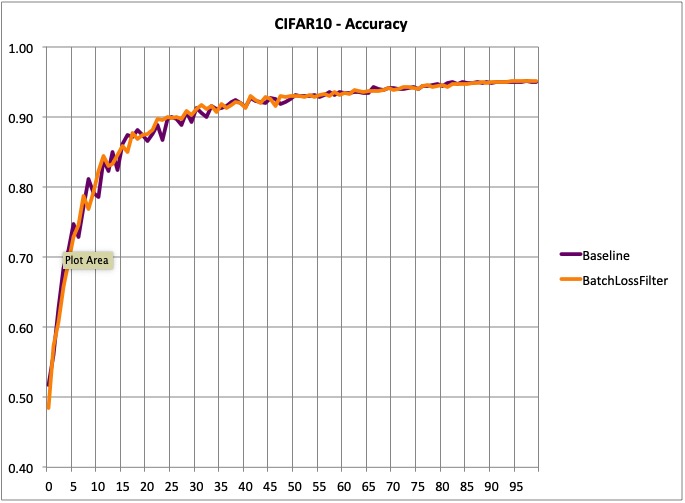
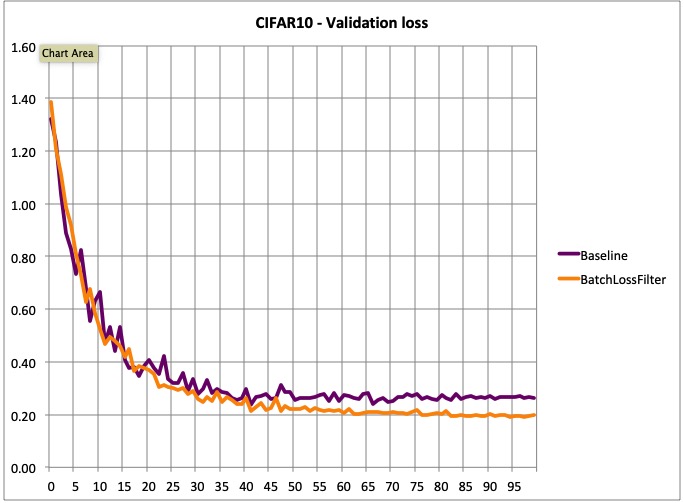
However, training is smoother, and there’s a significant different in terms of validation loss. I believe that with a longer training there could be a difference in accuracy. But I have not confirmed this yet.
- Validation loss: lower and smoother.
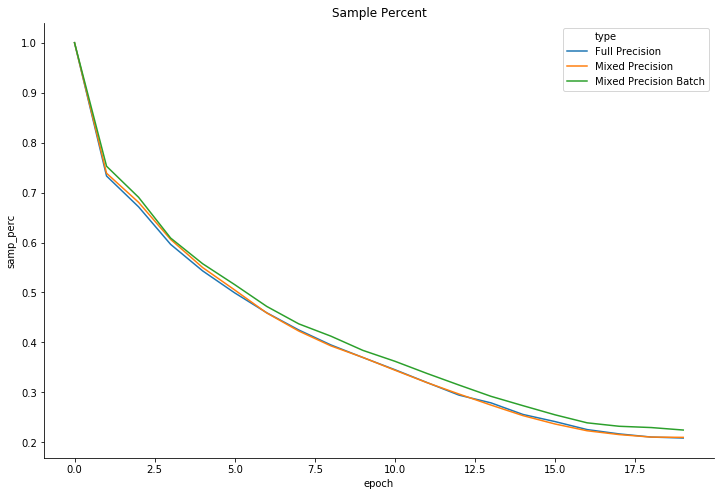
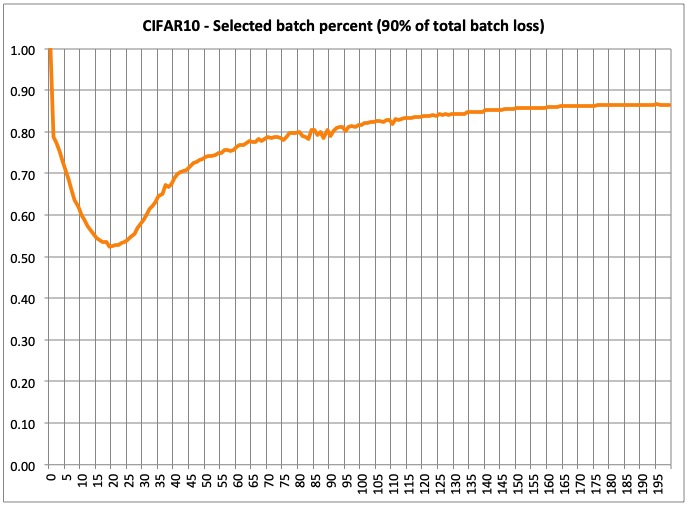
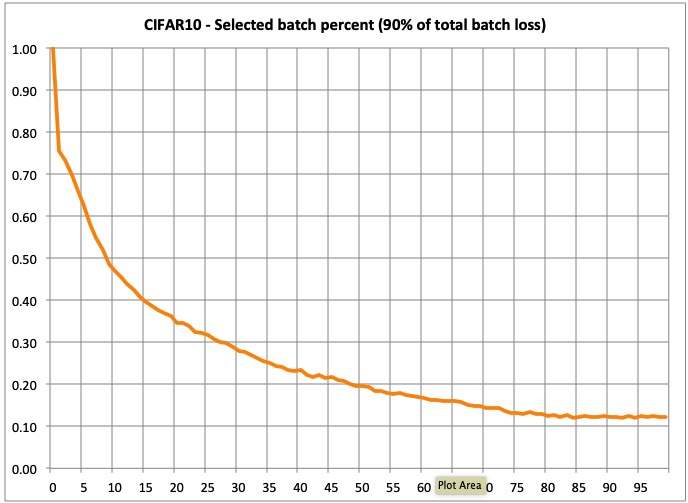
- Selected samples per batch: This is very interesting in my opinion, as it shows the % of samples that make up 90% of the total batch loss. As you can see, 90% of the total loss is initially made by a large % of batch samples, but as training progresses, it dynamically focuses on the most difficult samples. This samples are not necessarily the same all the time, as they are chosen for each batch. In the end, the model will be focused on 12% of the most difficult samples. This is why training takes less time.
Note:
There are actually 2 hyperparameters: min_loss_perc: select samples that make a at least that %, and min_samples_perc: select at least a given % of highest losses. Both can be used at the same time. In my case I just used min_loss_perc.
If you decide to try it, just let me know what you think!
EDIT:
I’ve run the same tests with 200 epochs and the results are pretty similar.
- Training time: 15% reduction (using min_loss_sample=.9)
- Accuracy: same (95.03% for baseline and 95.15% for BatchLossFilter)
- Lower validation loss: BL .281042 vs .182068 for BatchLossFilter
- Selected batch sample percent at the end of training: 13%
So it seems this approach makes the model more certain when it’s right, achieving the same accuracy.
 Thanks
Thanks