IIRC it’s actually that there’s one review that’s much longer than the others, so the others have a lot of padding. And only the first few tokens are shown, so the non-padding bit isn’t visible.
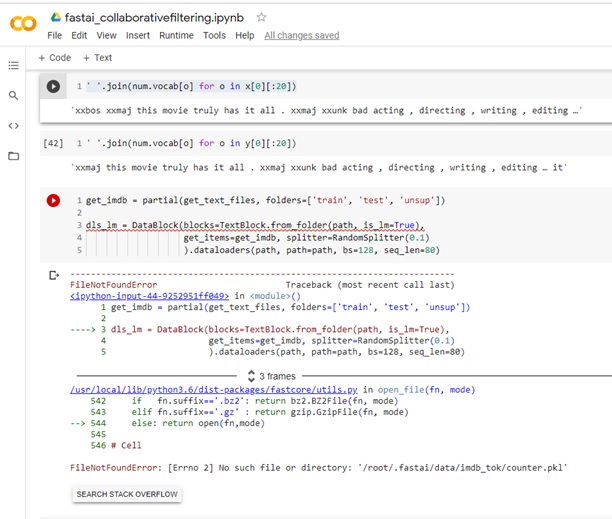
I get exactly the same error, replicated the code in two machines same results.
However I don’t get a good classification error basically totally off.
From lesson #8 running the Notebook #10 nlp Creating the Classifier Data Loader
Notebook #10 everything was perfect up to the language model then when moving into the Classifier Data Loader I face the problem of the xxpad many times.
I understand your explanation on the padding, however the results after the training are completely off which leads me to believe is not the padding issue but a true problem with the data and thus the notebook.
I ran the notebook in two different machines, and get the same problem.
Appreciate your help here.
did u solved it?, I am also getting the same one
Hi Rachel
If I have processed my data with SubWordTokenizer() and created a tmp with spm.model and spm.vocab files. How would I pass this to TextBlock.from _folder() if I want to use it for another model without retraining the tokenizer?
Thanks!
Hi everybody,
I’m not sure if I understand batch size and sequence length for RNNs. In the example from chapter 10, bs is 128 and seq_len is 80. My understanding was that the concatenated text is split in 128 mini-streams, and the first batch consists of the first 80 tokens of every mini-stream. (See the toy example on page 340 in the print version)
When I print the batch however, it looks like it’s the same line 128 times:
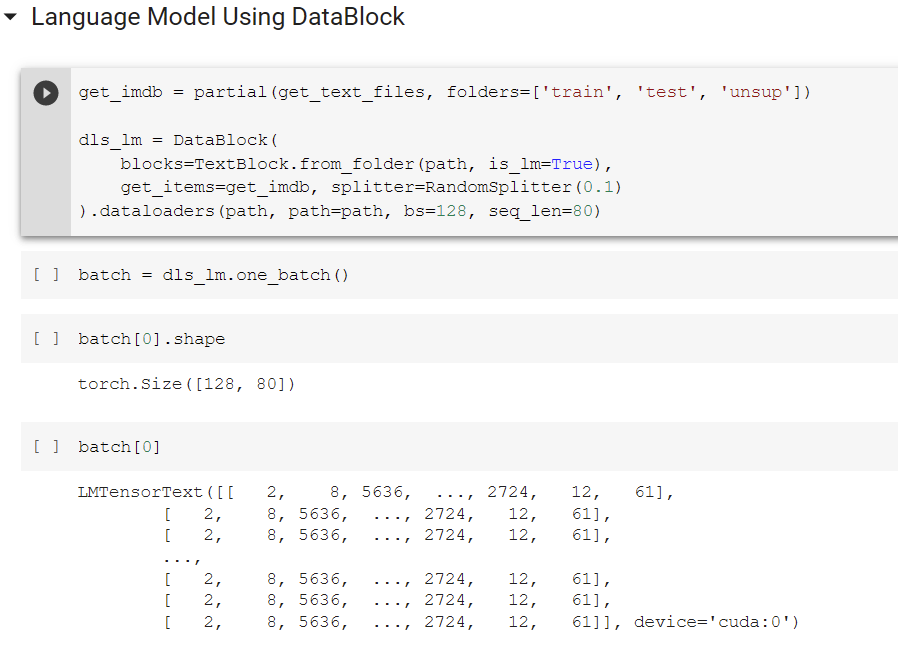
Can somebody explain this? It is not the case when creating the DataLoader manually:

Thank you!
