what does the Pearson column represent when we’re training the model? I understand that 2 phrases can be correlated, and that they’ll have a Pearson correlation coeff., but what does it mean for the whole epoch to be correlated? Is the number reported just the average Pearson correlation coeff?
bumping this
Bump back!
I don’t know the answer, but I’ll take the time to assist with some pointers why response may be lacking. You don’t:
- provide context for your question
- provide the actual output you are looking at
- provide the actual code you are running, condensed to the minimum required to generate that output
- describe what you’ve learnt from independent research in the past two days
Please see “Before You Ask” and “Be explicit about your question” here…
How To Ask Questions The Smart Way
1 Like
what does the Pearson column represent when we’re training the model? I understand that 2 phrases can be correlated, and that they’ll have a Pearson correlation coeff., but what does it mean for the whole epoch to be correlated? Is the number reported just the average Pearson correlation coeff?
As far as I’m concerned it’s not the correlation between 2 phrases. Instead, it’s the correlation between our predictions and the true labels.
Remember that the metrics are always computed on the validation set, so after each epoch (doing a forward pass, backward pass and stepping of the weights on the training set), we run a forward pass on the validation set and get predictions, let’s say our prediction is 0.31. For each sample we also have the true label/score which is either 0, 0.25, 0.5, 0.75 or 1.
For example: [prediction, label] = [0.31, 0.25]
For each batch we thus have a matrix of size (batch_size, 2).
On each batch we compute the correlation between these 2 columns.
For each epoch we probably average the correlation we computed on each batch.
What is the difference between passing a string to
tokzas an argument and passing a string to thetokenizemethod of thetokz?
the tokz is indeed a Tokenizer object. Tokenizer objects have certain methods, and they can also be called themselves.
So we can do for example
# Just tokenize
tokz.tokenize("Hello, my name is Lucas")
> ['▁Hello', ',', '▁my', '▁name', '▁is', '▁Lucas']
# Tokenize + numericalise
tokz.encode("Hello, my name is Lucas")
> [1, 5365, 261, 312, 601, 269, 10876, 2]
# Tokeniz + numericalse in 2 separate steps
tokz.convert_tokens_to_ids(tokz.tokenize("Hello, my name is Lucas"))
> [1, 5365, 261, 312, 601, 269, 10876, 2]
# Now call tokz directly:
tokz("Hello, my name is Lucas")
> {'input_ids': [1, 5365, 261, 312, 601, 269, 10876, 2], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
As you can see calling tokz directly is creating a dict with a couple of fields, one of which is the encoding of the input (input_ids) and 2 others, I am not entirely sure what they are to be honest nor whether they are being used by the model.
2 Likes
Quick question on the transformers library. From autocompleting
from transformers import AutoModelFor<TAB>
it seems there are a lot of problems that can be build with the transformers library besides the AutoModelForSequenceClassification one we are using here.
How do we know which models from Models - Hugging Face can be used with which kind of AutoModelFor..
Has anyone tried changing the default fastai tokenizer to use a subwords tokenizer instead of a word tokenizer like Spacy? If you have, where did you fit it in the ULMFit process?
I was also curious about using the subwords tokenizer. I may experiment with it later. Since you posted this, have you gained any insight?
It took me an hour to figure this out, but the underscore used in the Kaggle notebook is not actually an underscore. It’s a character called a “lower one eight block” or unicode 2581. The author has used this in the notebook and it is also the character used by SentencePiece when tokenizing your text as a prefix for keys in the dictionary that have spaces before them.
From this page: GitHub - google/sentencepiece: Unsupervised text tokenizer for Neural Network-based text generation.
SentencePiece treats the input text just as a sequence of Unicode characters. Whitespace is also handled as a normal symbol. To handle the whitespace as a basic token explicitly, SentencePiece first escapes the whitespace with a meta symbol “▁” (U+2581) as follows.
What this results in is students trying the code on their own laptops, manually entering the line
tokz.vocab[‘_of’]
and getting very confused when they get a key error on their local machine.
Here are the two underscores next to each other for comparison: ▁_
So if you check if a key exists, you can’t just use an underscore in your source code, you have to use the same unicode character or some other technique to get at it.
I think commenting that particular line will really help future learners who want to run the code locally to avoid confusion.
Thanks for an awesome educational experience otherwise!! fast.ai absolutely rocks!
Mark.
6 Likes
I want to make sure its my understanding correct or not.
As competition’s evaluation is asked to use “submissions are evaluated on the Pearson correlation coefficient between the predicted and actual similarity scores .” We must use this metrics.
If when we don’t need to follow this rules, likes in real world problems, we can use whaterver metrics we want, is that correct?
In the output of training process we see Training Loss and Validation Loss as outputs, can we simply use these loss values as evaluation of our models without using metrics like Pearson_correlation_coefficient?
Hello!
