Is this what you’re looking for?
train_idxs = [i for i in dls_clas.train.get_idxs()]
valid_idxs = dls_clas.valid.get_idxs()
Is this what you’re looking for?
train_idxs = [i for i in dls_clas.train.get_idxs()]
valid_idxs = dls_clas.valid.get_idxs()
Yes!! thanks a lot
The answer to your question was answered in last year’s course. You can check the notes here:
The magic value of 2.6 was introduced in the ULMFiT paper officially! ![]()
Don’t think that was the reason cause I have worked on a dataset where the labels in my case was named as ‘sentiment’ and it worked fine.
Maybe this code snippet helps:
blocks = (TextBlock.from_df('text', seq_len=dls_lm.seq_len, vocab=dls_lm.vocab), CategoryBlock())
zomato_clas = DataBlock(blocks=blocks,
get_x=ColReader('text'),
get_y=ColReader('sentiment'),
splitter=ColSplitter())
dls = zomato_clas.dataloaders(df, bs=64)
Interesting, thanks.
Yes, it is quite fascinating. I would assume that Jeremy collected tabular data of all his experiments by noting down all the hyperparameter values chosen and the final metric/score achieved in each case. He would have then applied a random forest model on this data to calculate a partial dependence plot for the lower layer learning rates in order to get the best score.
That’s my best guess anyway! ![]() Maybe @muellerzr or @sgugger could provide more info and insight on this!
Maybe @muellerzr or @sgugger could provide more info and insight on this!
It would be extremely immense if we could see this data that Jeremy worked on! ![]()
From my discussions with him, it dates back to the original ML course. His experiments were done on Rossmann actually! Jeremy’s shared some of his scripts with me for how he got the data and did his experiments @jeremy would it be alright if I shared it here for all? ![]() If so perhaps then we could all attempt to re-create what you performed utilizing the library today!
If so perhaps then we could all attempt to re-create what you performed utilizing the library today!
Oooh! That would truly be awesome! 
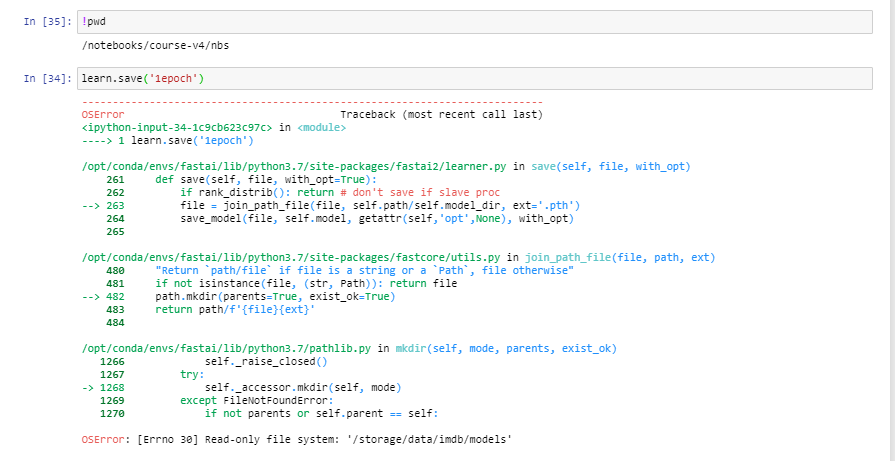
Any solution for this issue?
Hi Megan! Would love to join! Will there be a meet today or tomorrow?
Sounds good, Dan. I’m taking this week off course review to work on a covid hackathon. Meetings start next week.
Can it be @harish3110 that in this example you mentioned your data had only 3 columns: text, sentiment and is_valid?
It seems to me know this could be the key but I am not entirely sure.
sentencepiece throws an error (see below) when I run notebook 10_nlp.ipynb in Google Colab. Has anyone managed to successfully deal with this issue?
In Chapter 12 we create an LSTMCell from scratch as such:
class LSTMCell(Module):
def __init__(self, ni, nh):
self.ih = nn.Linear(ni,4*nh)
self.hh = nn.Linear(nh,4*nh)
def forward(self, input, state):
h,c = state
#One big multiplication for all the gates is better than 4 smaller ones
gates = (self.ih(input) + self.hh(h)).chunk(4, 1)
ingate,forgetgate,outgate = map(torch.sigmoid, gates[:3])
cellgate = gates[3].tanh()
c = (forgetgate*c) + (ingate*cellgate)
h = outgate * c.tanh()
return h, (h,c)
How do I create a single layer LSTM model to use this cell? This isn’t implemented in the notebook. I have tried it on my own but I’m getting an error RuntimeError: size mismatch, m1: [1024 x 64], m2: [2 x 256] at /pytorch/aten/src/TH/generic/THTensorMath.cpp:41 and I’m not sure what the mistake is. Here’s the code for the model and training:
class LMModel6(Module):
def __init__(self, vocab_sz, n_hidden, n_layers):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.lstm = LSTMCell(n_layers, n_hidden)
self.h_o = nn.Linear(n_hidden, vocab_sz)
self.h = torch.zeros(n_layers, bs, n_hidden)
def forward(self, x):
h, res = self.lstm(self.i_h(x), self.h)
self.h = h.detach()
return self.h_o(res)
def reset(self):
for h in self.h: h.zero_()
learn = Learner(dls, LMModel6(len(vocab), 64, 2),
loss_func=CrossEntropyLossFlat(),
metrics=accuracy, cbs=ModelReseter)
learn.fit_one_cycle(15, 1e-2)
Any idea how to fix this?
Can you share output of learn.summary?
Learn.summary won’t work since there is a runtime error.
But you should be able to see the inputs and outputs and then dwelve into the code to check. This is just a suggestion.
Good morning catanza hope you are having a wonderful day.
I am receiving the exact error!
I use the following to repositories at the start of my notebook as this is what, has worked for me.
https://raw.githubusercontent.com/WittmannF/course-v4/master/utils/colab_utils.py
from colab_utils import setup_fastai_colab setup_fastai_colab()
I had to install !pip install sentencepiece this morning and have had the error since then, it is my first attempt at NLP so am a little stuck  .
.
Have you managed to find a resolution for this error?
Kind regards mrfabulous1 
HI jcatanza hope your having a Fun day!
I was trying to resolve this problem on another thread!
The above solution worked for me if you still have the issue!
Cheers mrfabulous! ![]()
![]()