Alright, new day new try. I could not reproduce this today, all lines of the batch are different now (as they should be, following the explanation in the chapter).
I don’t know what caused this, but I’m now pretty sure my understanding is correct of the batches is correct.
Hi everyone, quick question. In the implementation of the Dropout layer, why is the mask defined in this complicated way?
class Dropout(Module):
def __init__(self, p): self.p = p
def forward(self, x):
if not self.training: return x
mask = x.new(*x.shape).bernoulli_(1-p)
return x * mask.div_(1-p)
Why not just use the bernoulli method that is not inplace?
mask = x.bernoulli(1-p)
Thank you for any ideas.
One more question. How does weight tying in the AWD-LSTM work, although the layers have different dimensions?
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.h_o = nn.Linear(n_hidden, vocab_sz)
self.h_o.weight = self.i_h.weight
1 Like
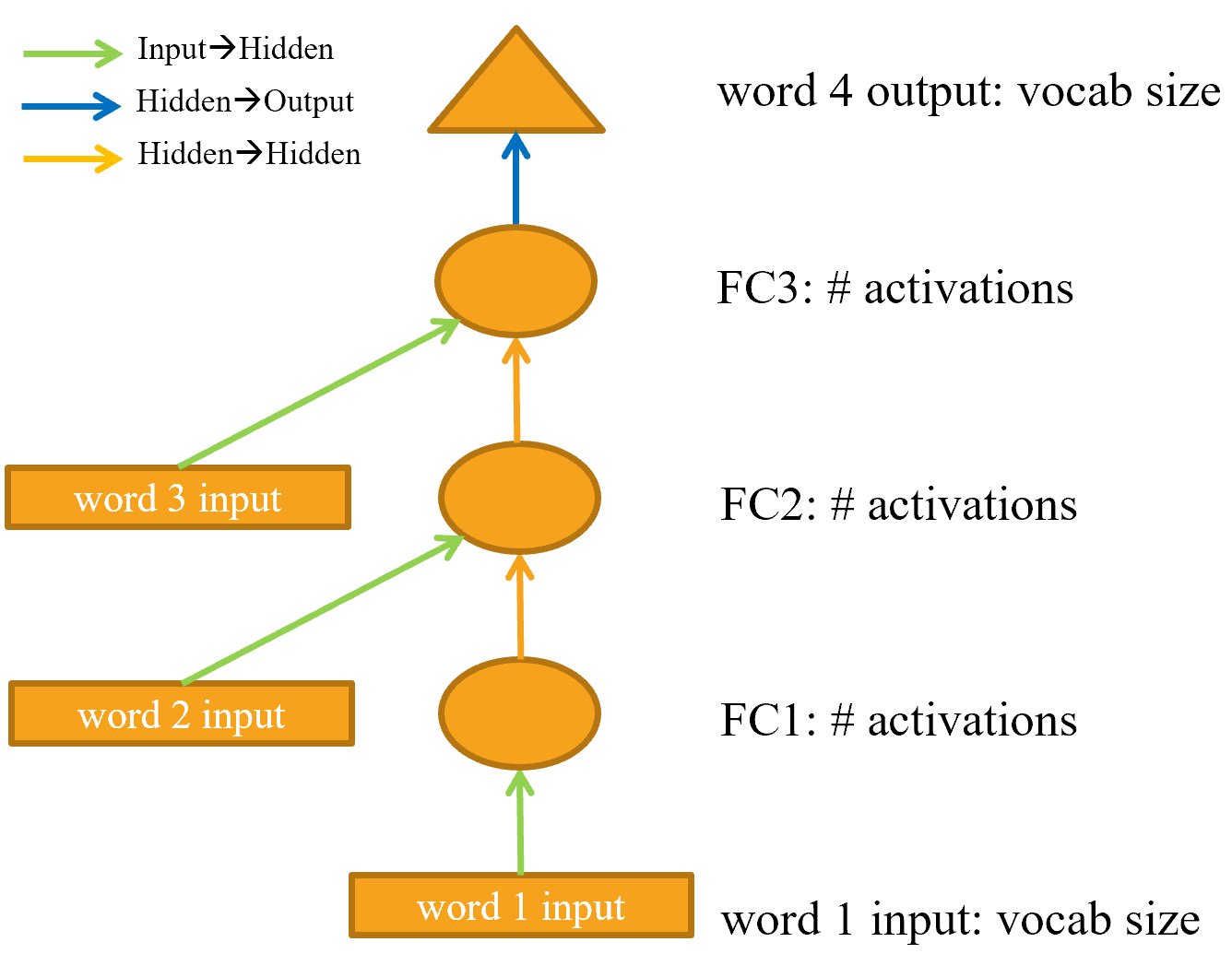
Blockquote
h = F.relu(self.h_h(self.i_h(x[:,0])))
