In the time between the recording and now, is there any published research or resources on using neural network optimizers like “Adam” for diffusion sampling? I’m referring to what Jeremy was talking about at the end of lesson 9.
When reading blog posts like this it seemed kind of strange to me that the most complicated stuff about diffusion models is the mathematical justification to use the MSE between the actual noise and predicted noise as your optimization objective. This seems as something that can be proven to work empirically but there might also be other approaches working as good or even better… The same goes for how to create the input for the next inference step.
actually the MSE loss is also empirically justified… the weighting in front of the MSE loss is set to 1 simply because it works better and is technically not the most optimal for minimizing the negative log likelihood.
Completed lesson 9. I must say, the topic of diffusers was presented really well. The tangent () of derivative notation was fun too .
Here’s my understanding on how diffusers work, so far.
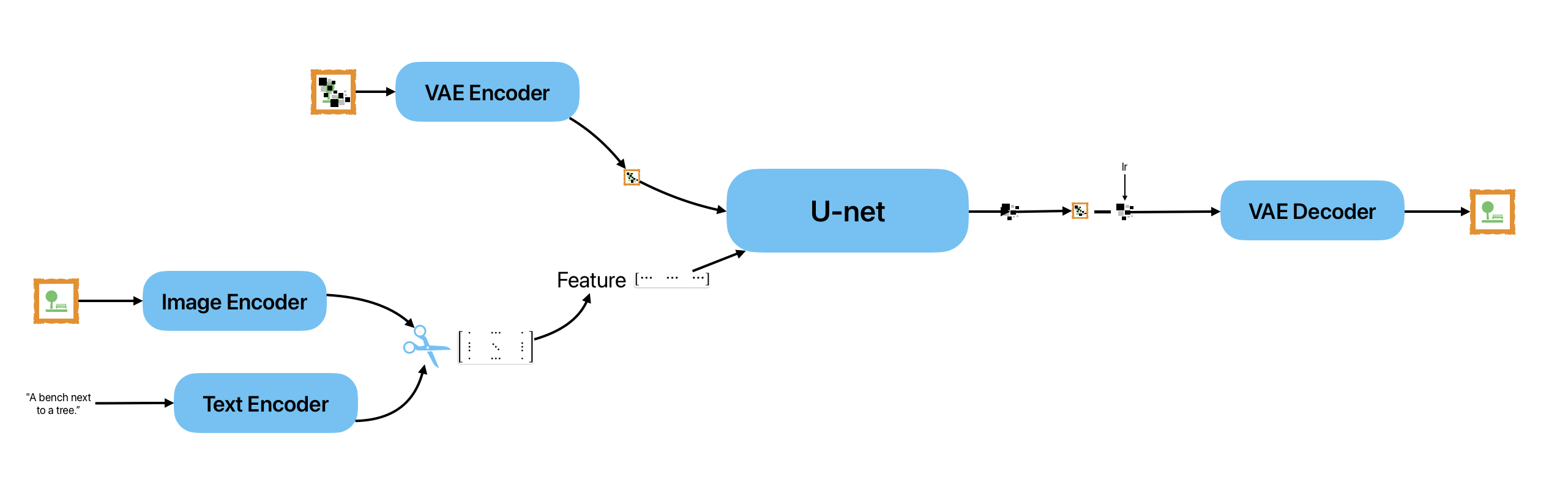
A diffuser has 3 components:
The U-net
The VAE autoencoder
The image/text encoders
You have an image and its description. The image and text encoders respectively produce feature vectors. These vectors are stored inside a CLIP embedding.
The goal of the image/text encoders is to maximize the similarity between the image feature vector and the text feature vector.
Once this is done, some noise is tossed onto the image, and the VAE encoder compresses the image, which is now known as the latent. The latent and its feature vector are input to the U-net.
The U-net attempts to predict what parts of the image are noise, and outputs that noise. This noise is subtracted from the latent in conjunction with the learning rate/optimizer/scheduler. The new, less noisy latent is input again and the process is repeated until desired.
The final latent is then uncompressed using the VAE decoder into a full size image.
Some pictures I generated when playing with the notebook deep dive notebook:
For the image2image part i played with startstep parameter:
with the original startstep = 10:
This was my take on that question. I think the key thing is not to get stuck on lesson 9 thinking that you should dive into everything mentioned during that first lesson / lecture. That’s what the rest of the course is about. If you feel comfortable and understand what was said at a high level, I think it’d be ok to move onto lesson 10 where things get more practical and it’s clearer what ‘to do’ for homework for the lesson.
I like your overview, but i realized it also raises some questions.
For example, when we want to input an image and have it follow that style, where would we put that in? I could see that going into the image encoder and use it as hidden state for the U-net, but it could also be used as input for the VAE and use that latent as input for the U-net. However, at that point I’m unclear as to what the effect is on the result, because you add the noise on the latent representation of the input image and then go through the timesteps? Will it not mainly try to recreate the original image from the latent + noise?
I suppose that the combination of a latent representation of a real image + the embeddings of the CLIP output can produce a combined result as well.
One important note on your description that I also think is not completely correct is that you said
But if my understanding is correct the image is compressed by the VAE encoder, after which the noise is added to the latent. This is in contrast to adding the noise before going into the VAE encoder and using the latent as-is. Maybe I’m misunderstanding, so would be great to get some clarity on this.
From my current understanding, you don’t need to train a diffuser if you want to use an image, instead of pure noise, as a starting point.
The image encoder simply gives the image a numerical representation (an embedding), and the VAE simply compresses/decompresses the image.
If you want to use your own image as a starting point during inference, you simply swap out the noisy latent for it. There’s no need to train a diffuser for this.
You simply compress the image, add some noise to it, and use that as your starting point.
No, I think you’re correct. I think noise is indeed added to the image after compressing it. I’ll edit the post to fix that.
# Load the autoencoder model which will be used to decode the latents into image space.
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae")
# Load the tokenizer and text encoder to tokenize and encode the text.
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
# The UNet model for generating the latents.
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet")
It is clear that VAE and UNet match because they are using the same model “CompVis/stable-diffusion-v1-4”. However, text encoder (CLIP) doesn’t seem related to them, at least not from the model name “openai/clip-vit-large-patch14”. If CLIP doesn’t match VAE and UNet how could the text embedding be compatible with VAE and UNet and how could UNet work things out with the combination of incompatible CLIP and VAE?
For example, say, the output vectors of VAE encoder is in a 4 dimensional space like (a, b, c, d) but CLIP 3 dimensional space like (, , ), neither the dimensionality (4 vs 3) nor the semantic of each dimension (a vs ) is compatible. I cannot understand how a UNet that is only trained with this VAE (same model name) could work with this CLIP.
For anybody who finds it interesting: I just finished a blog post about Lesson 9: the intuition, concepts and main building blocks behind stable diffusion: