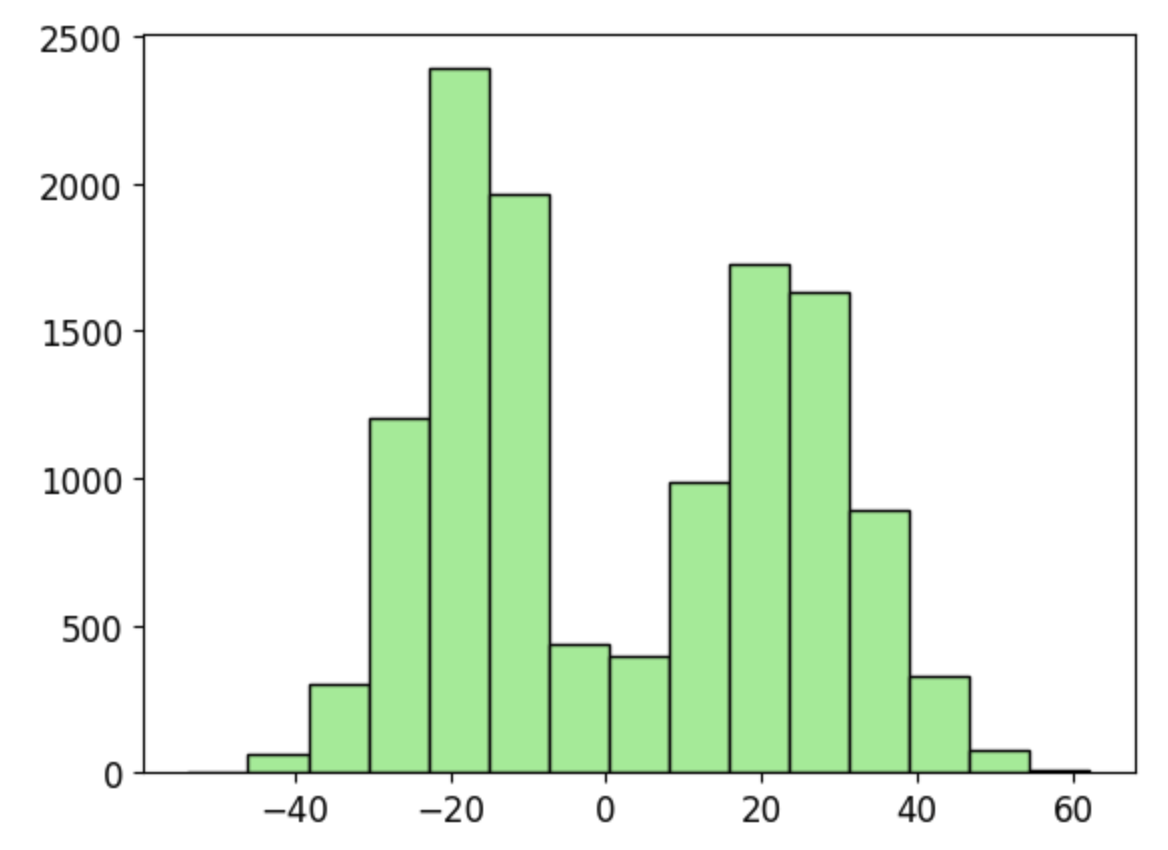
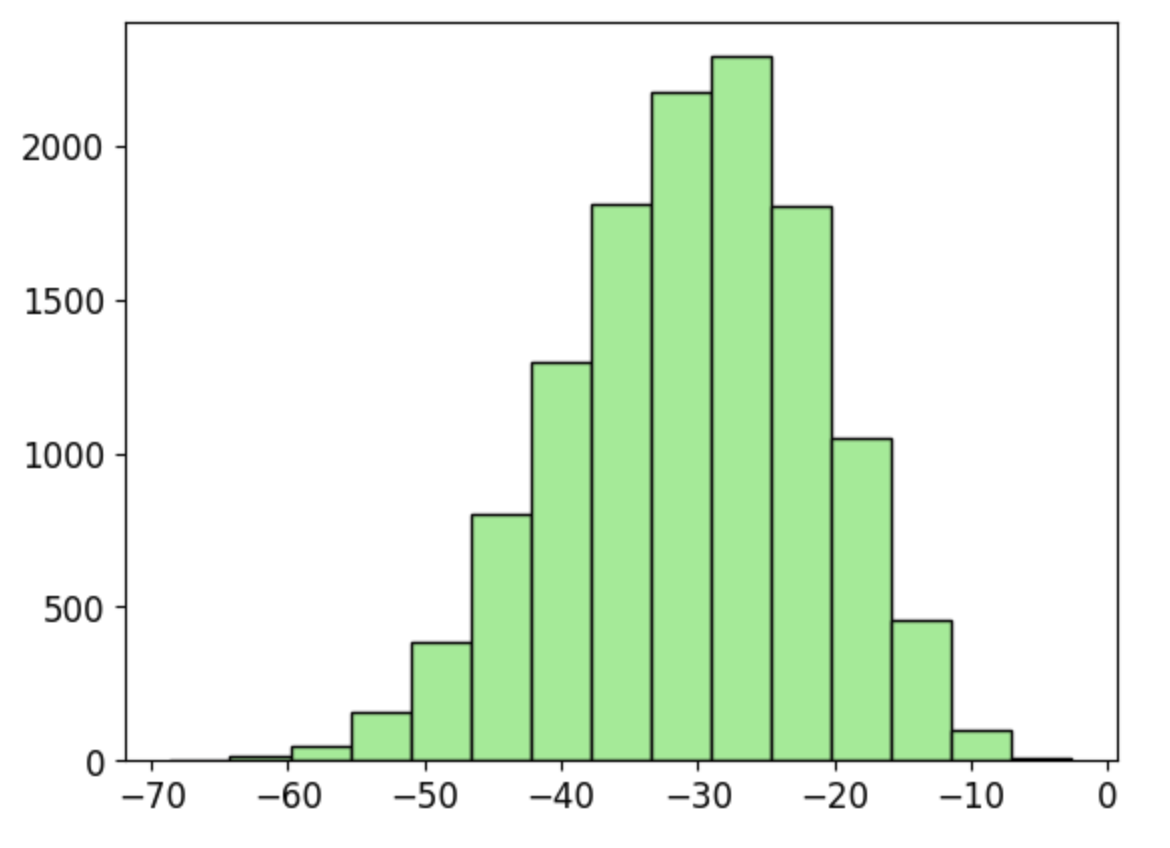
If I now tweak the loss function to something else (complete nonsense, of course!)
def mnist_loss(predictions, targets):
predictions = predictions.sigmoid()
# mind the change of the second argument from 1-predictions to 1+predictions
return torch.where(targets==1, 1+predictions, predictions).mean()
This is in the lesson 4 notebook. This is probably a Python newbie question - definitely a pandas newbie question, but, I’m trying to fundamentally understand how pandas modifies all records in this assignment and adds a new column:
With what looks like a single concatenated string assignment, pandas has created a new column for all rows and modified the column according to the logic in the string concatenation. I’m coming to Python from other languages, so is this a pythonic thing? Or has pandas overridden object property assignment and they’re using the expression as a shortcut to modify all rows? In another language you’d just end up with df[‘input’] as a property with a single string value - or it might throw an error because e.g. df.context isn’t a variable that can be concatenated.
I’ve had a look at the pandas docs and no luck, poked around regarding python overriding assignment operators and found that it is possible to do this for object properties but didn’t immediately see that in Pandas or an explanation of how it works. Just need a pointer on what to look up to understand this behavior.
At the core of the NumPy package, is the ndarray object. This encapsulates n-dimensional arrays of homogeneous data types, with many operations being performed in compiled code for performance.
