Thanks @mrfabulous1 I installed an earlier version of sentencepiece
% pip install sentencepiece==0.1.86, and now there is no problem.
2 Likes
@Salazar we’ll start next week May 26th Tuesday, 6-9pm PST. We will silently work on notebooks, then discuss as a group. You don’t have to complete anything in advance. URL to join next week’s meeting: https://meet.google.com/hgw-itjd-hep. Hope to see some of you there!
2 Likes
I am using paper space and I get the following error when running this line of code in notebook 10. I am not sure why it is looking for a pkl file.
dls_lm = DataBlock(
blocks=TextBlock.from_folder(path, is_lm=True),
get_items=get_imdb, splitter=RandomSplitter(0.1)
).dataloaders(path, path=path, bs=128, seq_len=80)
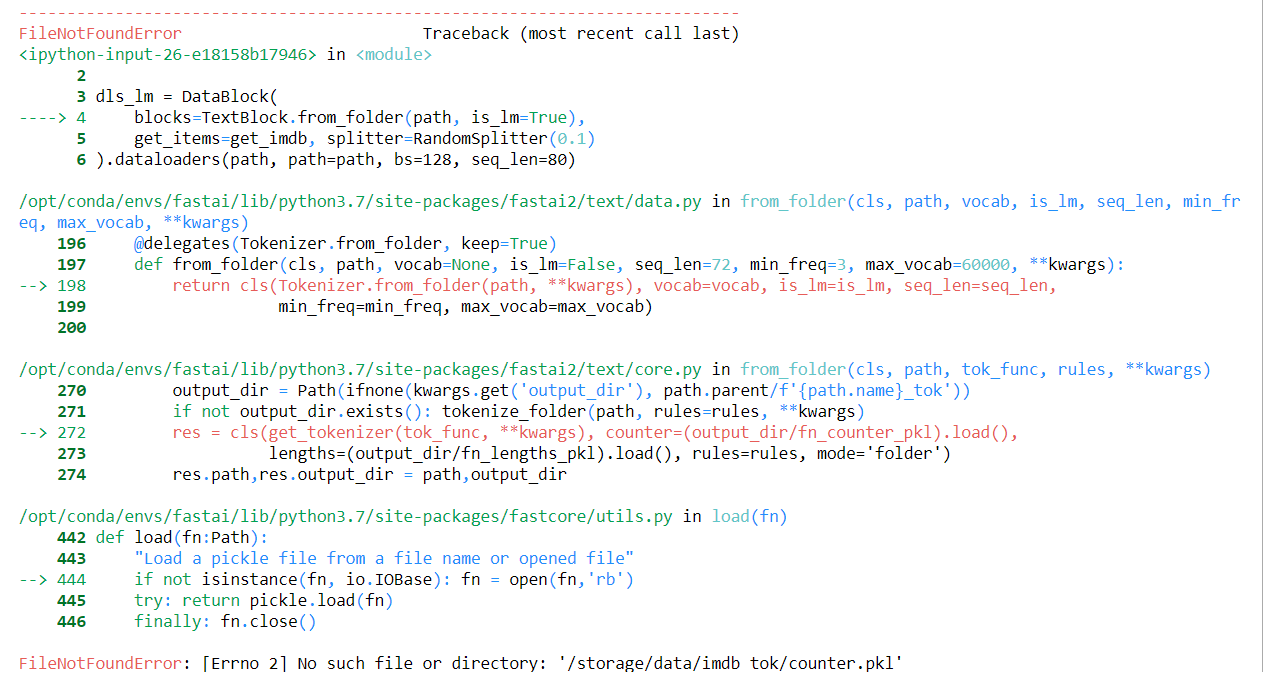
It’s due to the tokenized text information being saved away. This may be a similar issue to what has been going on with the old course and paperspace, where the system path would give issues. A better place for this may be on the paperspace platform discussion? (Where I know mods from paperspace are on often):
Thanks. I will post there.
Is this working for you? I haven’t been able to get it to work in fastai2
How are you passing it in? On Learner or on your call to fit?
Does Fastai2 support multi-gpu training?
Yes it does. Check out the distributed docs: https://dev.fast.ai/distributed @harish3110
1 Like
Finally got around catching up with this lesson. 
Thank you again @jeremy @rachel @sgugger, for making this edition possible despite the unexpected covid-19 happenings all around the world. I personally have had a really hard time concentrating during the last couple of months, I cannot even imagine how you’ve kept this going on without hiccups while taking on more challenges on the side. Hats off and much respect to the fastai team. 
Looking forward to making use of 

 (fastai2
(fastai2  ) during the upcoming months, and hopefully join again for next part.
) during the upcoming months, and hopefully join again for next part.
3 Likes
I’ve a question on the language model from scratch. At around 59:50, jeremy mentions that we can concatenate the words together separated by a full stop. ([‘one \n’, ‘two \n’…] -> ‘one . two . …’)
in the 12_nlp_dive notebook, right after reading in the data.
- Why is the joiner character (
.) necessary ? - Can’t we just use a space instead, since space doesn’t really represent anything else in this dataset ?
- Is it only for this particular dataset, or would we introduce a joiner for language sentences as well, when training from scratch ? I’d assume not.
I’m working on a lang. model from scratch for a non language text dataset, therefore trying to understand the significance of why we add a joiner, and if it might be relevant to what I’m doing.
The . is the token to split the written numbers and you are right, you could also choose a space or any other token thats not used in the dataset.
This special token is only necessary in this dataset- but xxbos xxmaj etc… for example are special tokens used in „real“ text datasets (begin of sentence or uppercase letter).
