I’d love to see the work that some of us have done ported to v2. That’d be awesome!
However, I have a big time limitation. I work with time series, and I’m looking for ways to get a better performance on some proprietary datasets that I use.
I’m looking at different data augmentation techniques (mixup, cutmix, etc,), semisupervised learning, architectures, training approaches, initialization, etc. so my priority is really to make as much progress as I can in these areas. This is pretty time consuming. And I don’t see the time pressure going down for at least a few weeks.
Having said that, please, let me know how can I help.
I’m willing to collaborate as much as I can with ideas, discussing potential approaches, etc. I have already shared all my fastai v1 code (timeseriesAI), and will continue to share any insights/ new code that I get in this area.
Cool results thanks for sharing, these data augmentation techniques seem promising. Can you explain what do you mean fixing the cone layer bias ? Because in InceptionTime I removed the bias from the convolutional layer.
Thanks!
I meant fixing it from my Pytorch implementation of InceptionTime. So now both Pytorch and TensorFlow implementations are equivalent. Neither of them use bias in conv layers.
I know from reading the InceptionTime paper that long time series benefit from long filter sizes. But, is there any kind of rule, or limitation in this sense?
I have a dataset of time series with length 20000. What do you think would be a good set of values to filter lengths to play with it?
I believe that it really depends on your dataset.
If I were you I suggest starting with InceptionTime and tweaking the hyperparameters. Having a very long receptive field is usually good but you risk overfitting if you do not regularize properly.
Finally try subsampling if you have such very long time series in order to gain in speed.
Hope this helps
Thank you! I will play a little bit with InceptionTime hyperparameters. I am currently using the implementation on @oguiza 's repository. Very instructive!
BTW, do you guys know if there are advances in fastai and time series forecasting?
I think it’s always important to try to understand the scale of the differences between classes in your time series.
Sometimes, the difference between classes is determined by a few data points (micro view). This is usually the case in short time series.
In other cases, the difference is due to the structure of the whole time series (macro view).
And in lastly, you may have a hybrid of both.
In the first case, you will need to extract local features to be able to assign a TS to a particular class. In the second one you’ll need to extract global features to do that.
InceptionTime, due to the large kernel sizes, is capable of extracting features from longer sections of the time series, which proves to be a benefit.
However, in the case of very long sequences (like in your case 20k), if the difference between classes if determined by global features, InceptionTime’s longer kernels may not be long enough to identify the required global features. In that case, it may be useful to subsample the TS to create shorter views of it where you apply the model.
Could you please explain what you mean by this, Victor?
Thank you @oguiza! I guess I should definitely go for subsampling…the data comes from physiological signals (like ECG) which are measured every millisecond.
With time series forecasting, I mean the task of predicting future values of a sequence (or a set of sequences) for a given future horizon. I’ve read some papers recently ( Guokun2018 and Shun-Yao2019 ) that use DL successfully for this task, but I am unaware if there is any implementation of this with the fastai style.
Hi Victor,
I don’t currently work on time series forecasting, so I’m afraid I won’t be able to help. There may be others in the forum who who might help you.
The only thing I remember I read was about 2 DL models that perform well in M4, which is a very important time series forecasting competition, help every few years. I think they have been mentioned before in this thread. Here are 2 links to models that perform well:
Both of them have Pytorch implementation in GitHub.
As to the fastai style, the models are in pure Pytorch. So AFAIK, you’ll need to prepare data, and then use the standard training process.
Hi, I tried your code but I have some questions. First there is a error on 12th cell as
ValueError: Item wrong length 100 instead of 48000.
How can we fix it? And last but most important question is “How can I test prediction on a single univariate time series data with this colab notebook?” Please really looking fwd to solve this. Thanks for your code and efforts!
I am struggling a bit to get results with my dataset. I have around 3000 samples with a time series length of 1000. My intention is to use multivariate data, but for now I am using just one variable (ECG signal). There are 3 classes to learn.
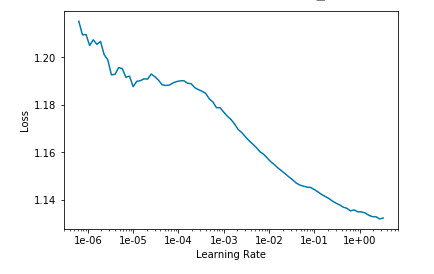
I am trying to use the @oguiza’s implementation of InceptionTime, with a long kernel size (100). I get a curve in lr_find that looks good to me:
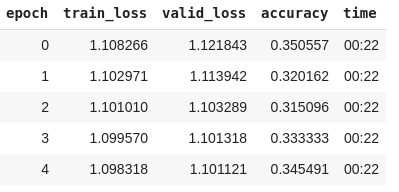
But during training, I see basically no learning of the network.