Yes, you are correct. You can use any metric you want to evaluate the model. The metric provided by Kaggle is just used to rank the participants. You can use the loss for evaluating the performance of the model but you should understand the difference between a metric and a loss function. The loss function is what the model is being optimized on but a metric is just used for us to evaluate the model and has nothing to do with the optimization process. Sometimes the loss might change but a metric like accuracy might still remain the same. The reason for this is that while the weights might have improved but they might not have improved significantly enough for the model to change its prediction so the metric remains the same. So it might be good to use a metric other than the loss function to evaluate the model’s performance properly.
Hope this helps ![]()
Thanks you very much, you explained very clearly, making my understanding better on difference between loss function and metric.
1 Like
hi jeremy , i just finished with the lecture - 4 , after finishing the video i thought about applying fast.ai lib for the us patent question instead of hugging faces , but i’m facing issues , like how to load a pre trained model like the deberta v3 through fast.ai , can you give me some tips and how to proceed with using the fast.ai lib from NLP?
Also can you recommend a source where all the function names and all the functionality which fast.ai is named and given
Hi everyone! I am just curious about how I can get a list of a few pre-trained NLP tasks optimized models.
In Chapter 3, we learned how to use timm library to get a list of state-of-the-art pre-trained computer vision models. (notebook:Which image models are best?).
Is there a timm equivalent library for NLP models?
What is the best way to get the list of state-of-the-art pre-trained NLP models?
I would like to play around with different NLP models on top of the microsoft/deberat-v3-small model in our chapter 4 notebook (Getting started with NLP for absolute beginners).
I see a similar question that is asked before in this forum, and it sounds like manually checking the evaluation results of the models on hugging face is a way…?
If anyone has their own way of getting a list of a few NLP models, I would greatly appreciate if you can share your tactics so I can learn and apply to my own learning ![]()
Thanks for asking the question a year ago @marix1120 ![]() I literally hit the same issue and was curious how to unblock myself from the issue. I am glad I came to the forum pretty quickly!
I literally hit the same issue and was curious how to unblock myself from the issue. I am glad I came to the forum pretty quickly!
The Hugging Face Models gives a selection of pretrained models to use. Everything from CV, NLP & Multimodal stuff.
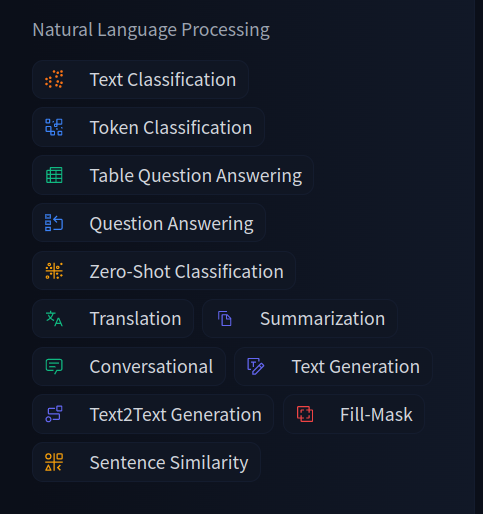
Look for the NLP section and select the use case you want then the models will appear on the right.

I guess the number of downloads and hearts tells you how popular the models are. ![]()
1 Like
Thank you for investing your time and sharing this awesome tip, @PatTheAtak!
On my way of playing with different models from hugging face ![]()
Hey team, I am experimenting with fine-tuning a different NLP model.
I am following the exact same code from Jeremy’s notebook (Getting started with NLP for absolute beginners | Kaggle), except using a different model name.
Jeremy’s notebook: using microsoft/deberta-v3-small.

My experiment: using distilbert-base-uncased-finetuned-sst-2-english by following instructions from here.

But whenever I call trainer.train(), I do get an error message indicating the shapes of input arrays aren’t the same.
