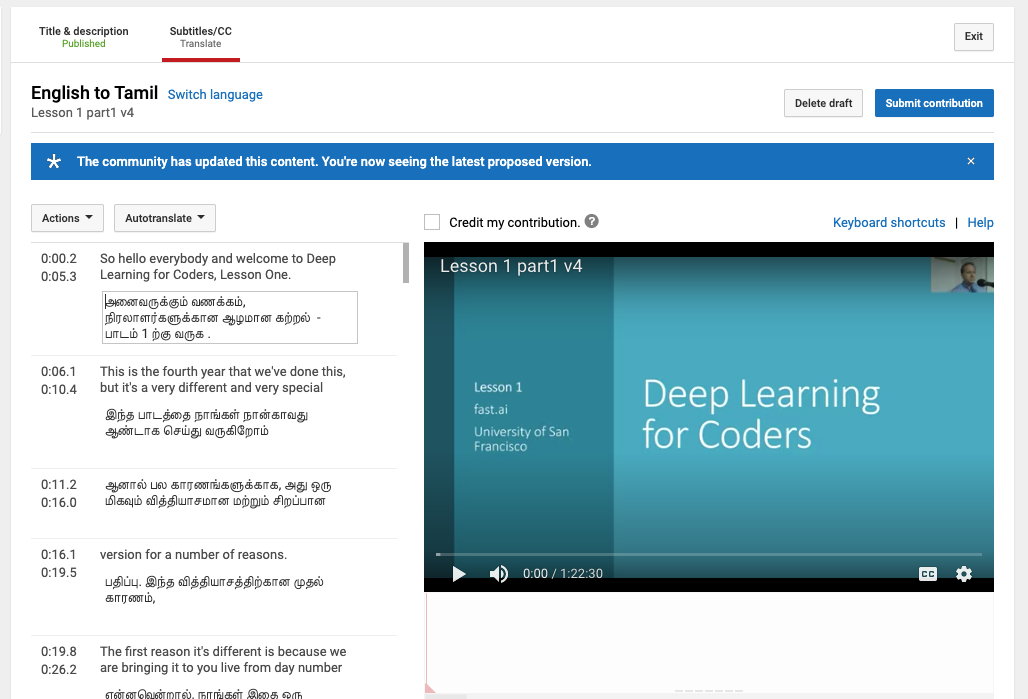
Some of us were wondering if we can have the captions.sbv files somewhere in fastai Github repo. It is difficult to get them all right at the first time and I noticed typos here and there as I re-watch the videos (some are minor, some are pretty major).
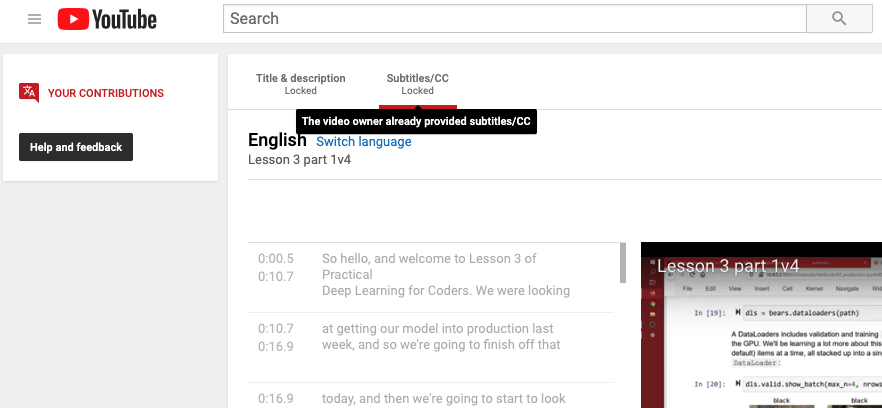
I tried to fix it via YouTube, but for English it is locked saying “The video owner already provided subtitles/CC”:
around 1.40.04, Jeremy mentions “Patti Hendricks has trained a language model of me.” … looking for the correct spelling of the name Patty/Patti Hendrix/Hendric
At around 57:04, where Jeremy is answering a question about DASK, there’s a part where he’s talking about non-indexable datasets which was quite inaudible (probably since a part of it got cut of from the original video?). Perhaps some one could help with what he says there:
If it’s not indexable, like it’s a, it’s a network stream or something like that, then um the data loaders datasets api’s directly which we’ll learn about either in this course or the next one
Hi, I assume you meant Lesson 6. From what it seems, Jeremy is saying if the dataset is non-indexable you can’t use the data loaders datasets APIs directly. So its possible it would be something like:
… you can’t use um the data loaders datasets api’s directly which we’ll learn about either in this course or the next one.
