Hi @alexredplanet check out the Imagic paper and code from Justin Pinkney
In lesson 10 Jeremy gives a brief overview of the paper ![]()
3 Likes
I’ve had good results modifying an image by modifying the prompt in my PromptEdit code - notebook here.
But to be honest, had not tried something small like changing a frown to a smile. I simply changed an element like one person to another. Will try at some point once I can find a little time and see how it works ![]()
1 Like
Awesome, this is great!
Guys, Since few days, It is possible to fine-tune stable diffusion on cards with 8GB of VRAM thanks to colossal-ai scripts!
3 Likes
interesting that only the last image in each row is different
How can I condition the
unetusing these image encoder hidden states?
I’ve been wondering something related to this – can we swap the CLIP text embedding for a CLIP image embedding somehow?
This Reddit thread also mentions the shape difference and a projection between text and image embeddings.
What I want to use this to do:
- CLIP-embed ~1000 images of auroras (Northern Lights)
- Project these embeddings to a sphere via UMAP
- Sample this sphere, project with UMAP back to embedding dimensions
- Generate synthetic images from these sampled embeddings
- Make an interaction that walks through the Northern Lights embeddings space!
Might have to use CLIP-Interrogator to turn the 1000 images into captions/prompts, then embed those with CLIP and treat them as the CLIP image embeddings. It’s adding a step though!
1 Like
I’m trying to wrap my head around how “information” flows between different subcomponents of Stable Diffusion. I’m a little confused by the relationship between the U-Net and the VAE. It seems to me that they should be very tightly coupled.
But I’m seeing references online to using different VAEs with the same U-Net to get “better” results. And the underlying code clearly allow mixing and matching of VAEs and U-Nets.
How can this work? Doesn’t the VAE define the latent space on which the U-Net operates?
It seems like the output would be highly sensitive to mismatches in this latent space. For example, if I took the original VAE used to encode Stable Diffusion v-1-4 and permuted the latent dimensions, it would still be a valid VAE. I could then use this new, permuted VAE to decode latents provided by Stable Diffusion v-1-4 U-Net. I’d expect to get gibberish.
If I’m right, why is the VAE swappable? Is it only narrowly swappable? For example, maybe you can only use a VAE that’s closely related to the VAE used to define the latent space for the U-Net?
If I’m wrong, what’s wrong with my logic in the permutation case above?
Any help understanding this would be appreciated. Thanks!
1 Like
Why does the CLIP need to be trained before the VAE? Are the outputs of the CLIP model used in training the VAE? If so, how is the CLIP output incorporated into the VAE training process?
Still trying to understand how the embedding data is connected to the structure of the latent space used by the VAE/U-Net.
Any clarification would be appreciated. Thanks!
1 Like
Yes that’s a great point - but that only means you can’t replace the VAE encoder. You can however replace the VAE decoder. You can do so by training a model that learns to translate the VAE latents into a high definition image. It could be done by fine-tuning the original VAE decoder, or by training it from scratch.
The original VAE decoder was trained end-to-end originally with the encoder. But once that’s done, you can train new replacement decoders later that use the same encoder/latents.
2 Likes
Sorry I might have misunderstood the original question and my answer is probably rather confusing as a result! CLIP doesn’t have to be trained first. The VAE and CLIP are independent, so the order doesn’t matter.
I had thought the original question was asking if VAE and CLIP training were entangled/dependent in some way. I’ll edit my answer above.
1 Like
If the embeddings (Generated by CLIP) and the latent space (generated by VAE) are independent, how does the classifier-free guidance “know” that a particular embedding maps to a semantic concept?
I’m still trying to wrap my head around that.
The VAE latents are passed in during the unet training, as are the CLIP embeddings. So the unet learns to associate them.
1 Like
Ah, got it. I think that’s what I was missing.
I was thinking of the U-Net training as the inverse of the U-Net inference (which is it). Except that when we look at the output of the U-Net inference we don’t care about the CLIP embeddings - we effectively discard them since we already have the starting prompt.
But during training everything goes the other way, and the CLIP embeddings have to be provided along with the latent to which we’re adding noise. And that connection during training provides that connection between the semantic meaning of the embedding and the denoising process.
My current understanding is something like:
VAE - ensures that the latent space is regular and dense, meaning that “similar” images are nearby in latent space and sufficiently dense so that there is a submanifold of “valid” images (albeit one of high dimension and complicated geometry).
CLIP - Defines a common embedding that can be used across images and text, such that an image and a good caption for it will have similar vectors in embedding space.
U-Net - During the training process, essentially connects the embedding vectors to the latent space. This is almost like imposing the embedding vector “basis” (in a loose and not necessarily orthogonal sense) on the latent space for the denoising process.
I understand this is a bit more of a geometrical perspective that some of what I’ve seen in the literature, but it helps me connect it with my intuition.
I think this is about right. Any feedback is welcome. Thanks for helping me work through this.
1 Like
Ok. I think I understand.
If you fix the encoder (and hence the latents), a replacement decoder can be trained.
In that case it’s not the end-to-end training of the original VAE, but just training the decoder (which could have a different architecture that the original decoder, etc.) In this training you presumably wouldn’t have a KL regularizing term in the loss function (since the latents are fixed), but you could train with an output matching term and potentially get “better” results than an original decoder (because of an alternate architecture, longer training, additional data not in the training of the original VAE, etc.).