NumPy has the ufunc (universal function) which is:
a function that operates on ndarrays in an element-by-element fashion, supporting array broadcasting, type casting, and several other standard features. That is, a ufunc is a “vectorized” wrapper for a function that takes a fixed number of specific inputs and produces a fixed number of specific outputs.
As an example, here is the source code for the add method for character arrays, which returns the numpy.add function which is a ufunc. I can’t spell out exactly how this translates to the line of code you are referencing, but conceptually it’s related.
Here is NumPy’s description of broadcasting which comes up a lot when working with pandas (and also PyTorch). The single strings 'TEXT1: ', 'TEXT2: ' and 'TEXT3: ' are “broadcasted” to all elements in the columns df.context, df.target and df.anchor when they are concatenated with the + operator.
I have a question regarding the MNIST deep learning model that was built in Chapter 4. As I understand it, our intent was to classify the input into on of two categories, threes and sevens, why then did we decide to use a linear model for that purpose? Personally, the first idea that came to my mind was a classification model such as logistic regression.
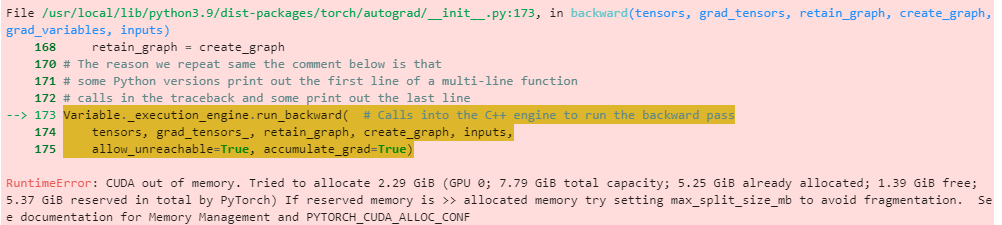
I attempted to run the chapter 10 notebook on Paperspace using one of the free machine configurations including GPU. It failed on the model tuning step, complaining about running out of GPU memory:
My question isn’t primarily about the advice the error text provided (although I would not turn down advice on the advice), but about the claim that PyTorch reserved 5.37 GiB of the 7.79 GiB GPU memory capacity. Is that usual, and if so, doesn’t that define a floor on GPU requirements that makes free resources not so useful?
I had this half baked idea after seeing a news piece on bitcoin. Could NLP help to identify Satoshi Nakamoto, the author of the original bitcoin whitepaper? Satoshi Nakamoto is a pseudonym, the real identify of the author remains a mystery.
Could NLP help identify the author’s real name? A couple half baked approaches:
Use the Abstract as the known, author as unknown, Journal of Cryptography up to the publication date of the paper as the data set. The test dataset is just the single bitcoin paper. This relies on the assumption that the author has published in Journal of Cryptography previous to the bitcoin paper, and abstracts being unique enough to different authors. Multiple authors on a paper would be a sticky point, treat them as one author/token in the vocabulary? Use ULMfit due to the size/number of taokens required for abstracts. Getting all of the abstracts and authors quickly and easily is another sticky spot - does the Journal of Cryptography offer an API?
Or, use the authors in References as the known, paper author as unknown, again using the J Cryptography. This has the assumption that researchers tend to reference certain other researchers more frequently. And the same challenge here of getting all authors and the References.
No such file or directory: ‘/root/.fastai/data/imdb/models/finetuned.pth’
I’m not sure if this line: learn.save_encoder(‘finetuned’)
is working properly, because later in the notebook this line: learn = learn.load_encoder(‘finetuned’)
throws the error shown above.
Does anyone have an idea of what is going on, where my mistake may be?
Thanks,
Chris
Hi all, this is a silly question but I’ve not been able to resolve it on my own. How do I save/load the encoder while in Kaggle?