h = h + self.i_h(x[:,1])
h = F.relu(self.h_h(h))
h = h + self.i_h(x[:,2])
h = F.relu(self.h_h(h))
return self.h_o(h)
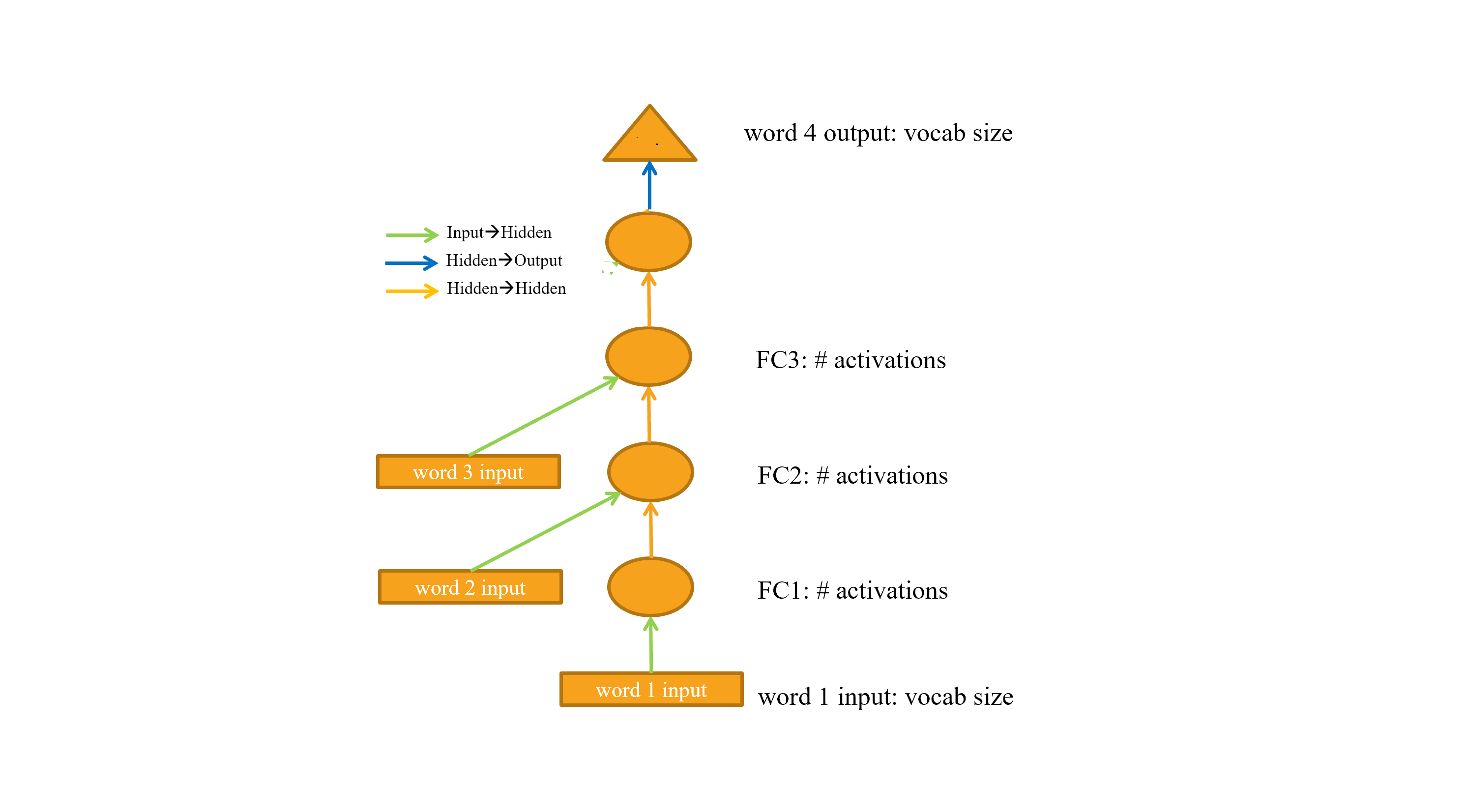
hey guys,i’m little confused by this diagram and the corresponding code,in the diagram there are only two orange arrows(which means self.h_h() + Relu()),but in the code there are three lines of F.relu(self.h_h(h)).So shouldn’t there be another orange arrow before the blue one going to the output?
1 Like
Hi, I think we can view the “circles” as representations of F.relu(self.h_h(...)), the rectangles as representations of self.i_h(x) and the triangle as the representation of self.h_o(h), then it makes sense. The first self.h_h is applied to the input only, that’s why the arrow is green.
But I agree, the text says the colored arrows indicate identical weight matrices, so there should be a third orange arrow somewhere for the image to match the text…
1 Like
but the book says each shape represents activations(no computation) and each arrow represents the actual computation.