Full Error Message:
“ValueError: all the input array dimensions for the concatenation axis must match exactly, but along dimension 1, the array at index 0 has size 1 and the array at index 1 has size 9119”
Error Screenshot:
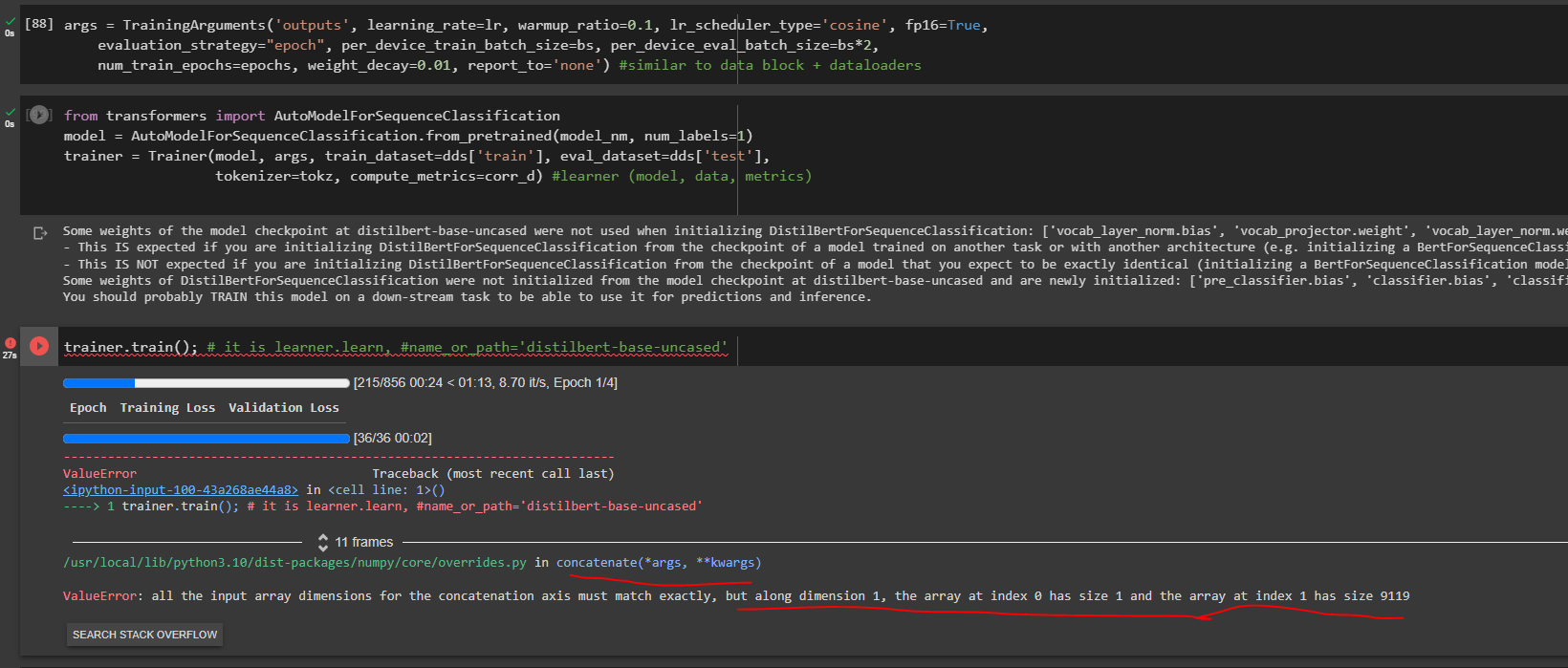
I am not quite sure which arrays have different dimensions in this case. I suspect some model configs, argument configs might need to be updated for a different model as the same configs worked for microsoft/deberta-v3-small.
I saw a similar question from the forum (Lesson 4, multi-label classification ). It did not have a solution but had a good starting point to understand the issue which is the hugging face tutorials about Transformers.
While I am learning about how to use Transformers to finetune different models correctly, has anyone encountered a similar issue before or knows some other points I can unblock myself? Any insights/ideas would be greatly appreciated ![]()
This is the link to my colab that contains all e2e code:
Hi all. I have a question on lesson 4 - maybe a dumb question (kindly bear with me!). When @jeremy uses the HuggingFace tokeniser, the result produces the tokenised output. In that, there is also an attention mask.

On examining the mask, it has 0s and 1s.
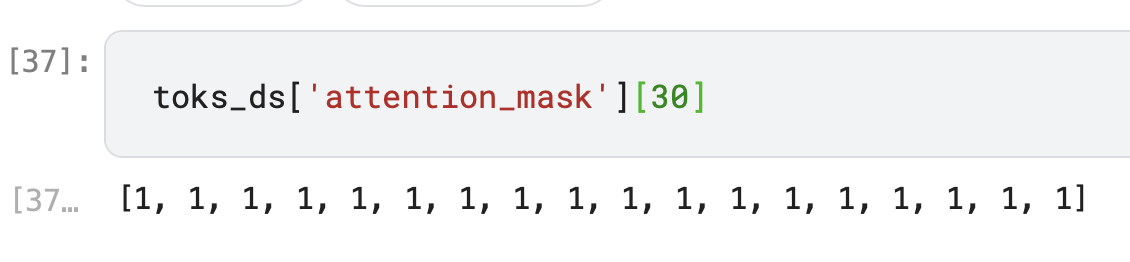
My question, what is this attention mask? How it is derived? How does it help with the classification task?
Any resources/help pointing me in the right direction would be appreciated. Thanks all !!
Hi,
I don’t know why it does not work either. But I think reading the hugging face NLP tutorial or transformers tutorial might be helpful.
1 Like
Hi,
Attention_mask has 1s and 0s to indicate whether the word should be focused (1) or not (0). This is used because sentences have different lengths. If the sentence is shorter than others, it will have trailing 0s at the end to tell the model to ignore those white spaces. If you want to learn more about it, you can read this entry from Hugging face NLP course.
If it doesn’t make sense, you can skip this detail and come back to it later. The rest of the course does not assume you know these details.
Thanks for the pointers, @galopy!
1 Like