2 Likes
I made a post on how to use the stable diffusion pipeline with TPUs, check it here Stable_Diffusion_in_Flax_TPU.
The only challenge was to get a colab with a TPU backed, I had to try and wait couple days to get that runtime.
4 Likes
I came across a “Cross Attention Control” notebook that might give a way to get the image embeddings you were seeking.
It’s based on a paper/repo by Google called “Prompt To Prompt Image Editing with Cross-Attention Control.” Here’s how they describe the image embeddings/latents:
We reverse the diffusion process initialized on a given real image and text prompt. This results in a latent noise that produces
an approximation to the input image when fed to the diffusion process.
1 Like
For some reason ProgressCB stopped working properly in my environment. I tried creating a new environment from scratch and the problem keeps happening. It clears the plot as soon as it is rendered. Also noticed that the UI of the progress bar is different. There was no update on fastprogress, I wonder what library may have been updated and broke ProgressCB.
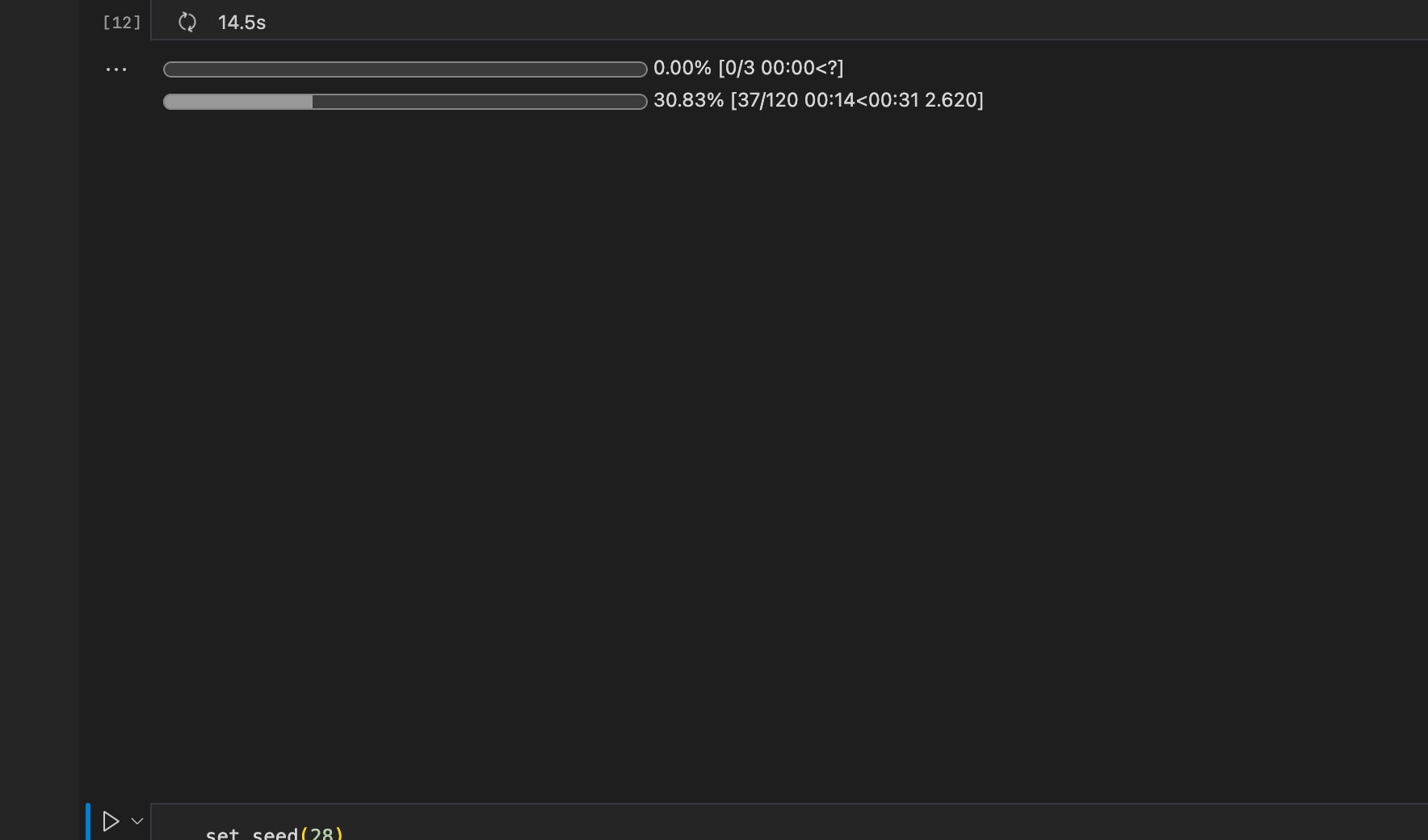
(notice the space in the cell for the plot where it was rendered and then was cleared)
Just here to acknowledge the insertion / update of lesson 9 with the ‘math correction notation’ section.
Also TIL that the nabla symbol (i.e. the upside-down triangle) mentioned in this section is actually called that because nabla in greek means ‘harp’. As a mnemonic, I can think to myself that nobody would bother plucking just one note on a harp, but rather you’d at least want to strum several strings, and so you can remember that that symbol is for the collective version i.e. what happens to the derivative when you change a bunch of values.
(via wikipedia)
7 Likes
i noticed this happens in VSCode. not in jupyter notebook standalone…