Looking for help understanding a name … Lesson5 at about 2:04:57, Rachel mentions a name – sounds like Maycheck Zyglowski…
I am not having any luck searching 
Almost sounds like this article, but the author’s name is nowhere near close:
I think they were talking about the Cuyahoga River fires (I spent summers on a farm close by).
Found it!! Maciej Ceglowski
2 Likes
You’re amazing! Thank you!
1 Like
For lesson 5, I cleared out all the sections that have not been started. Here are what the table of contents look like. If you have a bandwidth, please put your name on the header of the section and set the status to “In Progress”. Thank you!!
2 Likes
Thanks heros!  I’ve uploaded lesson 2 (looks like I messed that one up last time) and lesson 4. It’s now setting the timings - will be available soon. 1 and 3 are already there. Let me know (at-mention me) when we’ve got lesson 5, and I’ll add that!
I’ve uploaded lesson 2 (looks like I messed that one up last time) and lesson 4. It’s now setting the timings - will be available soon. 1 and 3 are already there. Let me know (at-mention me) when we’ve got lesson 5, and I’ll add that!
Starting on editing lesson 6 now.
3 Likes
Hi @jeremy!
Some of us were wondering if we can have the captions.sbv files somewhere in fastai Github repo. It is difficult to get them all right at the first time and I noticed typos here and there as I re-watch the videos (some are minor, some are pretty major).
I tried to fix it via YouTube, but for English it is locked saying “The video owner already provided subtitles/CC”:
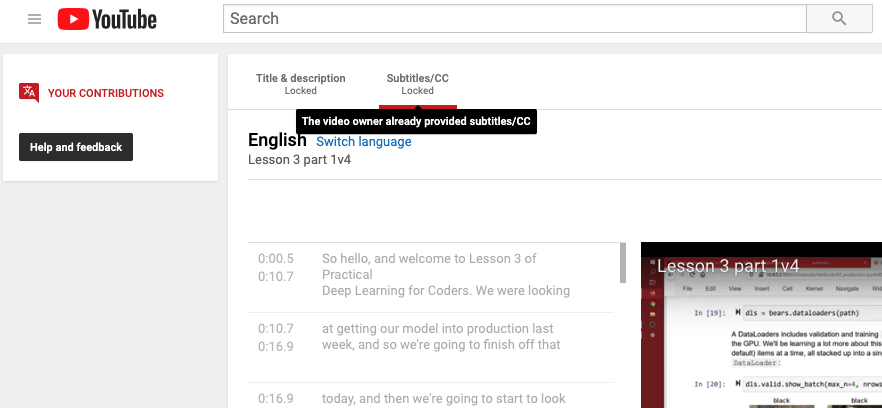
If they were in Github, we can create PRs and continuously improve the overall quality. How does that sound?
1 Like
Having them in Github would be nice in order for us to improve! If we see corrections to our captions, next time we could do better.
1 Like
How about this: if we see mistakes in the Google doc (and some entries have many) we go in and fix them, and add “edited by” and our name?
2 Likes
For me it’s fine either way: it’s also fine if people just fix the mistakes, and don’t add any “edited by”
Having trouble understanding one part of Lesson5 (https://www.youtube.com/watch?v=krIVOb23EH8&feature=youtu.be):
around 1.40.04, Jeremy mentions “Patti Hendricks has trained a language model of me.” … looking for the correct spelling of the name Patty/Patti Hendrix/Hendric
It’s his username pattyhendrix
1 Like
Thanks, again, Hiromi.
1 Like
@jeremy, lesson 5 transcription is done thanks to these amazing volunteers!!
@barnacl 1
@SOVIETIC-BOSS88 9
@lin.crampton 9
@pnvijay 1
@morgan 1
@AndreaPi 1
@jona 1
@Jess 1
@gautam_e 1
Here are splits for lesson 6. Looks like @Albertotono is already hard at work 
- [0:00:00]
- [0:05:01]
- [0:10:13]
- [0:15:39]
- [0:20:18]
- [0:25:18]
- [30.50] Alberto Tono [Complete]
- [38:12] Alberto Tono [In Progress]
- [0:42:18]
- [0:46:32]
- [0:51:06]
- [0:55:17]
- [0:59:35]
- [1:04:02]
- [1:08:10]
- [1:12:40]
- [1:17:19]
- [1:21:32]
- [1:25:55]
- [1:30:11]
- [1:34:37]
- [1:39:08]
- [1:43:42]
- [1:48:56]
- [1:53:23]
- [1:57:44]
2 Likes
At around 57:04, where Jeremy is answering a question about DASK, there’s a part where he’s talking about non-indexable datasets which was quite inaudible (probably since a part of it got cut of from the original video?). Perhaps some one could help with what he says there:
If it’s not indexable, like it’s a, it’s a network stream or something like that, then um the data loaders datasets api’s directly which we’ll learn about either in this course or the next one
Thanks, in advance!
Hi, I assume you meant Lesson 6. From what it seems, Jeremy is saying if the dataset is non-indexable you can’t use the data loaders datasets APIs directly. So its possible it would be something like:
… you can’t use um the data loaders datasets api’s directly which we’ll learn about either in this course or the next one.
Hope this helps.
1 Like
Did one for 6 last on list
This is fantastic! ![]()
Probably easiest, if possible, would be if we can figure out how to “unlock” the captions so that corrections can be contributed?
1 Like