for what i learned,the green arrow takes embedding vectors from embedding matrix by input’s index in vocab,the orange arrow does F.relu(self.h_h())
You’re right. Since the first F.relu(self.h_h()) is directly applied to the first self.i_h(), I think it should look something like this, right?
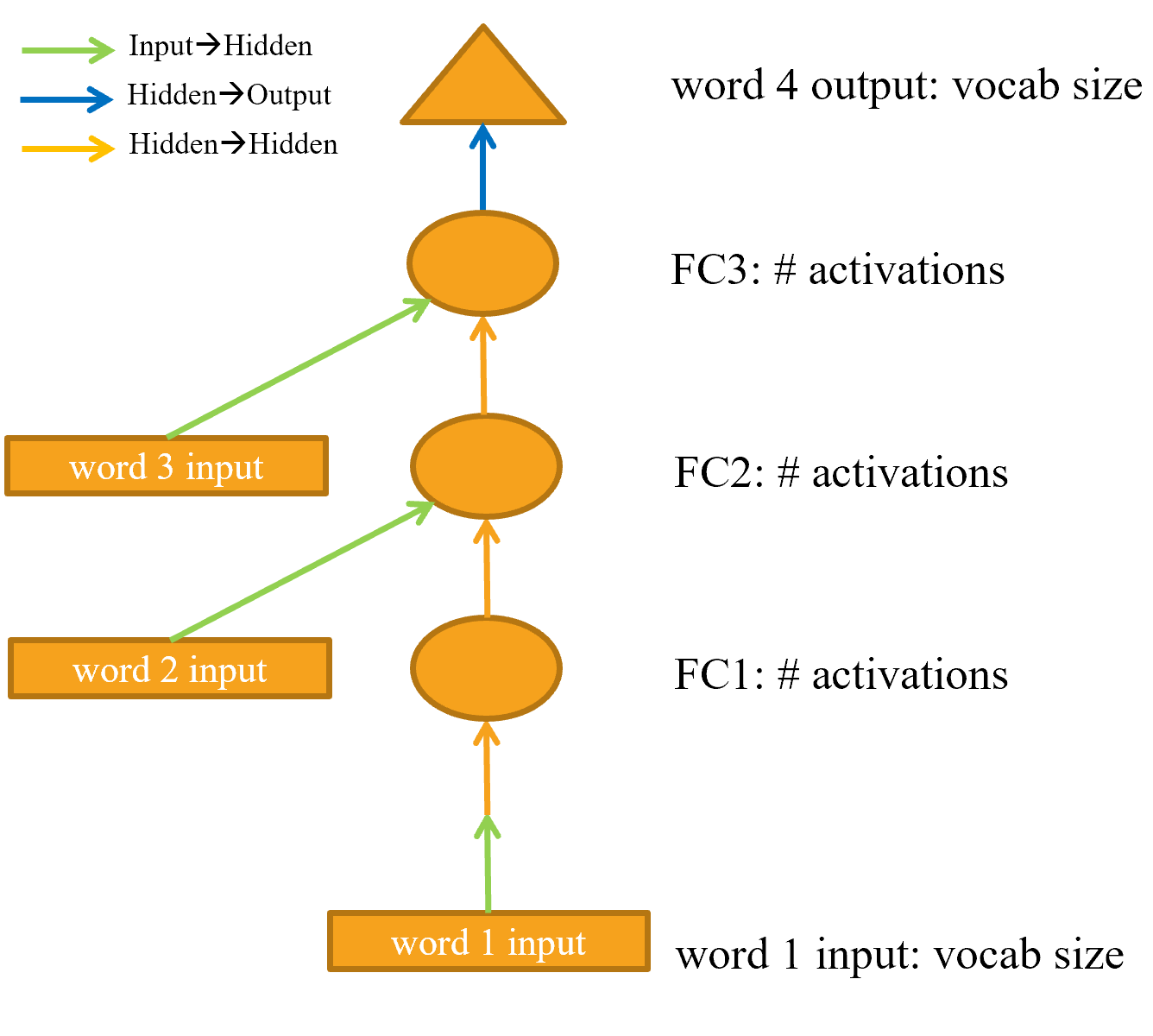
1 Like
Hi, I am looking at the RNN coding block, and I think if we follow this

It would means
h{t} = relu( W_hh * ( h{t-1} + W_ih * x{t} ) )
= relu( W_hh * h{t-1} + W_hh * W_ih * x{t} ).
The weight looks a bit different from the formula under https://pytorch.org/docs/stable/generated/torch.nn.RNN.html, where W_hh * W_ih is replaced with just W_ih. Is there anything conflicting or do I interpret it wrongly?
Did you ever find a solution?
I have a question about how seq_len=72 works in the classifier data loaders (dls_clas):
dls_clas = DataBlock(
blocks=(TextBlock.from_folder(path, vocab=dls_lm.vocab),CategoryBlock),
