Use this thread to discuss anything you like regarding lesson 6, including more advanced topics or diversions.
1 Like
In my understanding a context manager is designed to make sure that the resource is reclaimed at the end of the scope of the context. Whereas, in lesson6-pets-more.ipynb we actually return the object which should normally be destroyed by the time we get to return():
def hooked_backward(cat=y):
with hook_output(m[0]) as hook_a:
with hook_output(m[0], grad=True) as hook_g:
preds = m(xb)
preds[0,int(cat)].backward()
return hook_a,hook_g
That feels very unintuitive. What am I missing?
Thanks.
6 Likes
I guess that’s true for most cases when we’re dealing with releasable resources, like files, DB connections, etc. However, I would say that nothing actually restricts one from using context managers for different purposes. Like, for example, I am using the following class to track execution time:
import time
from timeit import default_timer
class Timer:
"""Simple util to measure execution time.
Examples
--------
>>> import time
>>> with Timer() as timer:
... time.sleep(1)
>>> print(timer)
00:00:01
"""
def __init__(self):
self.start = None
self.elapsed = None
def __enter__(self):
self.start = default_timer()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.elapsed = default_timer() - self.start
def __float__(self):
return self.elapsed
def __str__(self):
return self.verbose()
def verbose(self):
if self.elapsed is None:
return '<not-measured>'
return time.strftime('%H:%M:%S', time.gmtime(self.elapsed))
So, essentially, it is a context manager but it doesn’t really release any resources. I guess that similar examples could probably be found in the contextlib module. Like, stdout redirection or warnings/exceptions suppression.
In general, from my point of view, the context manager could be thought of as being an execution scope with some specific condition enforced.
5 Likes
Thank you for the example, @devforfu.
So basically, the use of the context manager object outside of its context is really like a summary/outcome of the execution of the context (obviously programmable by the developer), at least in your example, and the code of the notebook that I quoted.
Sure, not a problem! =)
Right, your description is correct. In these two cases, we use context managers to gather some information from the executed block and getting the summary afterward.
Also as you’ve noted, in general, we can implement __enter__ and __exit__ magic methods however we like. For example, the Kivy UI framework uses the following approach to draw their widgets in the specific graphics context:
from kivy.graphics import *
with self.canvas:
# Add a red color
Color(1., 0, 0)
# Add a rectangle
Rectangle(pos=(10, 10), size=(500, 500))
1 Like
In the hooked_backward() what does the following line do?
preds[0,int(cat)].backward()
def hooked_backward(cat=y):
with hook_output(m[0]) as hook_a:
with hook_output(m[0], grad=True) as hook_g:
preds = m(xb)
preds[0,int(cat)].backward()
return hook_a,hook_g
5 Likes
You suggest to try to add transforms to simulate the distribution of the images that are going to be classified. But imagine that most of the images is normal or under exposed(too dark). I then add augmentation to darken the images. But later when using TTA to classify the images. Should I still use the same transforms or should I add transforms to make them brighter to help the classification to be more correct?
I could just try it myself but I’m interested in your experience in this type of problem if you have any.
I have a question about resolution and pre-trained models. How does fastai manage images as different resolutions? If the first layer is of fixed size (it should be 224*224, randomly cropped from the original images if I understood well this paper https://arxiv.org/pdf/1512.03385.pdf) changing the resolution of the images, in the databunch config, should have the effect of only zooming more and getting a smaller part of the image.
So I really don’t get it when Jeremy, in lesson 6, first trains it at low resolution, and then makes a second pass at higher resolution to improve the performance.
I think I miss an important bit.
Has anyone an idea?
F
Not quite - we use the context manager to remove the hook, since we now have the activations. So it’s the hook that we want to clean up, but the actual activations that we want to return and keep.
2 Likes
It isn’t a crop - but a downsized sample of the middle of the image - which if the image is square for example would cover 100% but at a lower resolution. Zooming gets a smaller portion of the image. Going for a higher resolution will potentially keep more detail that might help the model.
Hi, I’m trying to understand the flow of tabular data bunch.
In the Rossmann notebook for lesson 6, we have:
data = (TabularList.from_df(df, path=path, cat_names=cat_vars, cont_names=cont_vars, procs=procs)
# returns TabularList
.split_by_idx(valid_idx) # returns ItemLists
.label_from_df(cols=dep_var, label_cls=FloatList, log=True)
.databunch())
When I looked into the codem split_by_idx() ultimately returns an ItemLists object. But ItemLists doesn’t have a method called label_from_df() (which belongs to the ItemList class).
What am I missing here?
I also tried to break this into steps:
x1 = TabularList.from_df(df, path=path, cat_names=cat_vars, cont_names=cont_vars, procs=procs)
x2 = x1.split_by_idx(valid_idx)
type(x2)
# returns fastai.data_block.ItemLists
x2.__class__
# returns fastai.data_block.ItemLists
x3 = x2.label_from_df(cols=dep_var, label_cls=FloatList, log=True)
type(x3)
# returns fastai.data_block.LabelLists
type(x2)
# now returns fastai.data_block.LabelLists, the class type was CHANGED?
I’m confused why after calling x3.label_from_df(), the class type of x2 changed from ItemLists to LabelLists?
Thanks.
1 Like
Hey all =)
For the Rossman notebook, is there ever a time where it’d make sense for the best validation loss during training to not equal the validation loss computed after training? My setup is basically exactly the notebook; however after the last learn.fit_one_cycle, rather than jumping into inference on the test set, I tried to do inference using the best returned learner on the valid set:
train_preds = learn.get_preds(DatasetType.Valid)
The flattened mse on that does not equal the best returned flattened mse shown in the learn.fit_one_cycle table above it. Even with dropout and other non-deterministic factors, my understand was that when the model is not in train mode, given the same input it should produce the same output—any thoughts =?
In lesson6-pets-more we change the data size from 224 to 352. If I
print(learn.summary())
beforehand i get:
======================================================================
Layer (type) Output Shape Param # Trainable
======================================================================
Conv2d [1, 64, 112, 112] 9,408 True
______________________________________________________________________
BatchNorm2d [1, 64, 112, 112] 128 True
______________________________________________________________________
etc...
i.e. the first Conv2d is taking a 224x224 and rescaling it to a 112x112
if i then do:
learn.data = get_data(352,bs)
print(learn.summary())
i get:
======================================================================
Layer (type) Output Shape Param # Trainable
======================================================================
Conv2d [1, 64, 176, 176] 9,408 True
______________________________________________________________________
BatchNorm2d [1, 64, 176, 176] 128 True
______________________________________________________________________
etc...
At this point we continue training, what’s going on here? the learn.summary implies the first layer now outputs 64x176x176 but how can we continue training a model if the size of the layers have changed?
What am I missing here?! thanks
1 Like
Here’s how I think we are meant to interpret the below images:
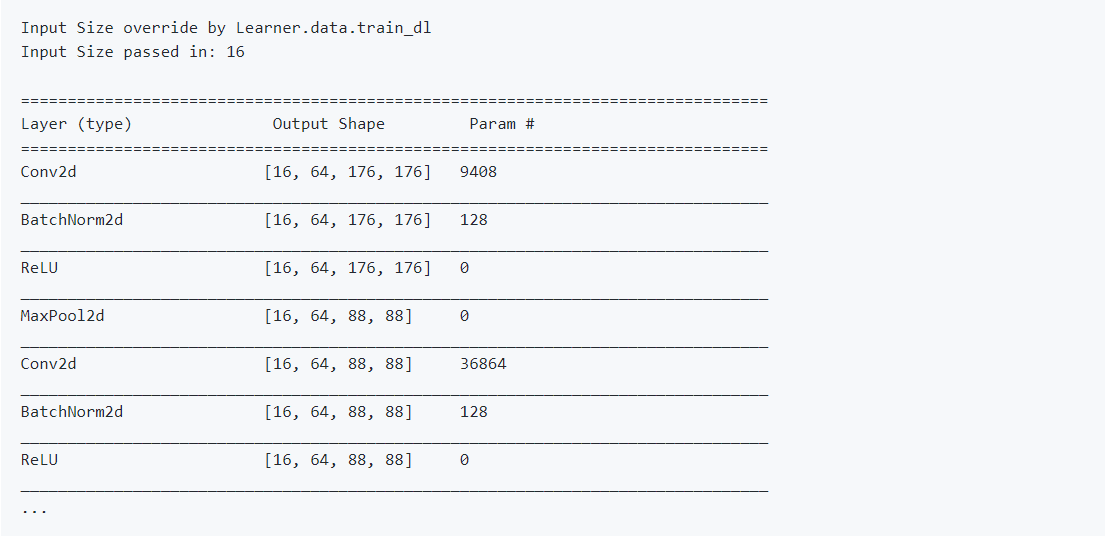

- We start with an input of 3 x 352 x 352
- We then use 64 different kernels against it (each kernel has size 7 x 7 x 3, with stride 2). This gives us an activation of size 64 x 176 x 176
- We then use batchnorm and ReLU
- We then do something called “max pooling” which reduces the size of the activation to 64 x 88 x 88 (I don’t think Jeremy specifically talked about this step in the lecture)
- Now we take the 64 x 88 x 88 activation and use 64 different kernels against it (each kernel has size 3 x 3 x 64, with stride 1). This gives us another activation of size 64 x 88 x 88
- We then use batchnorm and ReLU
- Now, we take the latest 64 x 88 x 88 activation and use 64 different kernels against it (each kernel has size 3 x 3 x 64, with stride 1). This gives us another activation of size 64 x 88 x 88
- We then use batchnorm
- (… and so on)
It took a while for this to “click” for me, but this is how I am understanding it. Let me know if the above explanation helps
3 Likes
@edwardeasling, thank you for the reply. I do understand this. Sorry my question was not clear, the part I don’t understand is that when we change get_data from 224 to 352, what is that doing to the cnn? The learn.summary implies that it is rebuilt with completely different layer sizes all the way down, e.g. the last convolutional layer’s output is an 11x11 in the 352 case and a 7x7 in the 224 case. How then can we carry on training as is done with the sample notebook? Aren’t the weights all set up for a 224x224 => 7x7 cnn? When we do get_data(352,bs) Are the layers of weights rescaled like we would rescale an image to allow this to happen so that the cnn is rebuilt to have larger layers?