I would call the . token a Splitter not a joiner. If you tokenize your data on a „sub word“ level you might need a similar token to tell that a new „word“ begins.
Hope that helps.
1 Like
Thanks for the reply.
After thinking about this for a while, I realize that the . is used here to represent the end of a ‘sentence’(only a word in this case), hence representing that idea of a pause from one thing to another.
Has anyone worked on or read about abstractive summarization in NLP using Fastai or PyTorch? Any resources i.e. papers, blog posts etc. would also be helpful! 
@wgpubs blurr library has an example of using BART for text summarisation using fastai and huggingface
3 Likes
Hi friends! I am getting a weird error when trying to load a model
learn_inf = load_learner(model_path)
File "C:\Users\maciamug\.conda\envs\imdb\lib\site-packages\fastai2\learner.py", line 520, in load_learner
res = torch.load(fname, map_location='cpu' if cpu else None)
File "C:\Users\maciamug\.conda\envs\imdb\lib\site-packages\torch\serialization.py", line 593, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "C:\Users\maciamug\.conda\envs\imdb\lib\site-packages\torch\serialization.py", line 773, in _legacy_load
result = unpickler.load()
File "vocab.pyx", line 580, in spacy.vocab.unpickle_vocab
File "C:\Users\maciamug\.conda\envs\imdb\lib\site-packages\srsly\_pickle_api.py", line 23, in pickle_loads
return cloudpickle.loads(data)
AttributeError: Can't get attribute 'cluster' on <module 'spacy.lang.lex_attrs'
This was working last week. Have there been any changes?
2 Likes
When I generate a DataBlock for classification for sentiment analysis of the IMDB dataset, I find that my first few batches are almost entirely padding (xpad). But when I train a classifier, I still get an ok accuracy (0.86 after one round of fit_one_cycle)
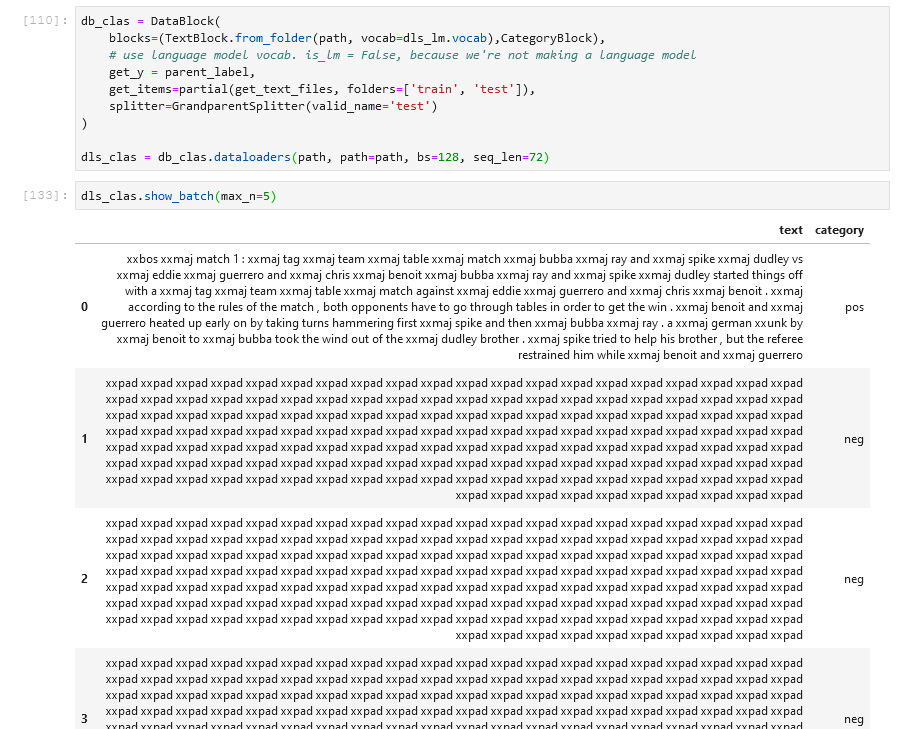
I’ve looked at as many as 50 batches with show_batch, and all but the first batch are entirely padding. Has anyone encountered this? Does anyone have any thoughts on how I can best investigate this further?
1 Like
I do not know the answer myself. But …
From Chapter 10 information about why this is the case
We will expand the shortest texts to make them all the same size. To do this, we use a special padding token that will be ignored by our model. Additionally, to avoid memory issues and improve performance, we will batch together texts that are roughly the same lengths (with some shuffling for the training set). We do this by (approximately, for the training set) sorting the documents by length prior to each epoch. The result of this is that the documents collated into a single batch will tend of be of similar lengths. We won’t pad every batch to the same size, but will instead use the size of the largest document in each batch as the target size.
The sorting and padding are automatically done by the data block API for us when using a
TextBlock, withis_lm=False. (We don’t have this same issue for language model data, since we concatenate all the documents together first, and then split them into equally sized sections.)
My understanding there is a sample in this dataset that is of large size which causes this additional padding tokens. But I do not know how to validate this because of my minimal understanding of SortedDL.
@init_27 @muellerzr - Could you please assist with this question?
1 Like
It’s a bug, however it seems no one has opened a bug report on it ![]() (@jeremy I know you were working on text for a while, I presume you saw this issue?)
(@jeremy I know you were working on text for a while, I presume you saw this issue?)
Doesn’t this mean that most of the sequences inside this batch are far less than the default of 72. As you pointed out, I also feel one sample in the dataset is too long compared to the others