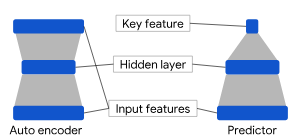
I love your question and I’m going to start with,
TL/DR:
“Sorry, I don’t know exactly why dot product was chosen in this case, but I’m going to make an educated guess that it’s probably because (being the fastest, computationally) it was the first thing they tried, and it worked well enough, and probably changing it out for another measure didn’t (or wouldn’t) make much of a difference.”
Longer answer:
Over the years, I’ve seen a number of hand-wavy general arguments across the web for why one might prefer a particular similarity measure for high-dimensional embeddings, and I have generally found the arguments to be unsatisfying, save for this: dot product is objectively the fastest to compute, and is often “good enough”. In this way, I see a “similarity” with respect to the choice of ReLU activation function over other functions, in that it’s also the fastest to compute and is often “good enough”.
Long ago, Qian et al (2004) found that switching between euclidean distance and cosine similarity didn’t make much of a difference for their retrieval tasks.
The answer in each situation depends a bit on whether the embedding vectors are, say, td-idf scaled for frequency, and whether or not you “care” about the effects thereof. This little quiz from Google highlights how different choices for similarity measures might affect one’s results.
…One may also note that the Transformer models use a dot product similarity where they normalize by the total number of dimensions of the space…which may be another influence on the choice of dot product as a sufficient measure of similarity in this case.
In the CLIP model, it’s been noted that the choice of cosine similarity over dot product was to limit the dynamic range in order to help stabilize training – see Why cosine loss instead of just dot product? · Issue #68 · openai/CLIP · GitHub – but presumably the SD folks found other ways to “stable”-lize things. 
I wish it were feasible for individuals to easily train one’s own Stable Diffusion + T5 model from scratch and swap out the similarity measures to see what difference it makes. Maybe in 10 years some new computing advancement(s) will make that possible.
PS- I look forward to later readers correcting me or filling in the gaps here!
PPS- As an aside: if anyone knows “why” the value of the the cosine similarity of softmax-normalized vectors asymptotes to \tanh(1) as the number of dimensions increases, I’d be very curious to learn.