As you can see, the number of parameters in each Conv Layer does not change when we change the size of the image( see the image posted by you earlier). Parameters are there in filters not in the images.Here we had kept the filter size same.
1 Like
Oh, thank you and @edwardeasling too. Now i get it! We are training the parameters for the filters. The images are different sizes but the convolutional filters are applied to each ‘pixel’ in the image regardless of the image size. This is why the number of parameters does not change (we have exactly the same number of filters with exactly the same number of parameters in each) but we have different sized images flowing through the network. What was throwing me off was starting with an image and ending with an image (the heatmap) and these were both changing size. I now understand what is going on as the image size does not matter, we are just training the weights in filter kernels. Thanks again.
3 Likes
I’ve got two question regarding summary() function.
-
Whenever I try
summary()I’ve got the first label in output equal1. This is a number of items as I know but is it possible to get a different value. I thought that this depends on batch size, but not, and I cannot getInput Sizeequal16from the example (in the version 1.0.48).
[**1**,64,176,176]. -
How to calculate number of params. For example
Conv2d [16,64,88,88]has36,864. I know that this is because of64*3*64*3, but I don’t know why. I look into model, and source code but I cannot find any clue.
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
Please update your fastai to git master (pip install git+https://github.com/fastai/fastai/) or wait till 1.0.50 is released. The updated summary now remove the first column of the Output Shape, so in lesson6-pets-more.ipynb, print(learn.summary()) now prints:
======================================================================
Layer (type) Output Shape Param # Trainable
======================================================================
Conv2d [64, 176, 176] 9,408 False
______________________________________________________________________
BatchNorm2d [64, 176, 176] 128 True
______________________________________________________________________
ReLU [64, 176, 176] 0 False
______________________________________________________________________
MaxPool2d [64, 88, 88] 0 False
______________________________________________________________________
Conv2d [64, 88, 88] 36,864 False
...
So the bs isn’t there anymore (it was previously incorrectly set to a hardcoded 1), but since it’s not contributing anything useful here and has absolutely no impact on the model it has been removed).
So to answer your question - bs and model params are unrelated. (other than size of bs impacting the total GPU mem requirements and the calculations).
- How to calculate number of params. For example
Conv2d [16,64,88,88]has36,864. I know that this is because of64*3*64*3, but I don’t know why. I look into model, and source code but I cannot find any clue.
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
It’d be different for each type of layer. (note that the examples below use the updated summary output, see above for details)
- In the case of Conv2d multiply the first 4 numbers from the corresponding layer definition:
Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
3*64*7*7 = 9,408
Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
64*64*3*3 = 36,864
======================================================================
Layer (type) Output Shape Param # Trainable
======================================================================
Conv2d [64, 176, 176] 9,408 False
...
Conv2d [64, 88, 88] 36,864 False
- For Linear, first 2 and include the bias if it’s
True:
Linear(in_features=512, out_features=37, bias=True)
(512+1)*37 = 18,981
======================================================================
Layer (type) Output Shape Param # Trainable
======================================================================
Linear [37] 18,981 True
See the new documentation: https://docs.fast.ai/callbacks.hooks.html#model_summary
2 Likes
FYI, I have just added this to the resources of this lesson - an excellent step-by-step tutorial:
Implementing Grad-CAM in PyTorch: https://medium.com/@stepanulyanin/implementing-grad-cam-in-pytorch-ea0937c31e82