Thank you for this!
2 Likes
I think the fast. ai people should do this, but I understand where you are coming from
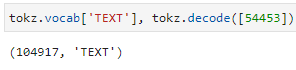
I was playing with some numbers to see which tokens they were in Jeremy’s kaggle notebook.
I found that the same token has multiple numbers for it. Why is this? I would expect the token to has unique numbers.
Eg.
Did this NLP Disaster Tweet Classification project after Lesson 4 of Part 1.
Got a pretty decent score on it - how would you improve it? Seems like throwing a bunch of models together in an ensemble is pretty crude, are there any ways I could have improved the pre-processing? Some further encoding I could have done on the transformer stuff?
I’ve been trying to finetune a language model per chp 10 of the textbook but have hit the following issue
learn = language_model_learner(
dls, AWD_LSTM, drop_mult=0.3,
metrics=[accuracy, Perplexity()]).to_fp16()
is giving me
File /usr/local/lib/python3.9/dist-packages/fastcore/basics.py:496, in GetAttr.__getattr__(self, k)
494 if self._component_attr_filter(k):
495 attr = getattr(self,self._default,None)
--> 496 if attr is not None: return getattr(attr,k)
497 raise AttributeError(k)
File /usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py:1207, in Module.__getattr__(self, name)
1205 if name in modules:
1206 return modules[name]
-> 1207 raise AttributeError("'{}' object has no attribute '{}'".format(
1208 type(self).__name__, name))
AttributeError: 'SequentialRNN' object has no attribute 'to_fp16'
Hello @jeremy , @ilovescience
I got this error under End to End SGD topic while executing the code. How can I fix this?
TypeError: unsupported operand type(s) for ** or pow(): ‘module’ and ‘int’ .
More Details:
def f(t, params):
a,b,c = params
return a*(t**2) + (b*t) + c
def mse(preds, targets): return ((preds-targets)**2).mean()
params = torch.randn(3).requires_grad_()
preds = f(time, params)
TypeError Traceback (most recent call last)
in
----> 1 preds = f(time, params)
in f(t, params)
1 def f(t, params):
2 a,b,c = params
----> 3 return a*(t**2) + (b*t) + c
4
5 def mse(preds, targets): return ((preds-targets)**2).mean()
TypeError: unsupported operand type(s) for ** or pow(): ‘module’ and ‘int’
Hi ksanad,
Unless the site is burning down, please don’t cold-call @notify the site principles. Everyone would love their direct response, but if everyone did this they would have no time for their own work.
I’m sorry I don’t know the answer, but ChatGPT tells me…
1 Like
Hi bencoman,
Thanks for letting me know regarding @notify. I was able to fix the above error by not using **2 on time which is a python module.
Regards
Anand
1 Like
For sure
I noticed this too. Did you finally conclude on what causes the same words to have different outputs despite the only difference being ‘_’ which in my thinking should not matter .
Further reading on in the forum, this particular thread. I have discovered that the model does not look at the token in isolation but also considers the context of the token in relation to other tokens/words. I am thinking this is probably the cause of above behavior.
Does that mean i can use the following
df[‘input’] = ‘TEXT1:’ + df.anchor + ‘; TEXT2: ’ + df.target + ‘; CONTEXT1:’ + df.context
Would this result in the same thing as using df[‘input’] = ‘TEXT1:’ + df.context + ‘; TEXT2: ’ + df.target + ‘; ANC1:’ + df.anchor as used in the original notebook by Jeremy. If not why don’t we use the first statement as the text1 is originally the same text as in the anchor field.
Hi all,
I wanted to confirm my understanding of how DataLoaders create batches for a language model.
In question 17 of the Chapter 10 questionnaire it asks:
Why do we need padding for text classification? Why don’t we need it for language modeling?
I understand the explanation in the book (as well as Tanishq’s solution)—emphasis mine:
The sorting and padding are automatically done by the data block API for us when using a
TextBlock, withis_lm=False. (We don’t have this same issue for language model data, since we concatenate all the documents together first, and then split them into equally sized sections.)
However, what happens if the length of the tokens in the concatenated documents is not divisible by the product of the batch size and sequence length?
Following the first test listed in the docs for LMDataLoader I recreated the following scenario:
The number of tokens (integers) is 14, the batch size is 5 and the sequence length is 2. So, I would think that splitting the 14 tokens into equal sized batches would result in two full batches (5 integers apiece, one for independent and one for dependent variable) and two partially full batches (with 4 integers, again one for independent and one for the dependent variable). And that the partially full batches would be padded. However, it seems like the LMDataLoader gets rid of the last pair of batches.
The following code:
bs,sl = 5, 2
ints = L([[0,1,2,3,4,5,6,7,8,9,10,11,12,13]]).map(tensor)
dl = LMDataLoader(ints, bs=bs, seq_len=sl)
list(dl)
Gives the output:
[(LMTensorText([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]]),
tensor([[ 1, 2],
[ 3, 4],
[ 5, 6],
[ 7, 8],
[ 9, 10]]))]
Given that example, am I understanding correctly that in the book code:
dls_lm = DataBlock(
blocks=TextBlock.from_folder(path, is_lm=True),
get_items=get_imdb,
splitter=RandomSplitter(0.1)
).dataloaders(path, path=path, bs=128, seq_len=80)
The final x and y batches will be dropped if they are not full? And if so, why drop them instead of padding them so they are full batches?
Thanks in advance----apologies if this a duplicate question, I couldn’t find anything related in this thread or through search.