I am trying out the ULM fit method on a dataset using Kaggle, and I’m having issues saving and loading the finetuned encoder in Kaggle. I’m quite certain it’s a directory issue due to the fact that the error shows it’s trying to pull from fastai’s data location. I tried to set my model directory to kaggle/working using the below code.
hi guys i’m having trouble with this part of notebook 4:
#id gradient_descent #caption The gradient descent process #alt Graph showing the steps for Gradient Descent
gv(‘’’
init->predict->loss->gradient->step->stop
step->predict[label=repeat]
‘’')
it returns:
TypeError Traceback (most recent call last)
Cell In[110], line 4
1 #id gradient_descent
2 #caption The gradient descent process
3 #alt Graph showing the steps for Gradient Descent
----> 4 gv(‘’’
5 init->predict->loss->gradient->step->stop
6 step->predict[label=repeat]
7 ‘’')
TypeError: ‘module’ object is not callable
i’ve already done “import graphviz as gv” but it still doesn’t work, any advice? thanks
Hi all, I am having trouble running the notebook getting-started-with-nlp-for-absolute-beginners on my macbook pro m3 chip.
The issue occurred while running this line:
model = AutoModelForSequenceClassification.from_pretrained(model_nm, num_labels=1)
The error:
22:15:02.023 [error] Disposing session as kernel process died ExitCode: undefined, Reason: huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks…
To disable this warning, you can either:
Avoid using tokenizers before the fork if possible
Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks…
I tried to set the TOKENIZERS_PARALLELISM to false, but it didn’t work. Any advice? Thanks
Just leaving here a piece of advise in case somebody stumbles on the issue with model downloading.
When working with the 10_nlp.ipnb page (created my copy), I wanted to download the 1epoch.pth model to either continue building from it (because in Colab my prev job took too long and got disconnected) or play around with it locally.
Turned out, while I can see the file in the /root/.fast/data/imdb/models/ directory, the download fails with a long error starting with Could not fetch resource at https://colab.research.google.com/tun/m/gpu-l4-s-z8hwjs0n7ouh/files/root/.fastai/data/imdb/models/1epoch.pth?authuser=0: 500 .
The solution is:
Mount GDrive using an icon above or just insert this cell and run it:
from google.colab import drive
drive.mount('/content/drive')
After it run this line learn.path = Path('/content/drive/MyDrive')
The you can run learn.save('1epoch'), for example
The learner will create a directory models under MyDrive and will put the file there.
Note, directory creation takes a second or two, and file appears just a bit longer. So refresh a couple of times.
Note, Colab’s download is weird - you won’t see file download dialog any time soon: first, there’s a small circles to the right of the file with a blue circumference slowly appearing - it is preparing the file for download. So you’ll need to wait for it to finish that process before the actual download starts
Really grateful for this course and the info in these forums. A couple of simple questions on Getting started with NLP for absolute beginners. Apologies, I couldn’t find answers to these so I guess I am missing something obvious:
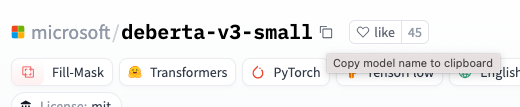
With the following code how does the notebook know to access the deberta model in hugging face transformers?
model_nm = 'microsoft/deberta-v3-small'
Similar to first question. There is no prior install code for transformers so how does the notebook know where to find the modules?
from transformers import AutoModelForSequenceClassification,AutoTokenizer
The model_nm (model name) variable is later on passed to the AutoTokenizer.from_pretrained and AutoModelForSequenceClassification.from_pretrained HuggingFace methods.
tokz = AutoTokenizer.from_pretrained(model_nm)
model = AutoModelForSequenceClassification.from_pretrained(model_nm, num_labels=1)
In general, if you go to the model card on HuggingFace Hub you can copy the model name for use in the .from_pretrained method (which will download the pretrained weights).
Jeremy’s notebook is on Kaggle and the transformers library is one of the already installed libraries on Kaggle by default. For example, you can just import transformers on Kaggle without installing it because it’s already installed: