This post is for topics related to lesson 5 of the course. This lesson is based partly on chapter 4 and chapter 9 of the book.
This is a wiki post - feel free to edit to add links from the lesson or other useful info.
This post is for topics related to lesson 5 of the course. This lesson is based partly on chapter 4 and chapter 9 of the book.
This is a wiki post - feel free to edit to add links from the lesson or other useful info.
Are missing covering a few concepts, because some of us in the class are beginners?
I noticed two notebooks which Jeremy had kept in wiki of last class was not actually covered
Sorry @kurianbenoy I don’t understand your question. Can you provide some more detail about what you’re asking please?
Two notebooks was not covered in lesson 4, even though it was mentioned in the wiki of lesson4 official topics and found it being mentioned for lesson 5. I was wondering, whether the pace of the class was getting affected in some way?
Probably a good way to rephrase is aren’t we going all good in covering listed learning outcomes?
Ah I see.
I prepare more material than I expect to need each week, in case I go faster than I expect. I don’t want to run out of things to talk about in a lesson! So then I just move the stuff I haven’t done yet to become the start of the next lesson.
Remember, these lessons are all totally new. So I have absolutely no idea what we’ll be able to cover in the 7 weeks we have available. AFAICT UQ requires having “learning outcomes” as part of setting up courses, so frankly I just stuck some generic things in there. I think we’ve covered all of those listed to some extent already!
Hi @kurianbenoy , I have been using this excellent thread to sort of go over the summary of each lecture and the topics that Jeremy went over in that lecture. I feel that the youtube chapter markers actually give an excellent and concise description of topics covered in each lecture. At some point, I intend to curate these items into a separate thread.
Jeremy’s lectures are extremly information dense and sometimes it is quite eyeopening for me to look at these summaries and I realize just how much information Jeremy actually covered in a single lecture.
Thanks for reminding about this. I would also love to help with transcriptions ![]()
I was trying to run the following to visualize a simpe 4 leaf node decision tree and run into this error.
samp_idx = np.random.permutation(len(y))[:500]
dtreeviz(m, xs.iloc[samp_idx], y.iloc[samp_idx], xs.columns, dep_var,
fontname=‘DejaVu Sans’, scale=1.6, label_fontsize=10,
orientation=‘LR’)
it turns out that it could be that your sample is too small to cover all the leaf nodes. so by increasing the size from 500 to 5000 worked to resolve this for me.
Thanks!
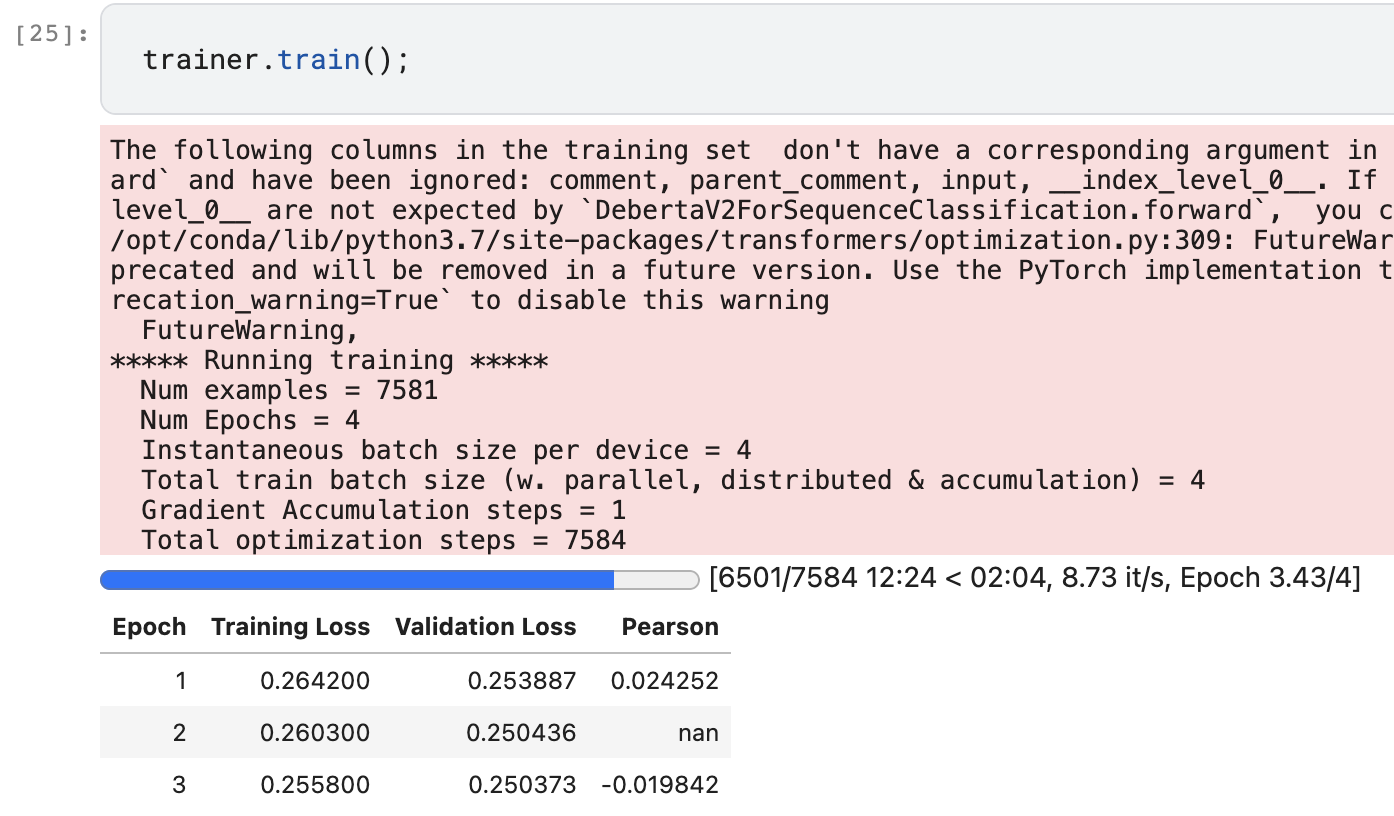
Can anyone could help me with my notebook from the previous lesson? I got stuck with a negative pearson correlation and my post got buried under the last topic post. Wasn’t sure what else I could attempt.
Isn’t substituting by the mode making a big assumption about e.g. Age and Cabin? In your experience, what is the pros and cons of doing this vs. for example discarding Cabin and age from the model?
Is there any extra benefit transforming numeric data to be Gaussian, over simply using the log?
It’s suprising to know that I am knowing there are lot more methods in dataframe describe include other than object
I would be very careful “forcing” data to be gaussian / normal – especially if the data is susceptible to being “non-normal” (like financial data). Know which assumptions you’re making (and violating) when you decide to implement a transform
The literal error the notebook is reporting is running out of space. Is that the real problem?
It did run out of space. However, if you look at the epochs, it’s definitely not converging in any way.
This is a wonderful resource on broadcasting if anyone might be interested ![]()
Well, you had a NaN in the second epoch. This implies a fault. I would review the training data further. I can’t see the whole input in your notebook - it gets cut off. If you cannot find a fault in your data, you can, take a second dataset already prepared and validate your modelling process with that and confirm the model converges. Then you can try to spot any difference in formatting between the datasets.
I didn’t get why Jeremy substracted the random coefficients by 0.5?
The initial random vector values were ranged from zero to 1 - subtracting 0.5 ‘centres’ them around 0 (-0.5 - 0.5)