I’m trying to follow the camvid example except with the ade20k dataset. When running
lr_find(learn)
I get the error saying one of my dimensions is 342 instead of 341
invalid argument 0: Sizes of tensors must match except in dimension 1. Got 341 and 342 in dimension 3 at /pytorch/aten/src/THC/generic/THCTensorMath.cu:71
This is confusing since I’m sizing using something like this, which I assumed should work out of the box.
data = (src.transform(get_transforms(), size=size, tfm_y=True)
.databunch(bs=bs)
.normalize(imagenet_stats))
But, since it did not, I wrote a couple test loops to look for shapes that did not match for both train_ds and valid_ds
index = 0
for a,b in data.train_ds:
a1, a2, a3 = a.shape
b1, b2, b3 = b.shape
if a3 != 341:
print(f'{a3} {b3}')
elif b3 != 341:
print(f'{a3} {b3}')
else:
print(f'none {index}')
index += 1
and everything is 341 . I’m clearly not understanding something. Maybe if the learner told me which index was causing the problem?
Anyways if anyone can help, it would be much much appreciated!
Heya, I have one question about transform. When we apply transform to the planet data - changing the size in this case, I am assuming (from reading the source code in https://github.com/fastai/fastai/blob/master/fastai/data_block.py#L498) that the transform is applied to both training and validation - please do correct me if this is not correct.
In the absence of test set and since we base our evaluation performance based on validation set, shouldn’t we restrict transform to training set only?
I’m having a CUDA out of memory issue. I have restarted the instance and killed the kernal an reopened the notebook with no success. Each time I have tried to recreate the learner and then load my resnet-stage-2 model to continue training the gpu runs out of memory.
If I don’t load my old model I can’t continue to train it, am I correct?
If the learning rate curve doesn’t follow that initial down-slope followed by an up-slope does that indicate an issue? It also might be my plotting settings as I don’t seem to plot the curve to x=1e-01.
I have problem understanding how changing the input size of the image doesnt affect the inputs/outputs of the network. Changing the input size in a convolutional layer should definitely change the output right? How can i use transfer learning with a bigger image size then, i just dont get it.
Even I was having the same doubt. The architecture, I guess, does change. Please anyone correct me if I am wrong!
I searched over net for transfer learning with different sizes and it led me to this blog post from Adrian Rosebrock which confirms the change in architecture.
I also came across this thread from the forum where Jeremy says that fastai automatically handles it and later in the same thread mentions about having used adaptive pooling to do so.
I am still new to course (and the techniques), digging through the excellent fastai library to find where and how exactly this is handled. Any pointers will be useful though!
I am having trouble with visualizing where the Kaggle data for the planet Amazon exercise exists on my instance using Salamander. From the previous example, I can navigate using Jupyter Notebooks to see the images of bears/teddy bears. But I cannot see the same for the planets example. What am I missing?
Hi, I’m trying to run the planets notebook, and I’m getting a memory error when trying to find the learning rate. I tried reducing the batch size to 32 by running data = (src.transform(tfms, size=256).databunch(bs=32).normalize(imagenet_stats)), but that didn’t work, so I also tried batch sizes of 16, 4, 2, and 1, always getting the same memory error. I’ve searched the forum and found others on this thread having the same problem, but changing the batch size seemed to work for them.
Am I changing the batch size incorrectly, or is there something else I should try?
If train loss > valid loss = underfit and train loss < valid loss = overfit is true,
does this mean a good model should have similar levels of training loss and validation loss?
Another thing that bothers me is the way he uses the learning rate. In some videos, he uses two different numbers for the same type of learning plot. Lesson(1) - slice(1e-3, 1e-5) and Lesson(2) - slice(3e-3, 3e-5).
If you’re already familiar with scientific notation, you might be used to seeing it notated as something times 10 to a power, and this notation using e is actually equivalent. The ‘e’ represents “10 to the power of,” not the number e! https://en.wikipedia.org/wiki/Scientific_notation#E-notation
So 1e-3 == 1 * 10^(-3) == 0.001. If the number in the decimal place needs to be something other than 1, you’ll use that number. For instance, if you needed to express 0.05 in this notation, you’d have 5e-2, i.e. “5 times 10 to the power of -2”.
That is very helpful. Thank you Laura Also the links are amazing. Now I understand that choosing the learning rate is not only dependent on the LR plot but also to do with the intuition and experience gained from running many different models and datasets.

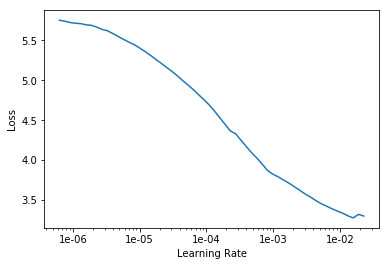

 Also the links are amazing. Now I understand that choosing the learning rate is not only dependent on the LR plot but also to do with the intuition and experience gained from running many different models and datasets.
Also the links are amazing. Now I understand that choosing the learning rate is not only dependent on the LR plot but also to do with the intuition and experience gained from running many different models and datasets.