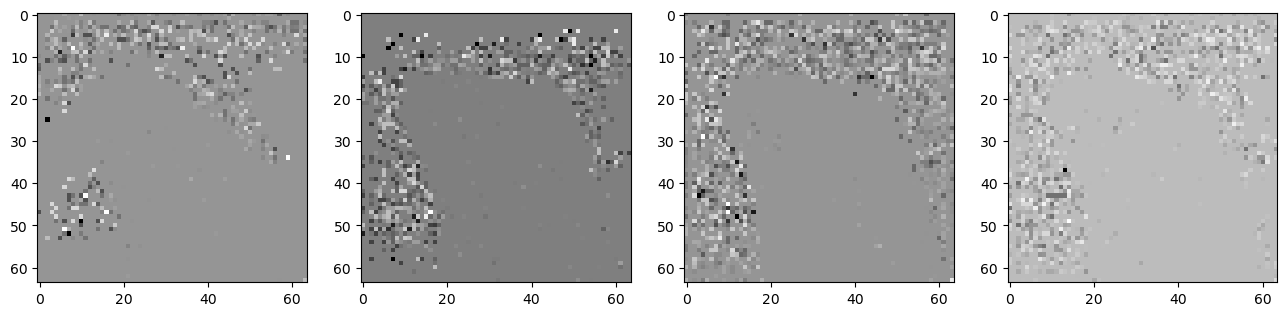
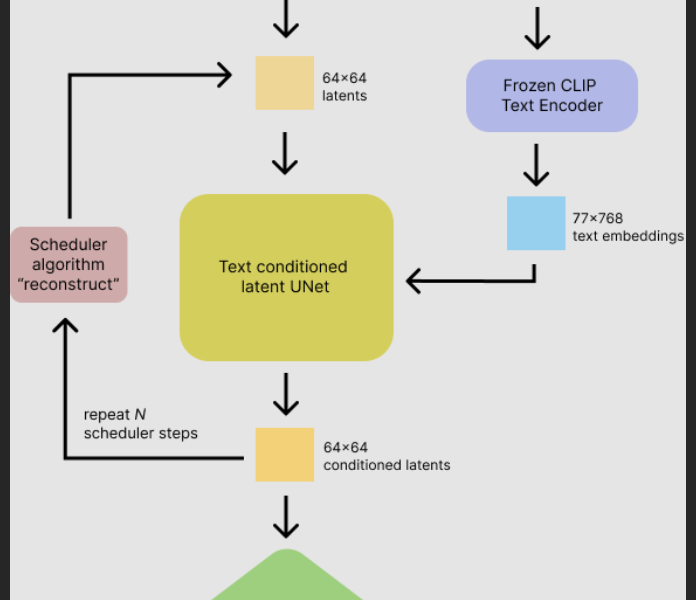
Looking into this and still haven’t quite figured it out but I have found a ‘fix’ that might hint at the issue. Setting start_step=45 or 47 (out of 50) you get a pretty good-looking result. But 46 is a noisy mess (bottom image here). Why 46? Why 4 iterations left? The LMS sampler keeps
order previous predictions and the default is order=4. Switching the code to latents = scheduler.step(noise_pred, t, latents, order = 2).prev_sample for order=2 or (3, also works) and suddenly the result is fine (top). We could try to dig in and see exactly what is up, or you could switch to order=3 or order=2 which seem to avoid the issue (and 47/48 look fine with those too, plus from higher noise levels (lower start_step) I prefer the outputs using a lower order too - bonus day!