@transcribe-1v4 - thank you to those of you who have stuck with this project so well! And for those of you that haven’t been able to - that’s totally understandable! Now’s a great time to get involved again and help out. I’ve just published the lesson 7 auto-generated transcript:
Pick a paragraph, pop your name above it, along with “status: in progress”, and get transcribing!
great work with Perl, jeremy, thank you. It is a pleasure to help you, and it is amazing to see such great team work, divide and conquer, so upset that this is the second to last lesson. I don’t know if we can wait till September for the part 2 you really help us a lot during this difficult time.
It looks like as long as the owner is not the one who submitted the transcripts, we can continue to improve. For example, I can still edit the Tamil translation that is already published:
BUT! Something only the owner can do is to upload the transcription with no timestamps. So maybe for part 2, we can just download the .sbv file from YouTube and people can update that (leaving the timestamp). So once that’s done, we can submit it to YouTube and Jeremy can publish it. And because we submitted it, it will continue to be editable.
It’s probably too late to change the logistics now, so I think what we can do is once all the lessons are done and submitted to YouTube:
I can download the sbv files that are processed and published.
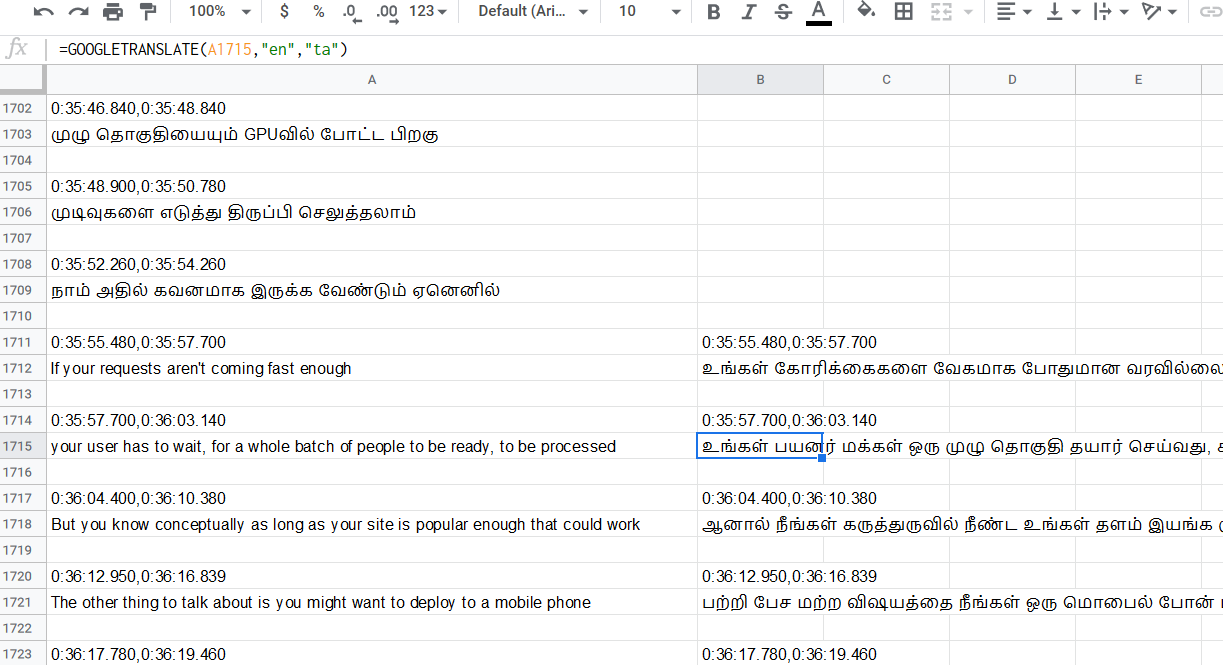
One cool trick for people doing translations, you can load the entire english subtitle file in google sheet and use “googletranslate” function to auto-translate everything to your native language. Once you have corrected the text, we can modify the timings to suit active/passive voice issues.



 you really help us a lot during this difficult time.
you really help us a lot during this difficult time.