I’ve played with the parameters of the network (kernel size, depth, even the architecture), but I still don’t see that the network is learning during the first 5 epochs.
So, I am starting to ask myself whether there is something to learn at all. How can I run an easy classifier (aside from DL) to use as a baseline for checking if there is something to learn?
New time series kaggle competition out, prediction task (but single step it seems, so could be treated as regression problem or maybe using tabular too), maybe interesting for some here:
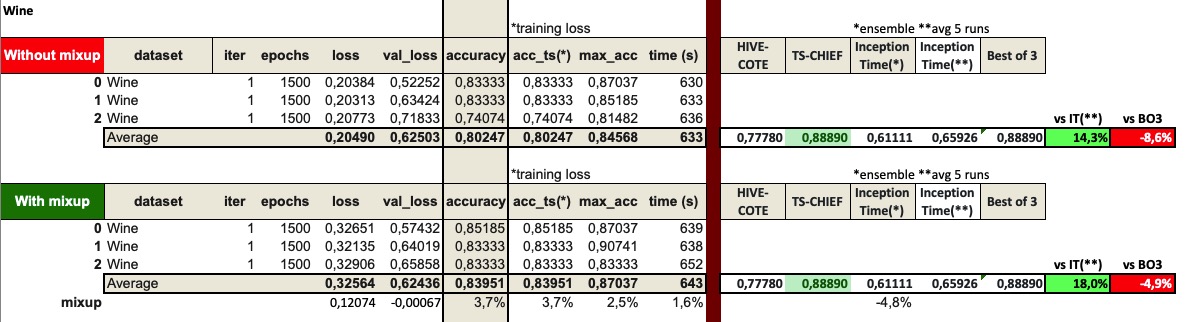
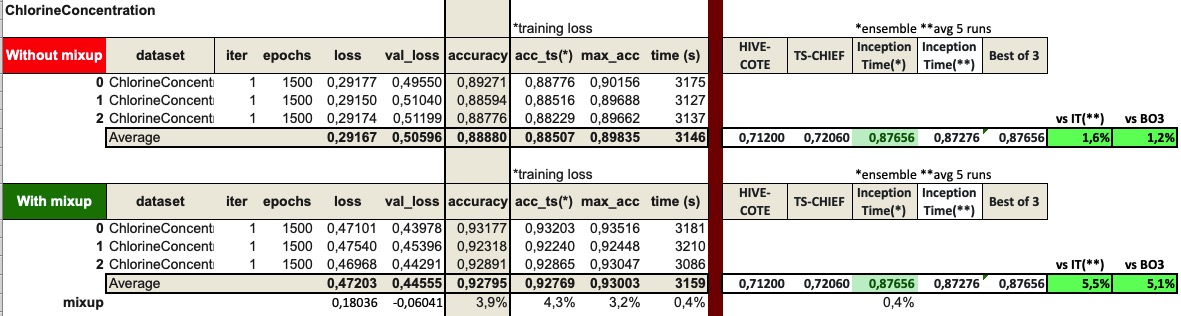
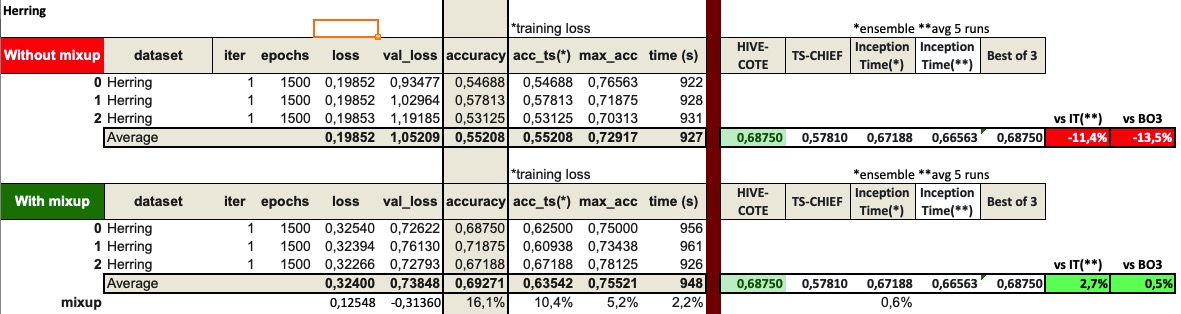
I’ve completed a couple more experiments with InceptionTime and mixup.
I believe they work pretty well together.
I’ve tested the Wine and ChlorineConcentration datasets (worst and best relative InceptionTime performance compared to HIVE-COTE and TS-CHIEF).
I run 1500 epochs (same as in Fawaz’s test). Here are the results:
Thanks!
The only other one I have is Herring. The results with InceptionTime were also poor in comparison to HIVE-COTE and TS-CHIEF, and with the addition of mixup, it would beat both of them.