Update: I think this question/response from 2019 is relevant—If there is a different explanation please let me know.:
a lot of models use BatchNorm, which behaves badly if you have a batch of a small size (especially size 1, that will throw an error). To avoid this, we drop the last batch during training (since there is shuffle, it doesn’t have any impact).
In the Chapter 4 notebook and video Jeremy mentions that we can frame the similarity problem as a classification problem
It turns out that this can be represented as a classification problem. How? By representing the question like this:
For the following text…: “TEXT1: abatement; TEXT2: eliminating process” …chose a category of meaning similarity: “Different; Similar; Identical”.
In the above statement there’d be 3 discrete categories/labels: Different | Similar | Identical
But in the code we treat the score column (which can take any float value from 0 to 1) as labels
// score == labels
tok_ds = tok_ds.rename_columns({'score':'labels'})
Question
My expectation is that for classification tasks labels should be a discrete set of values, however in the notebook labels is a continuous value between 0 to 1.
- Is the expectation correct?
- If yes, how does treating score as labels work for this case?
Your expectation is correct that this is a classification problem with discrete categories. However the 3 discrete categories/labels of Different | Similar | Identical is just an example given to illustrate how one would phrase this problem as classification. In the actual dataset, the categories are as follows:

Near the end of the lesson video, one of the students asks a related question to yours and Jeremy explains that in HuggingFace when using AutoModelForSequenceClassification with num_labels=1 (meaning there is one column as the output), it automatically turns it into a regression problem.
In this case, since the metric used in the competition is Pearson coefficient, it works out okay because it’s looking to see how correlated the predictions are to the actual values, so a 0 to 1 range works just fine and a strictly categorical output is not needed.
2 Likes
When I read this part in Chapter 10 of the book:
Going back to our previous example with 6 batches of length 15, if we chose a sequence length of 5, that would mean we first feed the following array:
I have a question:
Why is the sentence order spanned across mini-batches in the language model trained by RNN in this case?
For example, if there are three mini-batches here:
- The first sentence is in the first data row of the first mini-batch. (
xxbos xxmaj in this chapter) - The second sentence is in the first data row of the second mini-batch (why isn’t it in the second data point of the first mini-batch?). (
, we will go back) - The third sentence is in the first data row of the third mini-batch. (
over the example of classifying) - The fourth sentence is in the second data row of the first mini-batch. (
movie reviews we studied in) - etc…
The crucial point I don’t understand may be: in the case of parallelization using mini-batches in RNN, which segment of the mini-batch corresponds to adjacent training in terms of RNN training?
2 Likes
Good question! It’s something I was thinking about too.
I guess the parallelization is carried out on the sequences or on rows, so to speak, of the mini-batches. That is, at a time, the first sequence (first row) of each mini-batch in a batch is used for training.
I don’t know if my answer is entirely accurate, but it does make sense for me. Do let me know your thoughts ![]()
Hi everyone,
I am going through chapter 4 of the book and am stumbling over a very fundamental (probably stupid) question. Maybe anybody can share his/her intuition on the subject.
If I look at the linear model that is used for the 3’s and 7’s example
def linear1(xb): return xb@weights + bias
preds = linear1(train_x)
it is stated that to decide if an output represents a 3 or a 7, we can just check whether the functions output it’s greater than 0.0.
Why is this the case?
Thanks!
P.S.:
There is one place in chapter 4 that checks for preds > 0.5:
def batch_accuracy(xb, yb):
preds = xb.sigmoid()
correct = (preds>0.5) == yb
return correct.float().mean()
This looks like a typo as the preceding paragraph was fixed in the latest version of the book to read
“We also want to check how we’re doing, by looking at the accuracy of the validation set. To decide if an output represents a 3 or a 7, we can just check whether it’s greater than 0. So our accuracy for each item can be calculated (using broadcasting, so no loops!) with:”
Whereas in my hardcopy, it reads “whether it’s greater than 0.5”.
This forum post has a good explanation for this. In short, the predictions coming out of linear1(train_x) are centered around 0 with both negative and positive values, so 0 is a good threshold for the binary classification. Later on, once predictions are passed through sigmoid, the threshold is then 0.5.
1 Like
Thank you for your answer. I have to say, though, that I am still not 100% convinced. I totally understand that the midpoint for the weights is 0 after using torch.randn and that by multiplying these values with the image data where each pixel is a value between 0 and 1 this distribution remains the same. I also understand how this changes to 0.5 after the sigmoid function is applied. But that still doesn’t explain why at the end, once the model has been trained and the weights look completely different, this distribution is still present like that.
Let me ask differently then: How come that the model produces values > 0 in case of a 3 and < 0 in case of a 7? If we knew that, the accuracy would come naturally the way it is defined.
Thanks for helping understand this better!
1 Like
Great question, it’s helping me think more thoroughly about my understanding of what’s going on.
I’ll try and answer your question—I think that’s where the loss function comes into play:
def mnist_loss(predictions, targets):
predictions = predictions.sigmoid()
return torch.where(targets==1, 1-predictions, predictions).mean()
By minimizing the loss, which is 1-predictions for when the target is 1 (the digit 3) and predictions when the target is 0 (the digit 7), the model learns to make predictions that are large and positive for when the digit is 3 (large positive values get closer to 1.0 after being passed through sigmoid) and large and negative for when the digit is 7 (large negative values get closer to 0.0 after being passed through sigmoid).
2 Likes