get_y = parent_label,
get_items=partial(get_text_files, folders=['train', 'test']),
splitter=GrandparentSplitter(valid_name='test')
).dataloaders(path, path=path, bs=128, seq_len=72)
I created the data loaders using the above line. Then I grabbed the first batch & checked it’s shape:
x_batch, y_batch = next(iter(dls_clas[0]))
x_batch.shape, y_batch.shape
The output is the following:
(torch.Size([128, 3345]), torch.Size([128]))
The sequence length is 3,345 in the first batch. So where is the seq_len=72 argument being used by fastai?
I have another question.
The training for the domain adaptation step is drastically slower than the training for the text classifier fine-tuning step. Why is this? The architecture is the same except for the final layer. (The model size is pretty much the same.)
Training for the domain adaptation step takes around 12.5 minutes per epoch:
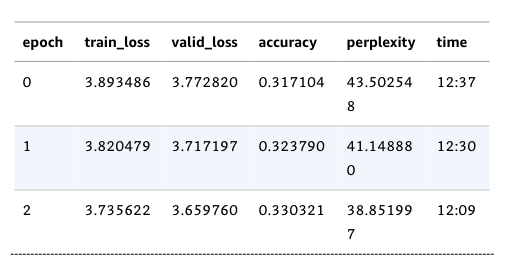
Training for the text classifier fine-tuning step takes around a minute per epoch:
