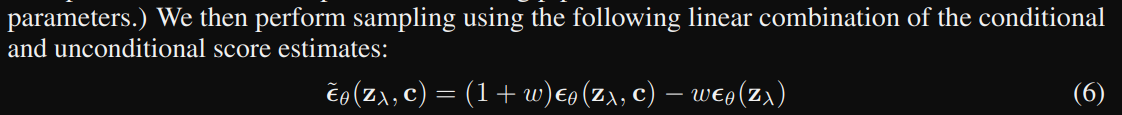I just went through lecture 9, and I’m having a bit of trouble seeing how the three main components fit together (UNET, VAE, CLIP). Maybe this will be clarified in later lectures and I’m getting ahead of myself, but if not can someone please clarify?
My understanding is that we use a UNET to learn the noise of purposely noised images. I understand that VAE is for compressing images so that we can work in lower dimensions. And I think I understand that CLIP allows us to train on both text and images so that their embeddings make sense simultaneously. But how are these things combined?
Are all 3 components trained separately and then combined somehow?
Do we first train VAE to learn latents, then plug those into CLIP to learn text and image latent embeddings, and finally apply noise to the latent embeddings and train a UNET to learn the noise? What is the big picture here?
Your understanding for the most part is correct. Let me shed more light on this based on my understanding.
Let me first illustrate what happens right from the prompt till the end image generation.
Your text prompt (or input) is fed into a text encoder which is another neural network (CLIP).
The embeddings outputted by the text encoder is fed to the UNET along with random noise (in the latent space, i.e., “compressed” image, say latent_noise).
The UNET predicts the noise (say noise_pred) given the latent noise and text embedding.
latent_noise = latent_noise - sigma * noise_pred, where sigma is a factor decided by the scheduler at each inference step.
This updated latent_noise (which is more image-like, in the latent space, than the random noise we had before) is given as the input to the UNET and this process is repeated for num_inference_steps number of times to get the latent space image. This is turned to a “regular” image by the decoder in VAE.
Now, onto the specific components used here:
CLIP: The CLIP github page has an image that illustrates how CLIP works really well. Basically, its text encoder component gives out a vector such that the dot product of this vector with the vector produced by its image encoder component is high. This is not trained for a specific stable diffusion model, but a pre-trained model is used for the training of a SD model.
VAE: From what I remember from the lecture and a little bit of asking ChatGPT, it seems that VAE is trained on the same dataset that the SD model is trained on. This is further confirmed by the initial code snippet in the Stable Diffusion Deep Dive notebook: vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae")
UNET: I think this part doesn’t need much explanation. One understanding of mine is that the UNET model works only with that CLIP model that was used during it’s training and not others.
Scheduler: I don’t fully understand schedulers yet. From what Johno said in lesson 9A, schedulers are like differential equations solvers that get the noisy images closer towards the manifold (in simple words, plane) of the actual images. So, as mentioned earlier, they decide the direction and the step length with which to move the noisy latent towards good-looking-images.
This is my attempt at summarizing my understandings. I hope this clears your doubt.
I might have thrown around wrong terms or explained stuff wrongly. So, feel free to edit this post or correct me
The classifier-free guidance paper gives the formula for applying guidance as shown in the attached screenshot.
But in Stable Diffusion Deep Dive.ipynb, we use the formula noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond) which is different from the one shown above. Another implementation I saw also seems to follow the formula given in the paper.
I tried using the formula as given in the paper, but I did not get the expected results.
Can someone please help me understand why they both are different and what’s happening?
Yes you are correct, position_embeddings are independent of the input text. They are always the same for 77 tokens long input. Notice however that in the above code snippet input_embeddings, which are obtained by adding token_embeddings and position_embeddings, are unique to the input text. These input_embeddings are fed into a transformer based network to produce modified_output_embeddings. These are then used to condition the UNET.
It will probably work. In fact that’s how Jeremy starts lesson 9; Assume that we have a function (NN) that gives us the probability of a given image being a digit. Then derivative wrt to the input image pixels will give us the direction in which the image should be moved.
Hello folks, I have started the Part2 of the course, is it a good way to write the notebooks that are being shared here, tinker and tweak them in my way… Or should i just clone the repo and play with the notebooks in it
hello everyone, I have run into an error while exploring Johno’s Notebook on the Stable Diffusion Deep Dive. In the Diffusion Loop section, I get an error as following:
RuntimeError Traceback (most recent call last)
<ipython-input-4-014b1b53259c> in <cell line: 40>()
49 #Predict noise residual:
50 with torch.no_grad():
---> 51 noise_pred = unet(latent_model_inp, t, encoder_hidden_states=text_embeddings).sample
52
53 #Performing Guidance:
8 frames
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/linear.py in forward(self, input)
114
115 def forward(self, input: Tensor) -> Tensor:
--> 116 return F.linear(input, self.weight, self.bias)
117
118 def extra_repr(self) -> str:
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument mat1 in method wrapper_CUDA_addmm)
This error came when i tried to create and run the notebook from scratch, can anyone help me out with this issue.
Looking at the output error, RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument mat1 in method wrapper_CUDA_addmm), it states that there are tensors on different devices.
Try doing Ctrl/⌘ + F and change all occurrences of 'cpu' to 'cuda' to see if that fixes it.